컬렉션(collection)
•
여러 객체(데이터)를 모아 놓은 것을 의미
프레임워크(framework)
•
표준화, 정형화된 체계적인 프로그래밍 방식
•
라이브러리(기능) + 프로그래밍 방식
컬렉션 프레임워크(colletions framework)
•
컬렉션(다수의 객체)을 다루기 위한 표준화된 프로그래밍 방식
•
컬렉션을 쉽고 편리하게 다룰 수 있는(저장, 삭제, 검색, 정렬) 다양한 클래스를 제공
•
java.util 패키지에 포함. (jdk1.2부터)
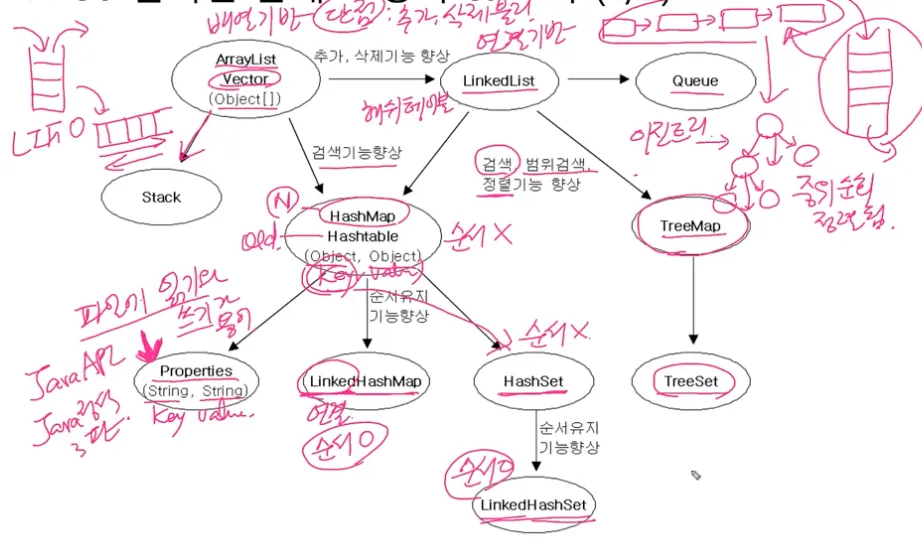
컬렉션 클래스(collection class)
•
컬렉션 프레임워크에서 제공하는 다양한 클래스
•
다수의 데이터를 저장할 수 있는 클래스 (ex. Vector, ArrayList, HashSet)
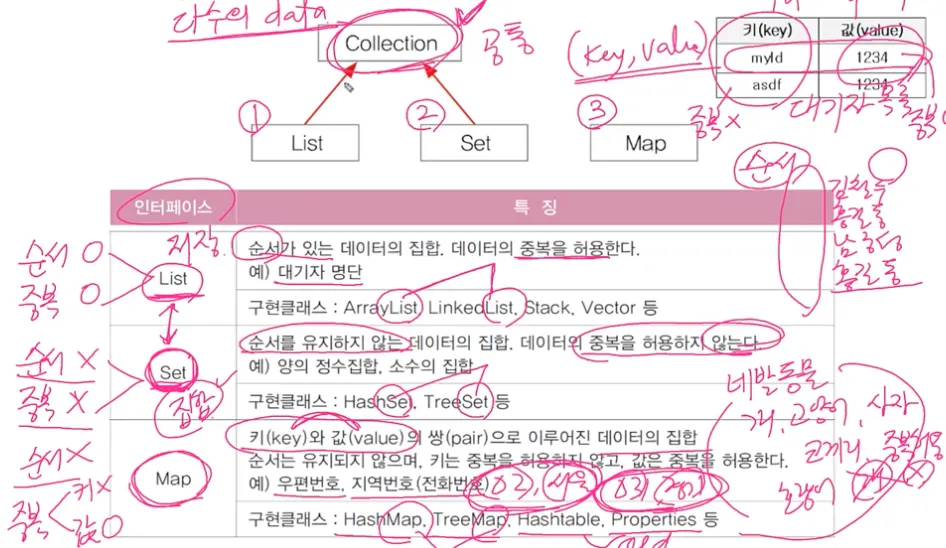
컬렉션 프레임워크의 핵심 인터페이스
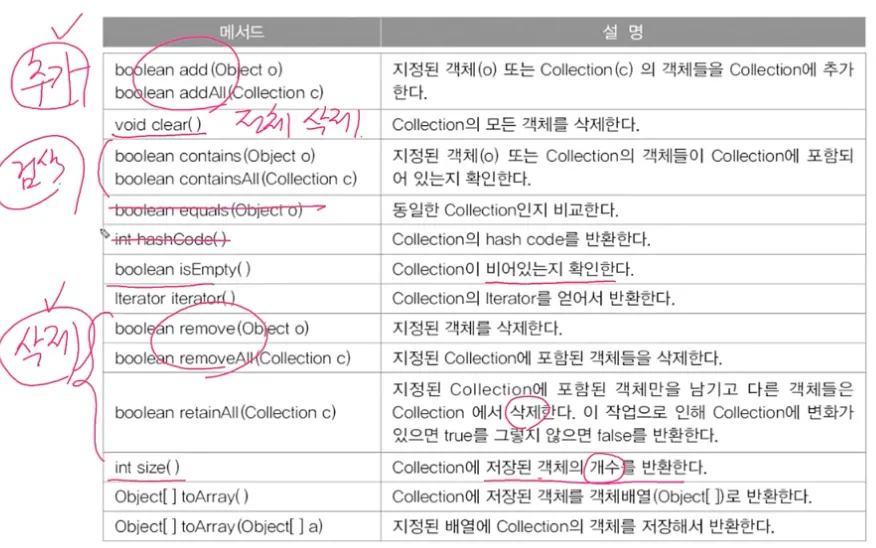
Collection 인터페이스의 메서드
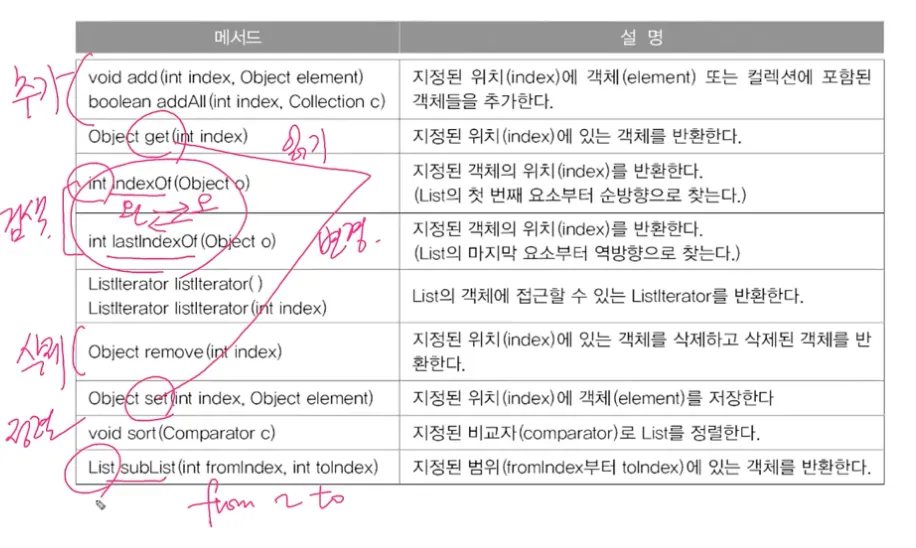
List 인터페이스 - 순서 O, 중복 O
•
ArrayList (=Vector), LinkedList
Set 인터페이스 - 순서 X, 중복 X
•
HashSet, TreeSet, SortedSet
•
Collection 인터페이스의 메서드와 동일.
•
추가로 집합과 관련된 메서드를 갖고 있음 (Collection에 변화가 있으면 true, 아니면 false)

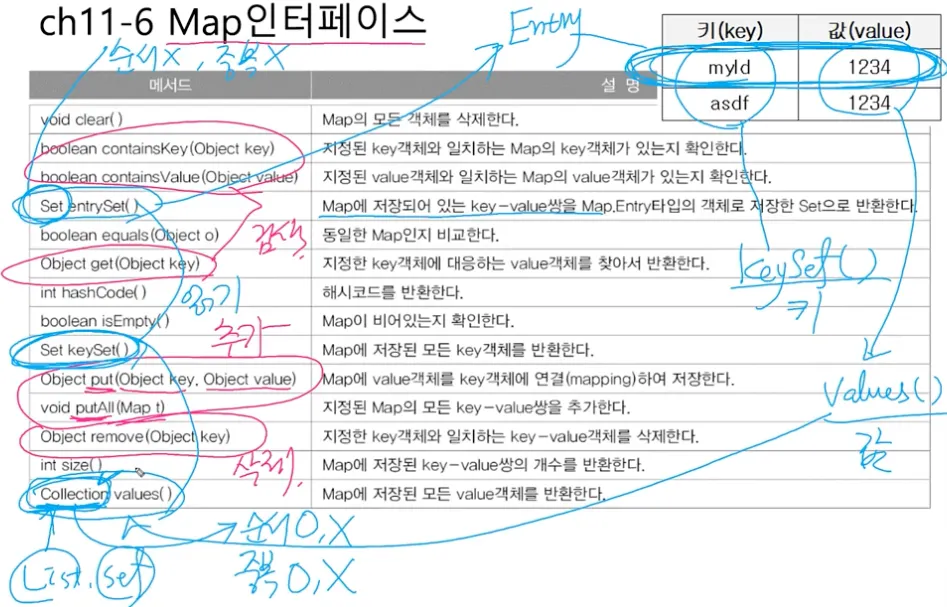
Map 인터페이스 - 순서X, 중복(키X, 값O)
•
HashMap(=Hashtable), TreeMap, SortedMap, LinkedHashMap
ArrayList
•
ArrayList는 기존의 Vector를 개선한 것으로 구현원리와 기능적으로 동일
•
ArrayList와 달리 Vector는 자체적으로 동기화처리가 되어 있다
•
List인터페이스를 구현하므로 저장순서가 유지되고 중복을 허용한다
•
데이터 저장공간을 배열을 사용한다 (배열기반)
•
Obejct[] 이므로 객체만 저장 가능하다.

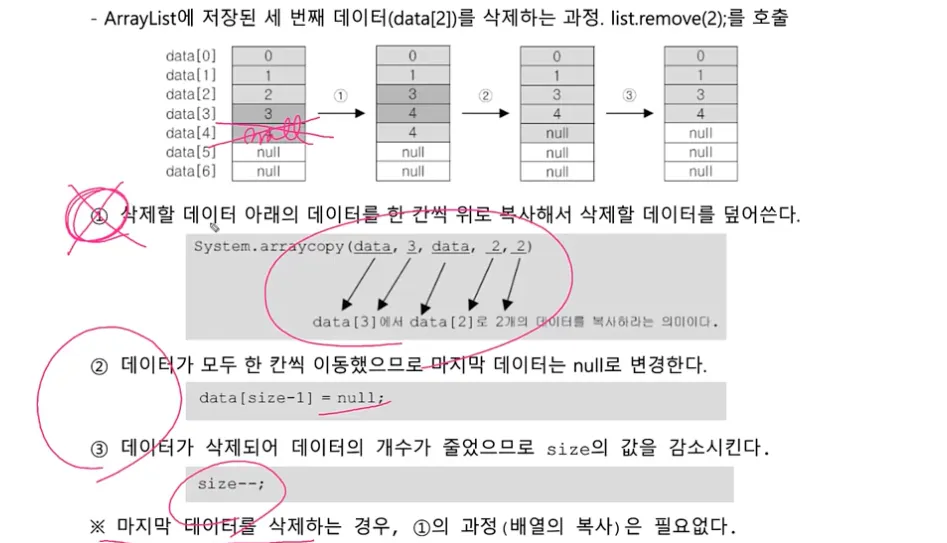
ArrayList에 저장된 객체의 삭제과정
•
1번 단계에서 부담이 많이 된다
•
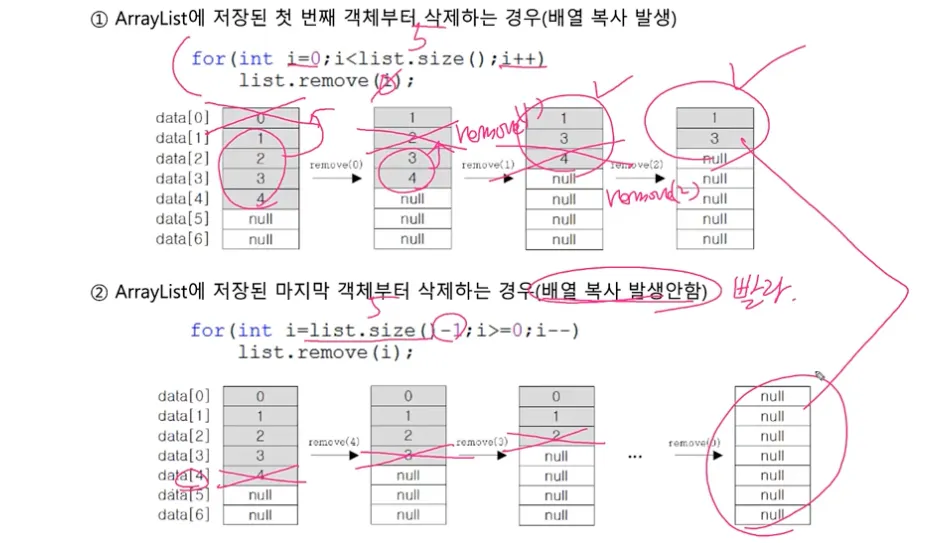
앞에서부터 지우면 다 안 지워지고 느리다! 뒤에서부터!
ArrayList 배열의 장단점
•
장점
◦
배열은 구조가 간단하고 데이터를 읽는데 걸리는 시간(접근시간)이 짧다
•
단점
◦
크기를 변경할 수 없다 (새로운 배열 생성 후 데이터 복사해야함)
배열에서 남는 공간만큼 메모리 낭비
◦
비순차적인 데이터 추가, 삭제에 시간이 많이 걸린다 (다른 데이터를 옮겨가며 수행)
순차적인 데이터 추가(끝부분)와 삭제(끝부분)은 빠르다
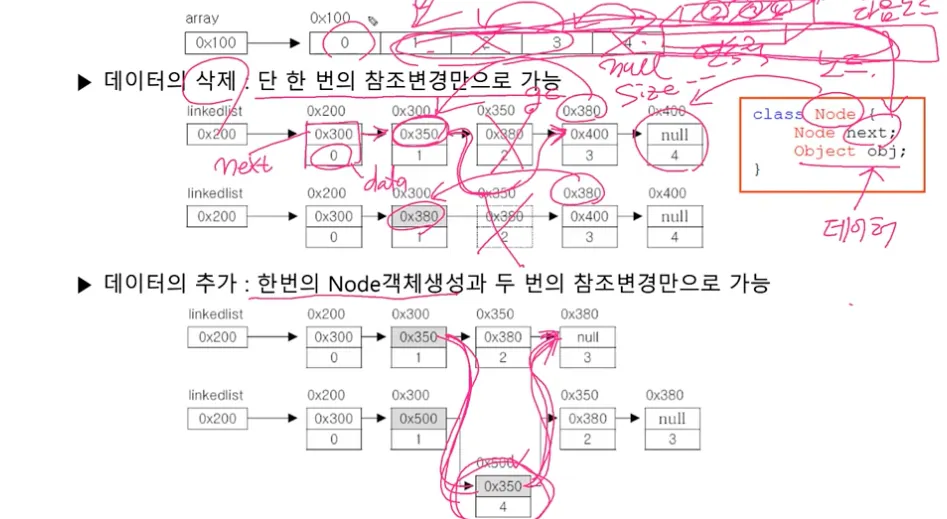
LinkedList
•
ArrayList 배열의 단점을 보완
•
배열과 달리 불연속적으로 존재하는 데이터를 연결 (배열에 비해 접근성이 나쁘다..)
•
doubly linked list (이중 연결리스트, 접근성 향상)

•
doubly circular linked list (이중 원형 연결 리스트)

ArrayList(배열기반, 연속적) vs LinkedList(연결기반, 불연속적)
•
순차적으로 데이터를 추가/삭제 : ArrayList가 빠름
•
비순차적으로 데이터를 추가/삭제 : LinkedList가 빠름
•
접근시간 : ArrayList가 빠름

스택과 큐 (Stack & Queue)
•
스택 : LIFO구조로 마지막에 저장된 것을 제일 먼저 꺼내게 된다
◦
Stack st new Stack() 클래스라 가능
•
큐 : FIFO구조로 제일 먼저 저장한 것을 제일 먼저 꺼내게 된다
◦
Queue q = new Queue() 인터페이스라 불가능
•
ArrayList는 스택이 적합, Linked List는 큐가 적합
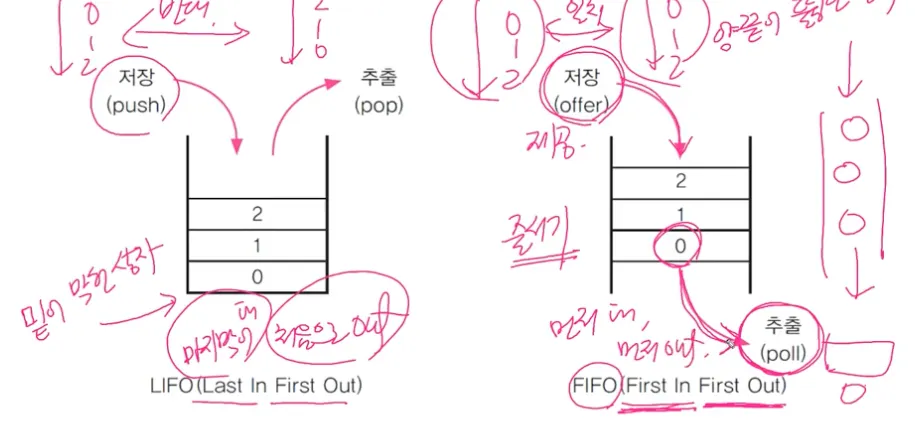
Stack의 메서드
•
peek은 가장 위에 있는 (나중에 들어온) 객체 확인
•
search는 가장 위에 있는 (나중에 들어온) 객체를 1부터 시작해서 검색

Queue의 메서드
•
peek은 가장 아래 있는 객체 확인

Iterator, ListIterator, Enumeration
•
컬렉션에 저장된 데이터를 접근하는데 사용되는 인터페이스
•
컬렉션에 저장된 요소들을 읽어오는 방법을 표준화한 것
•
컬렉션에 iterator()를 호출해서 Iterator를 구현한 객체를 얻어서 사용
•
Enumeration은 Iterator의 구버전
•
ListIterator는 Iterator의 접근성을 향상시킨 것 (단방향 → 양방향)
(next와 previous를 둘 다 갖고 있음)

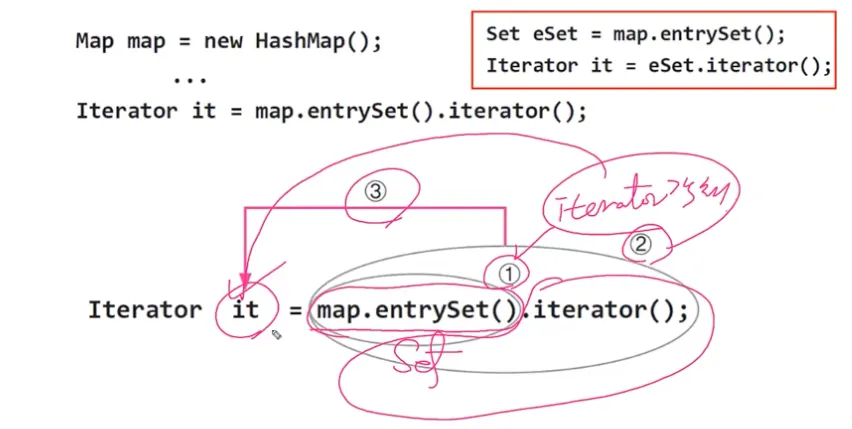
Map과 Iterator
•
Map에는 Iterator()가 없다. keySet(), entrySet(), values()를 호출해야 한다
Arrays - 배열을 다루기 편리한 메서드(static) 제공




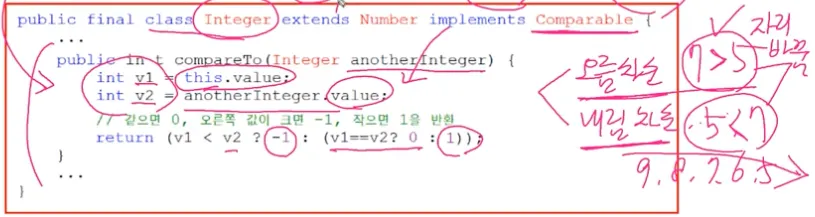
Comparator와 Comparable
•
객체 정렬에 필요한 메서드(정렬기준 제공)를 정의한 인터페이스
◦
Comparable : 기본 정렬기준(사전순, 오름차순 )을 구현하는데 사용
◦
Comparator : 기본 정렬기준 외에 다른 기준으로 정렬하고자 할 때 사용

•
compare()와 compareTo()는 두 객체의 비교결과를 반환하도록 작성
(같으면 0, 오른쪽이 크면 -, 오른쪽이 작으면 +)
HashSet - 순서 X, 중복 X
•
Set 인터페이스를 구현한 대표적인 컬렉션 클래스
•
순서를 유지하려면 LinkedHashSet 클래스를 사용하면 된다

•
HashSet은 객체를 저장하기 전에 기존에 같은 객체가 있는지 확인한다
(같은 객체가 없으면 저장하고 있으면 저장하지 않는다)
•
boolean add(Object o)는 저장할 객체의 equals()와 hashCode()를 호출한다
(단, equals()와 hashCode()가 오버라이딩 되어 있어야함!!)

•
setA.retainAll(setB); //교집합. 공통된 요소만 남기고 삭제
•
setA.addAll(setB); //합집합. setB의 모든 요소를 추가(중복 제외)
•
setA.removeAll(setB); //차집합. setB와 공통 요소를 제거
TreeSet
•
이진 탐색 트리(binary search tree)로 범위 탐색과 정렬에 유리한 컬렉션 클래스
•
이진 트리는 모든 노드가 최대 2개의 하위 노드를 갖는다
(부모보다 작은 값은 왼쪽, 큰 값은 오른쪽에 저장)
•
데이터가 많아질 수록 HashSet 보다 데이터 추가, 삭제에 시간이 더 걸린다
•
boolean add(Object o)는 저장할 객체의 compare()를 호출한다
TreeSet의 주요 생성자와 메서드

HashMap과 Hashtable - 순서X, 중복(키X, 값O)
•
Map 인터페이스를 구현. 데이터를 키와 값의 쌍으로 저장
•
HashMap(동기화X)은 Hashtable(동기화O)의 신버전

•
HashMap
◦
Map 인터페이스를 구현한 대표적인 컬렉션 클래스
◦
순서를 유지하려면 LinkedHashMap 클래스를 사용하면 된다
•
TreeMap (= TreeSet)
◦
범위 검색과 정렬에 유리한 컬렉션 클래스
◦
HashMap보다 데이터 추가, 삭제에 시간이 더 걸린다
HashMap의 키(Key)와 값(Value)
•
해싱(Hashing)기법으로 데이터를 저장. 데이터가 많아도 검색이 빠르다
•
Map 인터페이스를 구현. 데이터를 키와 값의 쌍(Entry)으로 저장
•
값(Value)는 새로운 값이 입력되면 덮어씌워진다

Hashing
•
해시 함수를 이용해서 해시 테이블에 데이터를 저장하고 검색하는 것
•
해시 함수 : 키를 이용해서 저장 위치(배열의 인덱스)인 해시 코드를 반환한다
(해시 함수는 같은 키에 대해 항상 같은 해시 코드를 반환한다)
(서로 다른 키일지라도 같은 값의 해시 코드를 반환할 수도 있다)
•
해시 테이블 : 배열과 링크드 리스트가 조합된 형태이다 (접근성 + 변경 간편)
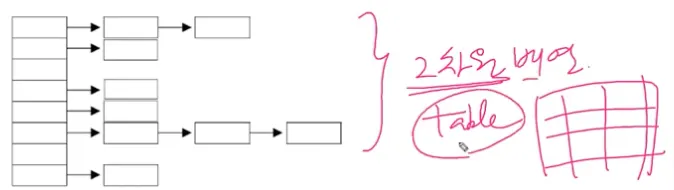
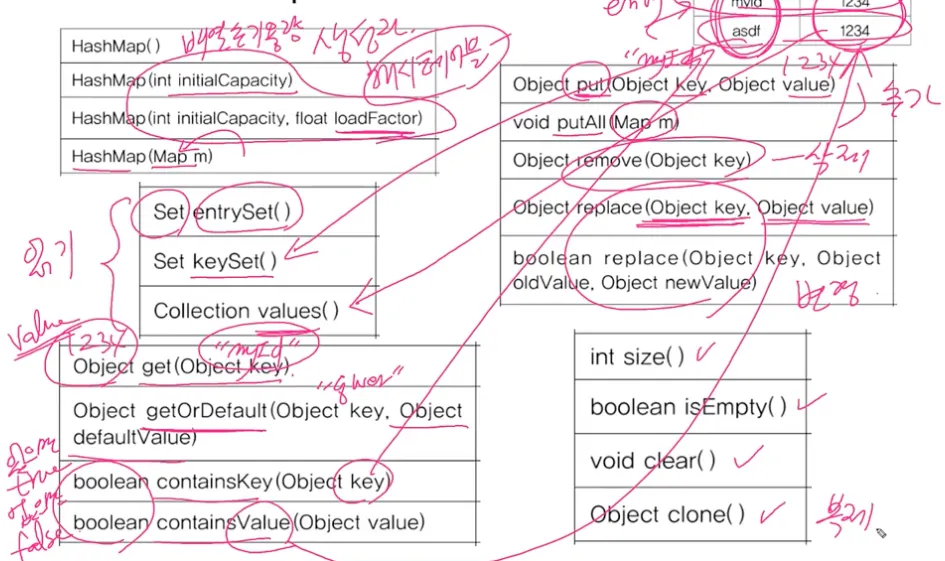
HashMap의 주요 메서드
Collections
•
컬렉션을 위한 메서드(static)를 제공
•
컬렉션 채우기, 복사, 정렬, 검색 : fill(), copy(), sort(), binarySearch() 등
•
컬렉션 동기화 : synchronizedXXX()

•
변경불가(readOnly) 컬렉션 만들기 : unmidifiableXXX()

•
싱글톤 컬렉션 만들기 : singletonXXX()

•
한 종류의 객체만 저장하는 컬렉션 만들기 : checkedXXX()

컬렉션 클래스 정리