강의
운영체제의 역할
1.
시스템 자원(System Resource) 관리자
•
Operating System 또는 OS라고 부릅니다.
•
시스템 자원 = 컴퓨터 하드웨어
◦
CPU (중앙처리장치) : 각 프로그램이 얼마나 CPU를 사용할지를 결정할 수 없습니다.
◦
Memory (DRAM, RAM) : 각 프로그램이 어느 주소에 저장되어야 하는지 어느 정도의 메모리 공간을 확보해줘야 하는지를 결정할 수는 없습니다.
◦
I/O Devices (입출력장치) : 스스로 표시할 수는 없습니다.
◦
SSD, HDD (저장매체) : 어떻게, 어디에 저장할지는 결정할 수 없습니다.
2.
사용자와 컴퓨터간의 커뮤니케이션 지원
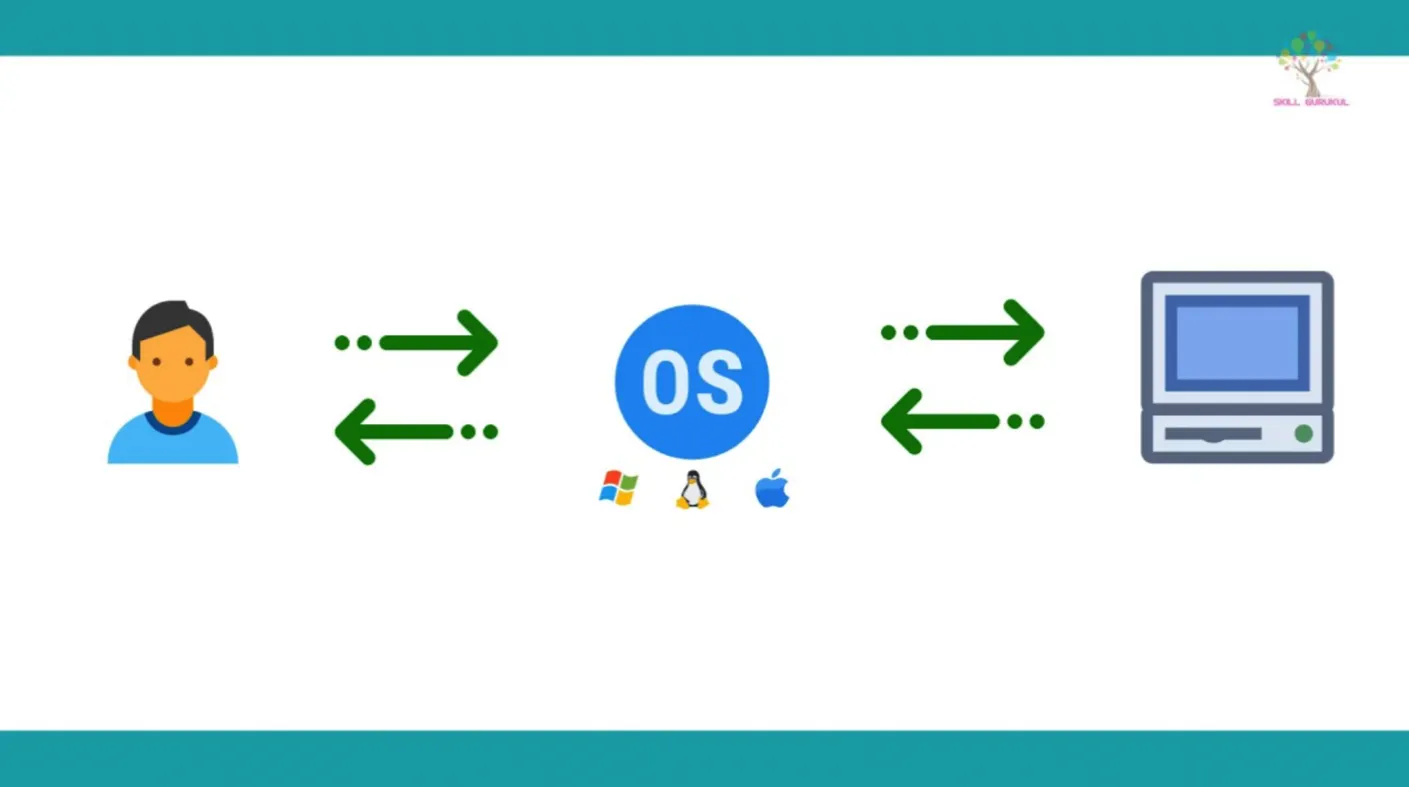
3.
컴퓨터 하드웨어와 응용 프로그램 제어
대표적인 운영체제
•
Windows OS
•
Mac OS
•
UNIX
◦
UNIX 계열 OS (UNIX와 사용법이나 OS 구조가 유사)
◦
LINUX OS (프로그래머나 전공자라면 알아야 할 OS)
RTOS와 GPOS
•
RealTime OS (RTOS)
◦
응용 프로그램 실시간 성능 보장을 목표로 하는 OS
◦
정확하게 프로그램 시작, 완료 시간을 보장
◦
Hardware RTOS, Software RTOS
•
General Purpose OS (GPOS)
◦
프로세스 실행시간에 민감하지 않고 일반적인 목적으로 사용되는 OS
◦
Windows, Linux 등
응용 프로그램이란?
•
프로그램 = 소프트웨어
•
소프트웨어 = 운영체제, 응용 프로그램(엑셀, 파워포인트, 우리가 만든 프로그램 등)
•
응용 프로그램 = Application (PC) = App (Mobile)
운영체제와 응용 프로그램 간의 관계
•
운영체제는
◦
응용 프로그램을 관리
◦
응용 프로그램을 실행
◦
응용 프로그램 간의 권한을 관리
◦
응용 프로그램을 사용하는 사용자도 관리
◦
사용자가 사용하는 응용 프로그램이 효율적으로 적절하게 동작하도록 지원
◦
응용 프로그램이 요청하는 시스템 리소스를 효율적으로 분배하고 지원
운영체제의 역사
•
1950년대~
◦
운영체제가 없었다.
◦
프로그램이 시스템 자원을 직접 제어
•
1960년대~
◦
배치 처리 시스템
•
1970년대~
◦
시분할 시스템/멀티 태스킹 시스템
◦
UNIX OS (C언어)
•
1980년대~
◦
GUI 환경을 제공
◦
개인용 컴퓨터 시대 도래
•
1990년대~
◦
다양한 응용 프로그램이 활성화
◦
인터넷(네트워크 기술) 발달
◦
오픈 소스 운동 활성화
•
2000년대~
◦
오픈 소스가 더더욱 활성화
◦
가상 머신 발전
◦
대용량 병렬 처리 발전
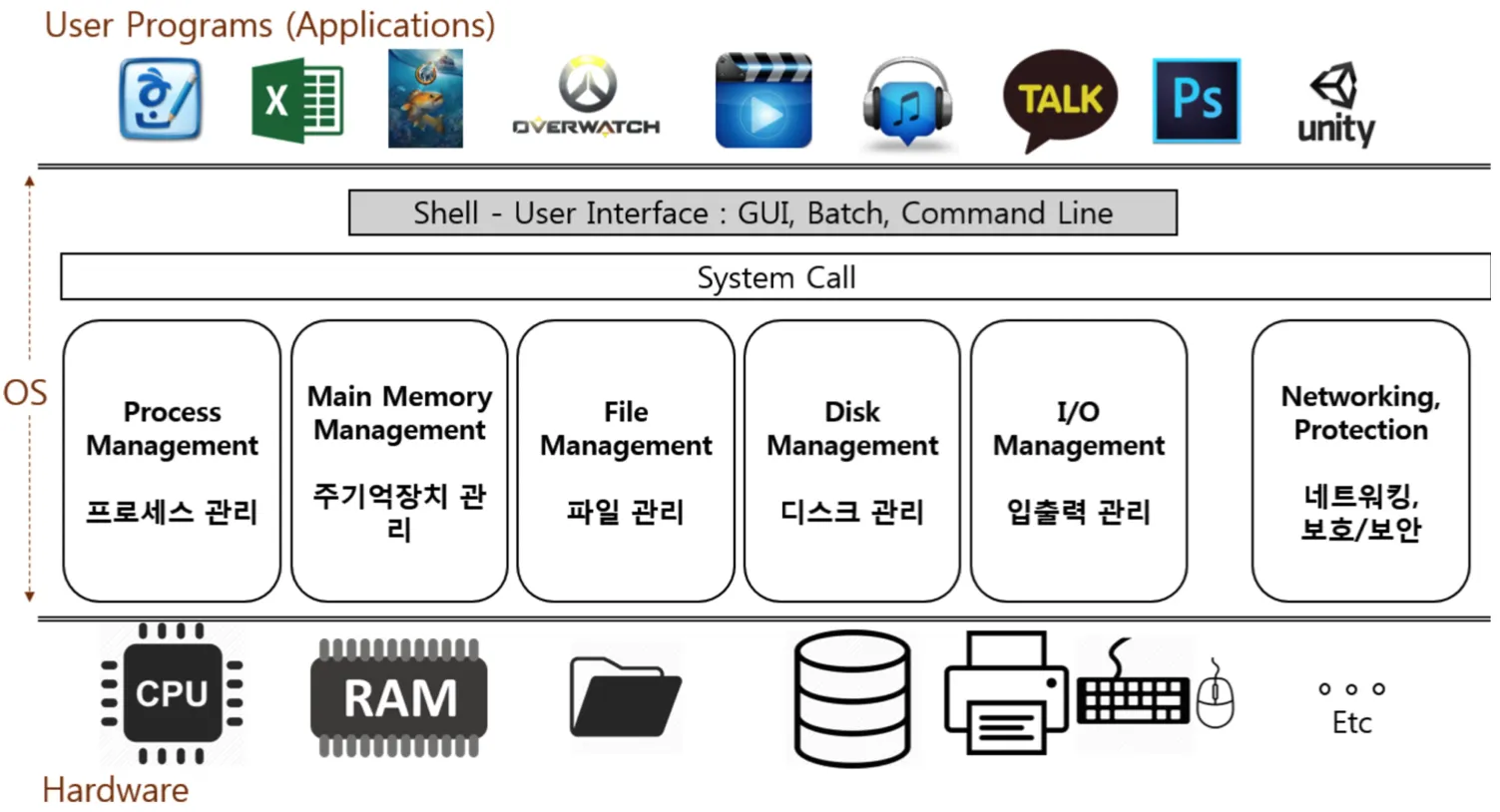
운영체제, 응용 프로그램, 컴퓨터 하드웨어(시스템 리소스) 간의 관계
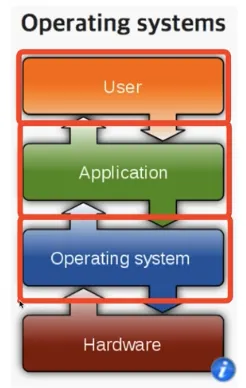
•
도서관으로 비유
◦
운영체제는 도서관
◦
응용 프로그램은 시민
◦
컴퓨터 하드웨어는 책
•
운영체제의 역할
◦
시민(응용 프로그램)은 도서관(운영체제)에 원하는 책(자원)을 요청
◦
도서관(운영체제)은 적절한 책(자원)을 찾아서 시민(응용 프로그램)에게 빌려줌
◦
시민(응용 프로그램)이 기한이 다 되면 도서관(운영체제)이 해당 책(자원)을 회수
•
실제로 비유
◦
운영체제는 응용 프로그램이 요청하는 메모리를 허가하고 분배한다
◦
운영체제는 응용 프로그램이 요청하는 CPU 시간을 제공한다
◦
운영체제는 응용 프로그램이 요청하는 IO Devices 사용을 허가/제어한다
운영체제는 사용자를 위해 인터페이스를 제공
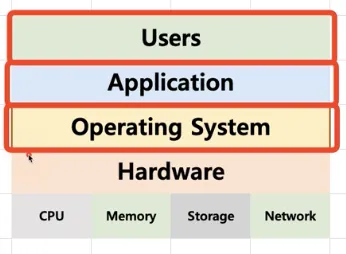
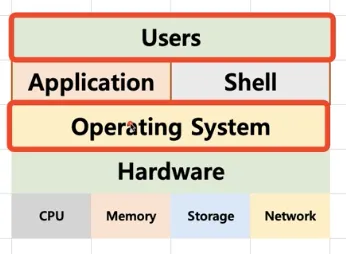
•
쉘(Shell)
◦
사용자가 운영체제 기능과 서비스를 조작할 수 있도록 인터페이스를 제공하는 프로그램
◦
쉘은 터미널 환경(CLI)과 GUI 환경 두 종류로 분류
운영체제는 응용 프로그램을 위해서도 인터페이스를 제공
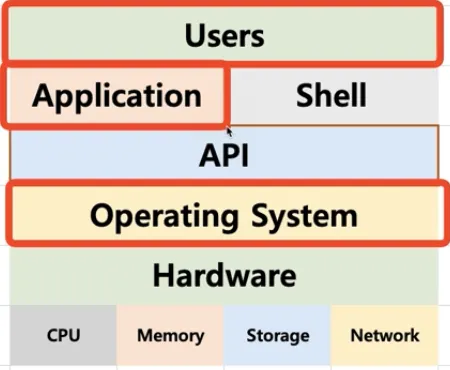
•
API (Application Programming Interface)
◦
각 언어별 함수로 제공 (= 요청서)
◦
보통은 라이브러리 형태로 제공
◦
파일을 오픈하기 위한 C언어의 open() 함수도 API의 일종
◦
쉘 (Shell) 또한 API를 사용해서 처리
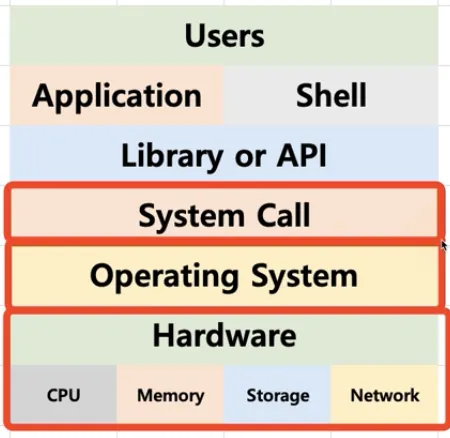
•
시스템 콜
◦
시스템 콜 또는 시스템 호출 인터페이스
◦
운영체제가 운영체제 각 기능을 사용할 수 있도록 시스템 콜이라는 명령 또는 함수를 제공
◦
API 내부에는 시스템 콜을 호출하는 형태로 만들어지는 경우가 대부분
◦
시스템 콜 정의 예 → POSIX API, 윈도우 API
운영체제를 만든다면?
1.
운영체제를 개발 (kernel)
2.
시스템 콜을 개발
3.
API (Library) 개발
4.
Shell 프로그램 개발
5.
응용 프로그램 개발
CPU Protection Rings
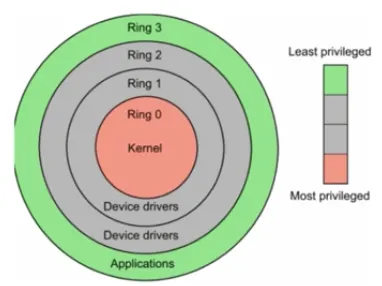
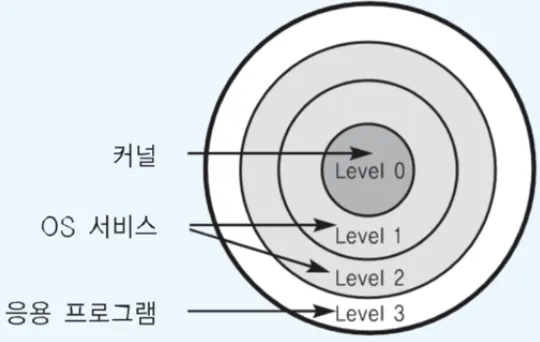
•
CPU도 권한 모드라는 것을 가지고 있음
◦
사용자 모드 (user mode)
▪
응용 프로그램이 사용
◦
커널 모드 (kernel mode)
▪
OS가 사용
▪
특권 명령어 실행과 원하는 작업 수행을 위한 자원 접근을 가능케 하는 모드
•
사용자 모드와 커널 모드의 비유
◦
함부로 응용 프로그램은 전체 컴퓨터 시스템을 해치지 않아야함
◦
사용자 모드
▪
주민등록등본은 꼭 동사무소 또는 민원24에서 특별한 신청서를 써야만 발급 받을 수 있음.
◦
커널 모드
▪
동사무소 직원은 특별한 권한을 가지고 주민등록등본 출력 명령을 실행할 수 있음
커널(Kernel)과 쉘(Shell)
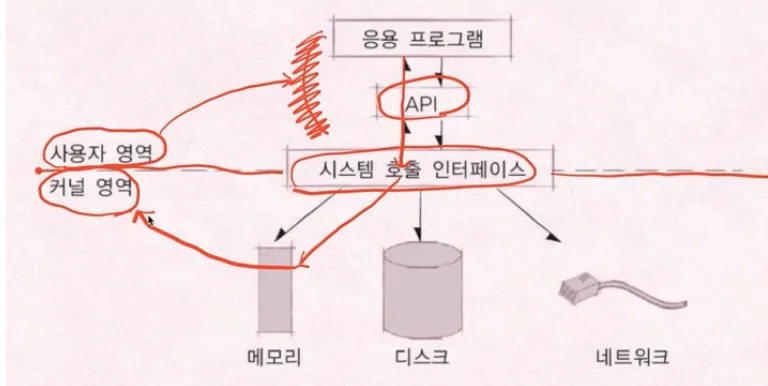
•
커널(Kernel)이란?
◦
OS가 CPU가 쓸 때 사용하는 것
•
쉘(Shell)이란?
◦
커널을 둘러싸고 있는 사용자에게 인터페이스를 제공하는 것
•
시스템 콜은 커널 모드로 실행
◦
커널 모드에서만 실행 가능한 기능들이 있음
◦
커널 모드로 실행하려면 반드시 시스템 콜을 사용해야함
◦
시스템 콜은 운영체제가 제공
배치 처리 시스템 → 시분할 시스템, 멀티 태스킹
•
기존 배치 처리 시스템
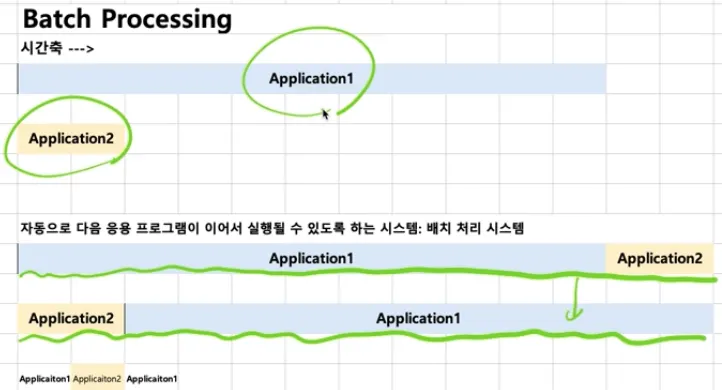
◦
어떤 프로그램은 실행이 너무 시간이 많이 걸려서 다른 프로그램이 실행하는데 시간을 많이 기다려야 한다
◦
동시에 여러 응용 프로그램을 실행시키고 싶어함 → 멀티 태스킹
◦
여러 사용자가 동시에 하나의 컴퓨터를 사용하고 싶어함 → 시분할 시스템
•
시분할 시스템
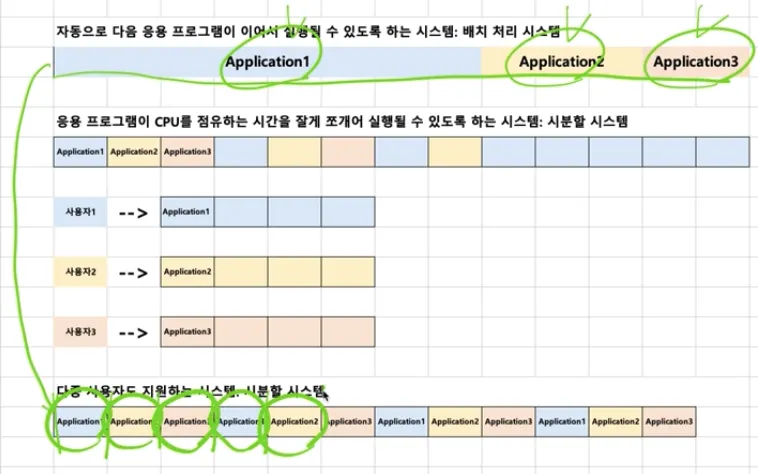
◦
다중 사용자 지원을 위해 컴퓨터 응답 시간을 최소화하는 시스템
•
멀티 태스킹
◦
단일 CPU에서 여러 응용 프로그램이 동시에 실행되는 것처럼 보이도록 하는 시스템
멀티 태스킹 vs 멀티 프로세싱 vs 멀티 프로그래밍
•
멀티 태스킹
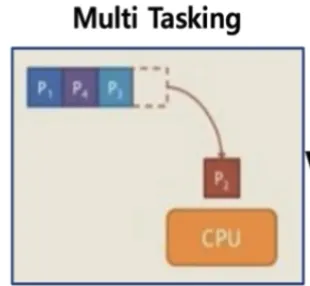
◦
단일 CPU
•
멀티 프로세싱
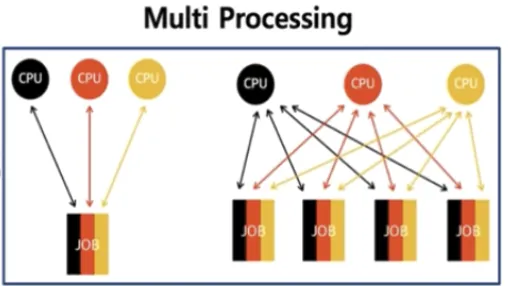
◦
여러 CPU
•
멀티 프로그래밍과 Wait
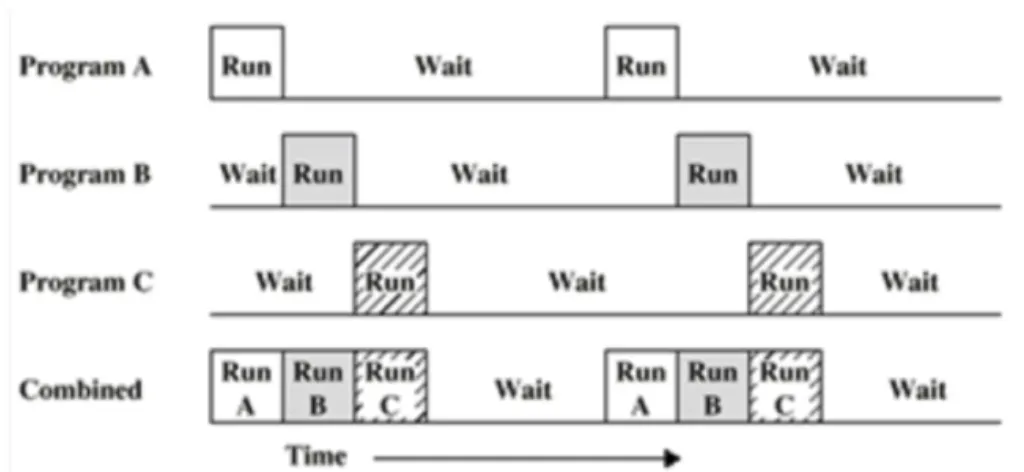
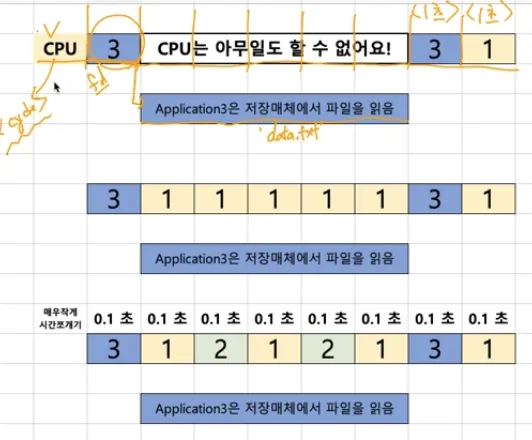
◦
멀티 프로그래밍
▪
최대한 CPU를 많이 활용하도록 하는 시스템
▪
시간 대비 CPU 활용도를 높이자
▪
응용 프로그램을 짧은 시간 안에 실행 완료를 시킬 수 있음
◦
Wait
▪
응용 프로그램은 온전히 CPU를 쓰기 보다 다른 작업을 중간에 필요로 하는 경우가 많습니다.
•
응용 프로그램이 실행되다가 파일을 읽는다
•
응용 프로그램이 실행되다가 프린팅을 한다
▪
간단히 저장매체로부터 파일 읽기를 기다리는 시간으로 가정
프로세스란?
•
실행 중인 프로그램을 프로세스라고 함
◦
프로세스 : 메모리에 올려져서 실행 중인 프로그램
◦
코드 이미지(바이너리) : 실행 파일 ex. ELF format
•
프로세스 = 작업 = task = job
•
응용 프로그램 ≠ 프로세스
◦
응용 프로그램은 여러 개의 프로세스로 이루어질 수 있음
◦
하나의 응용 프로그램은 여러 개의 프로세스가 상호작용을 하면서 실행될 수 있음
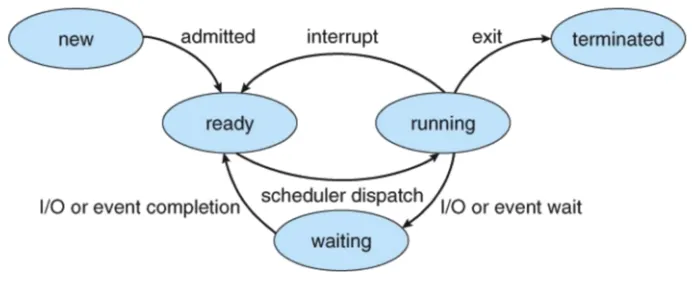
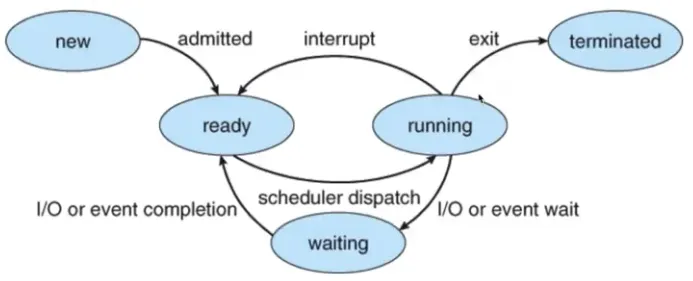
프로세스의 상태
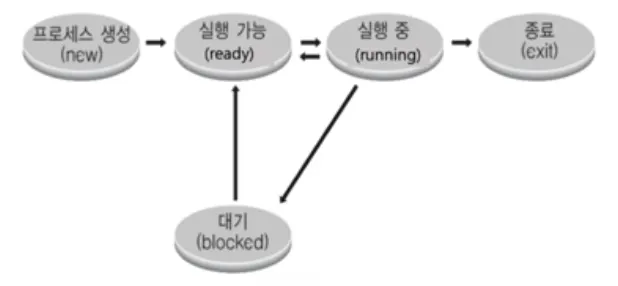
•
running state
◦
현재 CPU에서 실행 상태
•
ready state
◦
CPU에서 실행 가능 상태 (실행 대기 상태)
•
block state
◦
특정 이벤트 발생 대기 상태
프로세스의 상태간 관계
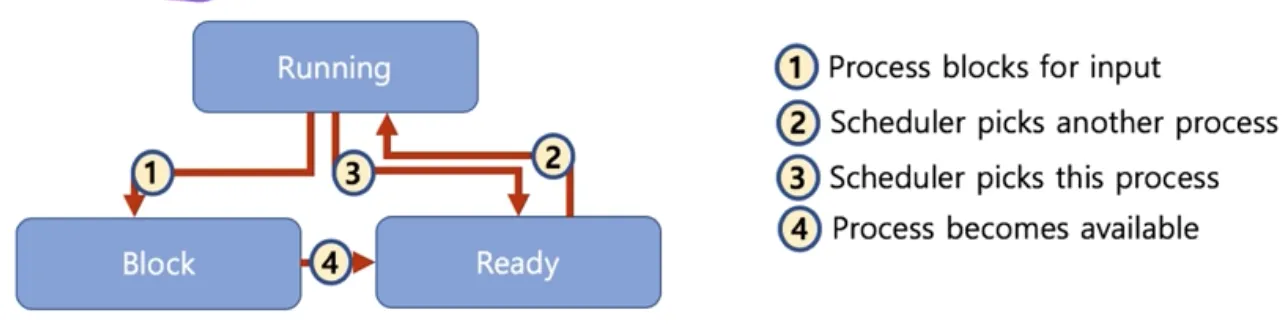
•
running → block → ready → running
•
running → ready → running
스케줄러
•
개념
◦
스케줄링 알고리즘에 의해 프로세스의 실행을 관리한다
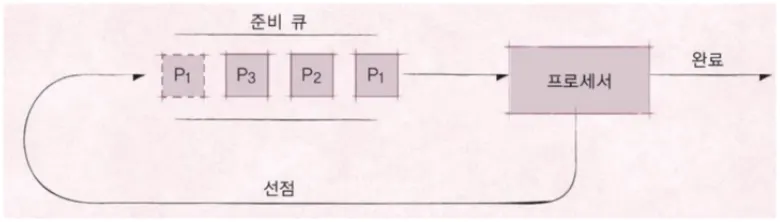
•
선점형 스케줄러 (Preemptive Scheduling)
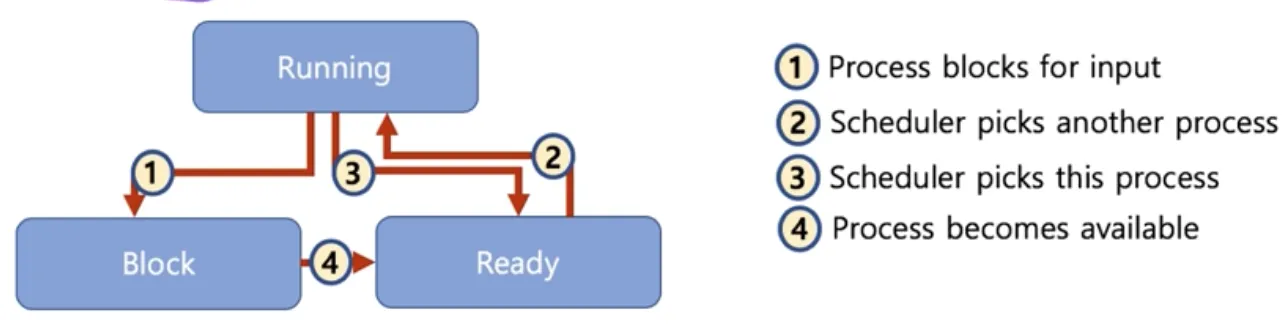
◦
하나의 프로세스가 다른 프로세스 대신에 CPU를 차지할 수 있음
▪
프로세스 running 중에 스케줄러가 이를 중단시키고 다른 프로세스로 교체 가능
◦
시분할 시스템을 위한 기본 알고리즘 사용
▪
ex) RoundRobin 스케줄링
•
비선점형 스케줄러 (Non-preemptive Scheduling)
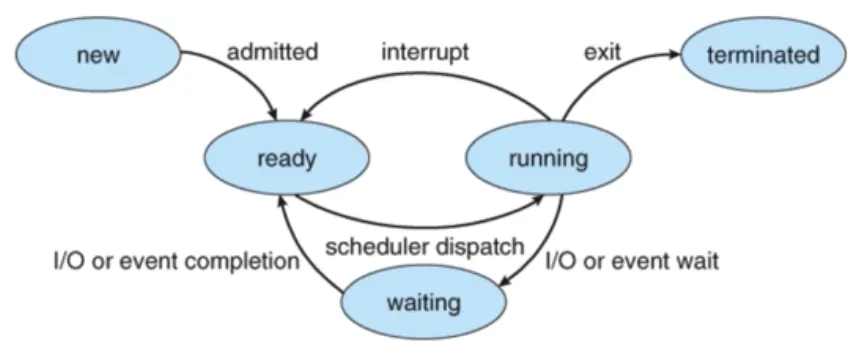
◦
하나의 프로세스가 끝나지 않으면 다른 프로세스는 CPU를 사용할 수 없음
▪
프로세스가 자발적으로 block 상태로 들어가거나 실행이 끝났을 때만 다른 프로세스로 교체 가능
◦
어떤 프로세스를 먼저 실행시킬지에 대한 알고리즘 사용
▪
ex) FIFO(FCFS), SJF, Priority-based 스케줄링
스케줄링 알고리즘 종류
•
FIFO 스케줄링 = FCFS (First Come First Served) 스케줄링

◦
가장 간단한 스케줄 (배치 처리 시스템과 유사)
•
최단 작업 우선 스케줄링 = SJF(Shortest Job First) 스케줄링
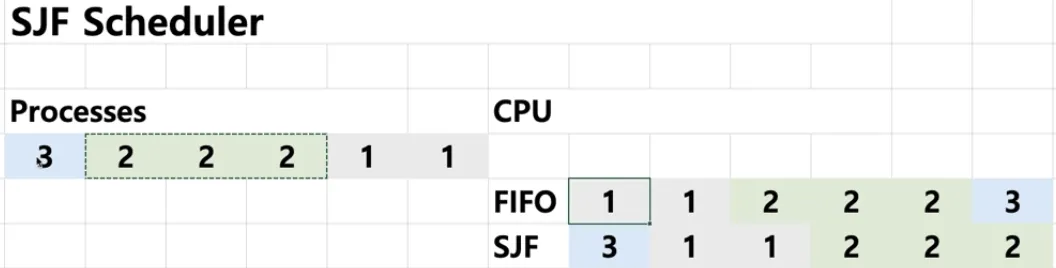
◦
가장 프로세스 실행시간이 짧은 프로세스부터 먼저 실행을 시키는 알고리즘
•
우선순위 기반 스케줄링 = Priority-Based 스케줄링
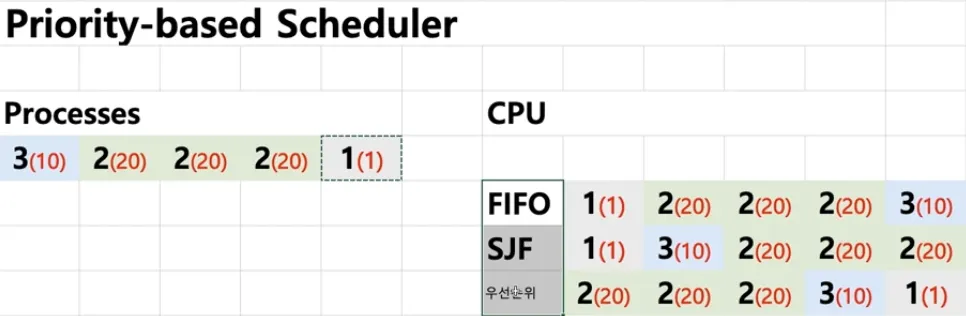
◦
정적 우선순위
▪
프로세스마다 우선순위를 미리 지정
◦
동적 우선순위
▪
스케줄러가 상황에 따라 우선순위를 동적으로 변경
•
Round Robin 스케줄러
◦
시분할 시스템을 기반으로 정해진 실행 시간만큼 선점하여 반복해서 실행 시키는 알고리즘
인터럽트
•
인터럽트란?
◦
CPU가 프로그램을 실행하고 있을 때, 입출력 하드웨어 등의 장치나 또는 예외상황이 발생하여 처리가 필요할 경우에 운영체제가 CPU에 알려서 처리하는 기술
•
이벤트와 인터럽트
◦
인터럽트는 일종의 이벤트로 불리며 이벤트에 맞게 운영체제가 처리함
인터럽트 종류
•
내부 인터럽트 (소프트웨어 인터럽트)
◦
주로 프로그램 내부에서 잘못된 명령 또는 잘못된 데이터 사용 시 발생
▪
예외 상황 (0 으로 나누기)
▪
사용자 모드에서 허용되지 않은 명령 또는 공간 접근 시
▪
계산 결과가 Overflow/Underflow 날 때
•
외부 인터럽트 (하드웨어 인터럽트)
◦
주로 하드웨어(프로그램 외부)에서 발생되는 이벤트
▪
전원 이상
▪
기계 문제
▪
IO 관련 이벤트
▪
Timer 이벤트
인터럽트가 사용되는 곳
•
선점형 스케줄러 구현
◦
프로세스 running 중에 스케줄러가 이를 중단시키고 다른 프로세스로 교체하기 위해 현재 프로세스 실행을 중단시키려면 스케줄러 코드가 실행돼서 현 프로세스 실행을 중지시켜야함
◦
running → ready
•
타이머
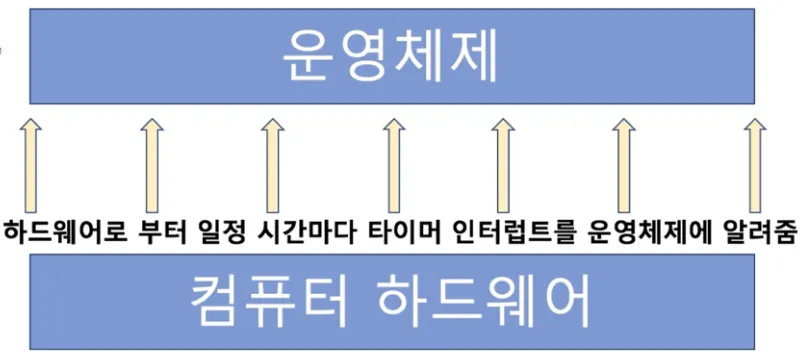
◦
하드웨어로부터 일정 시간마다 타이머 인터럽트를 운영체제에 알려줌
◦
선점형 스케줄러 구현을 위해 사용
•
IO Device와의 커뮤니케이션
◦
저장매체에서 데이터 처리 완료시 프로세스를 깨워야함
◦
waiting → ready
•
예외 상황 핸들링
◦
CPU가 프로그램을 실행하고 있을 때 입출력 하드웨어 등의 장치나 또는 예외 상황이 발생한 경우 CPU가 해당 처리를 할 수 있도록 CPU에 알려줘야함
시스템 콜
mov eax, 1 #시스템 콜 번호
mov ebx, 0 #인자
int 0x80 #int는 CPU OP code로 인터럽트 명령이고 0x80은 시스템 콜 인터럽트 번호
Bash
복사
•
시스템 콜 실행을 위해서는 강제로 코드에 인터럽트 명령을 넣어 CPU에게 실행시켜야한다.
1.
시스템 콜 인터럽트 명령을 호출
2.
CPU가 사용자 모드에서 커널 모드로 변경
3.
IDT(Interrupt Descriptor Table)에서 0x80에 해당하는 주소(함수)를 찾아서 실행
4.
system_call() 함수에서 eax로부터 받은 시스템 콜 번호에 맞는 시스템 콜 함수로 이동
5.
해당 시스템 콜 함수를 실행 후 다시 커널 모드에서 사용자 모드로 변경하고 프로세스 진행
•
사용자/커널 모드, 프로세스, 인터럽트의 관계
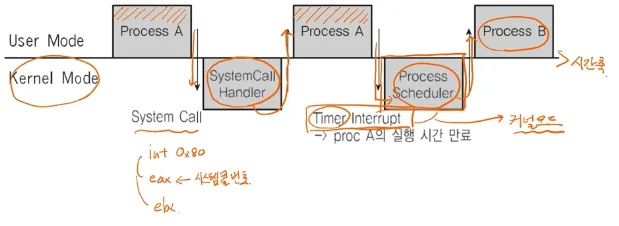
1.
프로세스 실행 중 인터럽트 발생
2.
현 프로세스 실행 중단
3.
인터럽트 처리 함수 실행 (운영체제)
4.
현 프로세스 재실행
•
인터럽트와 IDT(Interrupt Descriptor Tabel)
◦
인터럽트는 미리 정의되어 각각 이벤트 번호와 실행 함수를 가리키는 주소가 기록되어 있음
▪
어디에? IDT(Interrupt Descriptor Table)에 이벤트 번호와 함수의 주소를 매핑하여 기록
▪
언제? 컴퓨터 부팅 시 운영체제가 기록
▪
어떤 코드? 운영체제 내부 코드
◦
리눅스의 예
▪
0~31 : 소프트웨어 인터럽트 (예외상황들로 일부는 정의 안된 채로 남겨져 있음)
▪
32~47 : 하드웨어 인터럽트 (주변 장치의 종류/갯수에 따라 변경 가능)
▪
128 : 시스템 콜
프로세스의 구조
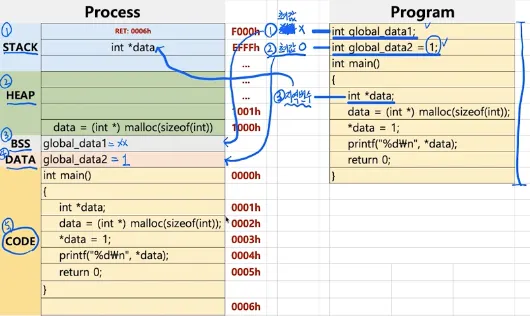
•
프로세스 구조
◦
code : 코드
◦
data : 컴파일 단계에서 생성되는 데이터
▪
BSS : 초기화되지 않은 전역 변수
▪
DATA : 초기화된 전역 변수
◦
stack : 런타임 단계에서 생성되는 임시 데이터 (함수, 로컬 변수 등)
◦
heap : 런타임 단계에서 코드에 의해 동적으로 만들어지는 데이터
•
레지스터 구조
◦
PC(Program Counter) : 프로세스에서 실행 중인 code의 위치를 기록
◦
SP(Stack Pointer) : 프로세스에서 실행 중인 stack의 위치를 기록
◦
EAX : 함수의 리턴 값을 기록
◦
EBP : 함수 최상단의 Stack Pointer를 기록
컨텍스트 스위칭
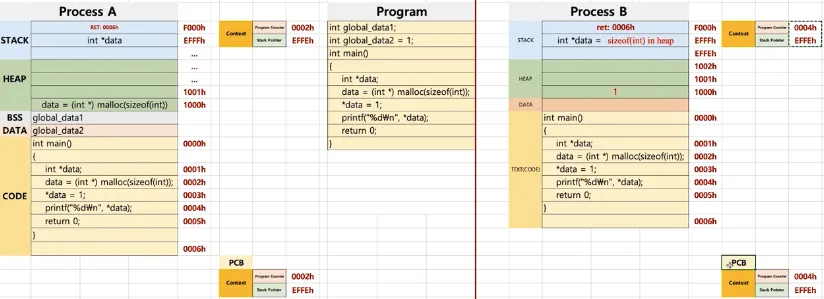
•
PCB (Process Context Block)
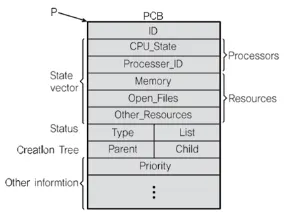
◦
프로세스가 실행 중인 상태 정보를 캡쳐/구조화해서 저장하는 곳
•
스케줄러에 의해 컨텍스트 스위칭이 일어날 때

◦
Dispatch : PCB 정보를 CPU의 레지스터에 넣고 프로세스의 상태를 변경하는 것
프로세스간 커뮤니케이션
•
프로세스간 커뮤니케이션이 필요한 이유
◦
여러 프로세스 동시 실행을 통한 성능 개선
◦
복잡한 프로그램을 위한 프로세스간 통신 필요
•
프로세스의 공간
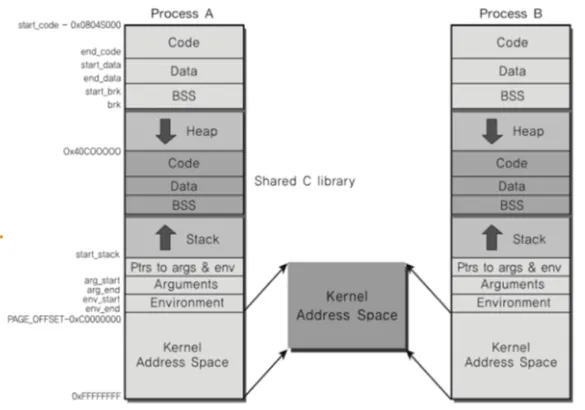
◦
하나의 프로세스는 최소 4GB의 주소 공간을 가짐
◦
0~3GB 까지는 사용자 모드, 나머지는 커널 모드
◦
모든 프로세스가 커널 공간은 공유
IPC (Inter Process Communication) 기법
•
File
◦
저장매체를 사용하기 때문에 속도가 느려 실시간성이 떨어짐
◦
다른 IPC 기법과는 달리 커널 공간을 사용하지 않음
•
Pipe
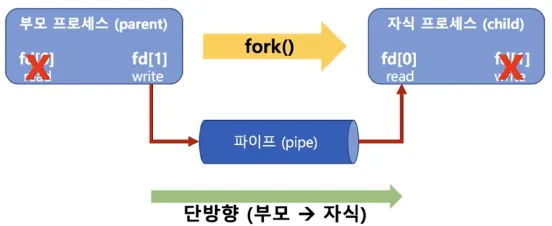

◦
pipe() 함수의 인자 중 fd[2]는 정수 배열로 fd[0]과 fd[1]의 할당되는 주소값이 각각 다름
◦
fork() 함수의 리턴 값 : 부모 프로세스는 프로세스ID, 자식 프로세스는 0
◦
write() 와 read() 함수를 통해 부모 → 자식의 단방향 통신
•
Message Queue
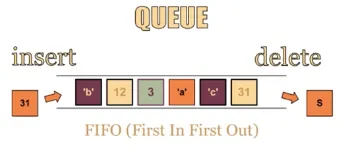
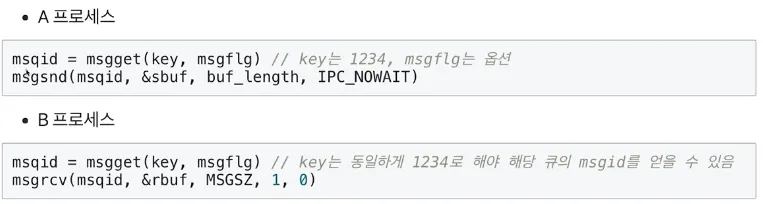
◦
msgget() 함수를 통해 특정 key 값을 갖는 메세지 큐의 ID를 반환 받음
◦
msgsnd() 함수를 통해 큐ID와 메세지가 담긴 변수를 전달하면 메세지를 송신
◦
msgrcv() 함수를 통해 큐ID와 메세지를 받을 변수를 전달하면 메세지를 수신
◦
부모/자식 관계가 필요 없이 어느 프로세스간에도 양방향 통신이 가능
•
Shared Memory
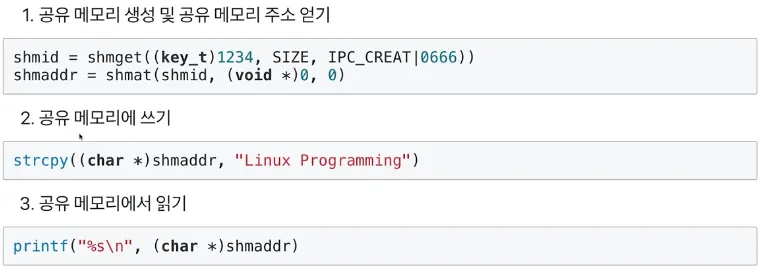
◦
커널 공간에 메모리 공간을 만들고 해당 공간을 변수처럼 사용하는 방식
◦
공유 메모리의 key를 가지고 여러 프로세스가 접근하여 쓰기/읽기 가능
◦
shmget() 함수를 통해 key와 사이즈를 전달하면 공유 메모리의 ID를 반환 받음
◦
shmat() 함수를 통해 공유 메모리 ID를 전달하면 공유 메모리의 주소를 반환 받음
◦
strcpy(), printf() 함수를 통해 공유 메모리 주소에 쓰기/읽기 가능
•
Signal
◦
유닉스에서 30년 이상 사용된 전통적인 기법으로 커널 또는 프로세스에서 다른 프로세스에 어떤 이벤트가 발생되었는지를 알려주는 기법
◦
커널 모드에서 사용자 모드로 전환 시 시그널을 처리
◦
프로세스 관련 코드에 관련 시그널 핸들러를 등록해서 해당 시그널 처리 실행

◦
주요 시그널
▪
kill -l 을 통해 확인 가능
▪
kill -i PID 를 통해 시그널을 보낼 수 있음
•
Socket
◦
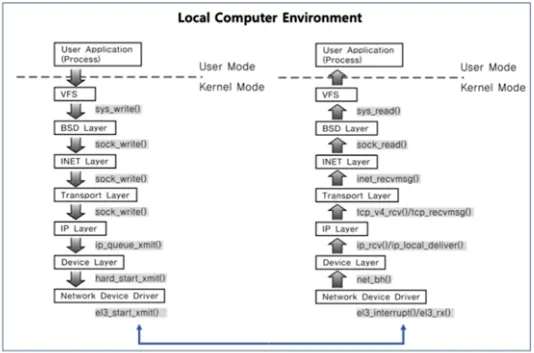
기본적으로는 클라이언트와 서버 등 두 개의 다른 컴퓨터 간의 네트워크 기반 통신을 위한 기술
◦
하나의 컴퓨터 안에서 두 개의 프로세스 간의 통신 기법으로도 사용 가능
◦
로컬 환경 안에서 Network Layer를 쭉 타서 돌아올 땐 다른 프로세스로 돌아오는 방식
스레드
•
스레드란?
◦
Light Weight Process 라고도 함
◦
하나의 프로세스에 여러 개의 스레드 생성 가능
◦
스레드들은 동시에 실행 가능
•
프로세스 내에서 스레드 간 공간 공유
◦
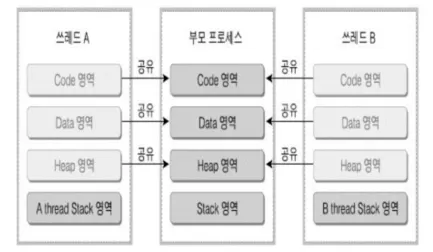
프로세스 안에 있으므로 여러 스레드들이 프로세스의 데이터를 모두 접근 가능
◦
Stack 영역을 각 스레드별로 분리하고 Heap, Data, Code 영역은 공유
•
스레드의 장점
1.
사용자에 대한 응답성 향상

•
스레드를 동시에 실행하여 원활한 대응이 가능
2.
자원 공유 효율
•
IPC 기법과 같이 프로세스간 자원 공유를 위해 번거로운 작업이 필요 없음
•
프로세스 안에 있으므로 프로세스의 데이터를 모두 접근 가능
3.
작업이 분리되어 코드가 간결
•
작성하기 나름
•
스레드의 단점
1.
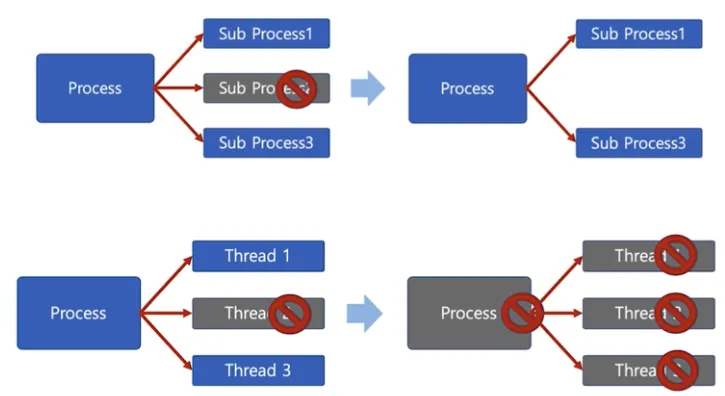
프로세스 영향
•
멀티 프로세스와는 다르게 스레드 중 한 스레드만 문제가 있어도 전체 프로세스가 영향을 받음
2.
컨텍스트 스위칭을 통한 성능 저하
•
Linux는 스레드를 프로세스와 같이 다루기 때문에 모든 스레드를 스케줄링하므로 컨텍스트 스위칭이 빈번하게 일어남
•
프로세스 vs 스레드
◦
프로세스는 독립적, 스레드는 프로세스의 서브셋
◦
프로세스는 각각 독립적인 자원을 가짐, 스레드는 프로세스의 자원을 공유
◦
프로세스는 자기만의 주소 영역을 가짐, 스레드는 주소 영역을 공유
◦
프로세스 간에는 IPC 기법으로 통신해야함, 스레드는 필요 없음
스레드의 동기화 이슈
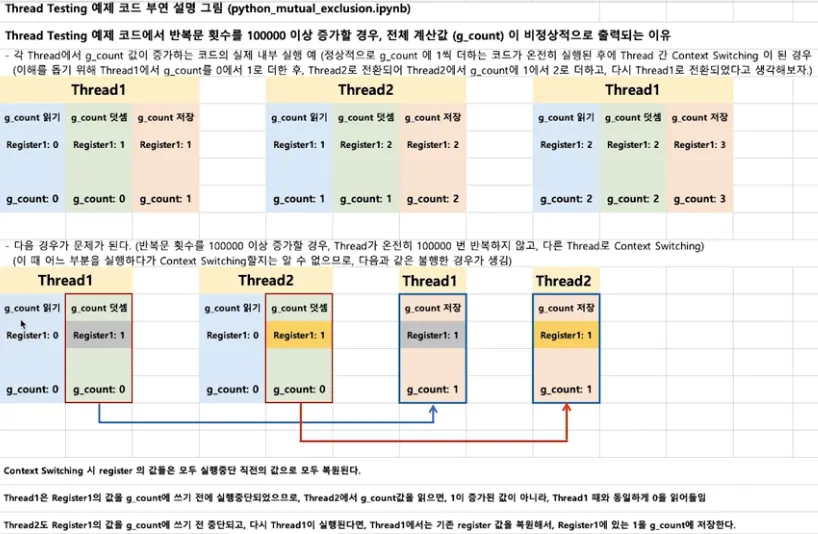
•
스레드 동기화 이슈 코드
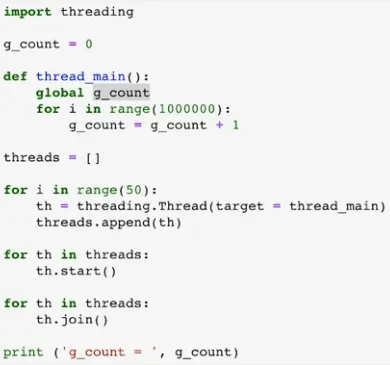
◦
동일 자원을 여러 스레드가 동시 수정 시 각 스레드 결과에 영향을 준다.
•
스레드 상호 배제 코드

◦
여러 스레드가 변경하는 공유 변수에 대해 Exclusive Access 필요
◦
어느 한 스레드가 공유 변수를 갱신하는 동안 다른 스레드가 동시 접근하지 못하도록 막아라
임계 자원과 임계 영역 그리고 Locking 메커니즘
•
임계 자원 (Critical Resource)
◦
여러 스레드가 동시에 접근하면 안되는 자원
◦
위 예제에선 g_count 전역 변수
•
임계 영역 (Ciritical Section)
◦
여러 스레드가 동시에 실행하면 안되는 코드 영역
◦
위 예제에선 lock.acquire()와 lock.release() 사이에 for문
•
임계 영역에 대한 접근을 막기 위해 Locking 메커니즘이 필요
◦
Mutex (binary semaphore)
▪
임계 영역에 하나의 스레드만 들어갈 수 있음
◦
Semaphore
▪
임계 영역에 여러 스레드가 들어갈 수 있음
▪
counter를 두어서 동시에 리소스에 접근할 수 있는 허용 가능한 스레드 수를 제어
Semaphore
•
기본 동작

◦
P : 검사 (임계 영역에 들어갈 때)
▪
S 값이 1 이상이면 임계 영역 진입 후 S 값 1 차감
▪
S 값이 0이면 대기
◦
V : 증가 (임계 영역에서 나올 때)
▪
S 값을 1 더하고 임계 영역을 나옴
◦
S : 세마포어 값 (초기 값만큼 여러 프로세스가 동시 임계 영역 접근 가능)
•
바쁜 대기 (busy waiting)
◦
S가 0인 경우 임계 영역에 들어가기 위한 반복문을 수행하는 과정
◦
loop를 계속 돌기 때문에 CPU를 계속 실행시켜 성능을 저하
•
대기 큐


◦
바쁜 대기를 해결하기 위한 운영체제의 방법
◦
S가 0인 경우 바쁜 대기 대신 대기 큐에 넣은 후 슬립
◦
S가 1보다 큰 경우 대기 큐에서 프로세스를 꺼내 재실행
•
POSIX Semaphore
◦
sem_open() : 세마포어를 생성
◦
sem_wait() : 임계 영역 접근 전 세마포어를 잠그고 세마포어가 잠겨있다면 풀릴 때까지 대기
◦
sem_post() : 공유 자원에 대한 접근이 끝났을 때 세마포어 잠금을 해제
교착 상태 (Deadlock)
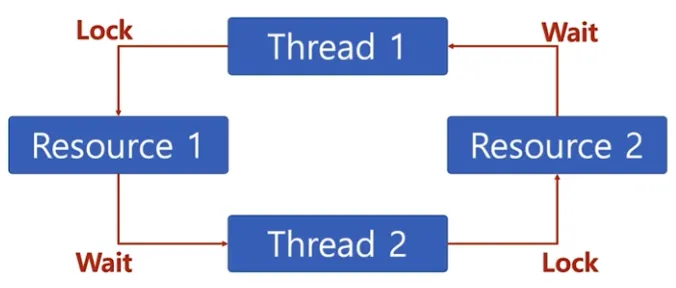
•
교착 상태란?
◦
두 개 이상의 작업이 서로 상대방의 작업이 끝나기만을 기다리고 있기 때문에 다음 단계로 진행하지 못하는 상태
◦
배치 처리 시스템에서는 일어나지 않고 멀티 프로세스 혹은 멀티 스레드에서 일어날 수 있음
•
발생 조건
◦
다음 네 가지 조건이 모두 성립될 때 교착 상태 발생 가능성이 있음
1.
상호배제 (Mutual Exclusion) : 프로세스들이 필요로 하는 자원에 대해 배타적인 통제권을 요구한다.
2.
점유대기 (Hold and Wait) : 프로세스가 할당된 자원을 가진 상태에서 다른 자원을 기다린다.
3.
비선점 (Non-Preemption) : 프로세스가 어떤 자원의 사용을 끝낼 때까지 그 자원을 뺏을 수 없다.
4.
순환대기 (Circular Wait) : 각 프로세스는 순환적으로 다음 프로세스가 요구하는 자원을 가지고 있다.
•
해결 방법
◦
교착 상태 예방
▪
4가지 조건 중 하나를 제거하는 방법
1.
상호배제 조건의 제거 : 임계 영역 제거
2.
점유대기 조건의 제거 : 한 번에 모든 필요 자원 점유 및 해제
3.
비선점 조건의 제거 : 선점 가능 기법을 만들어줌
4.
순환대기 조건의 제거 : 자원 유형에 따라 순서를 매김
◦
교착 상태 회피
▪
교착 상태 조건 중 1, 2, 3 제거 시 프로세스 실행 비효율성이 증대하므로 4만 제거
▪
순환대기 조건의 제거 : 자원 할당 순서를 정의하지 않음
◦
교착 상태 발견
▪
교착 상태가 발생했는지 점검하여 교착 상태에 있는 프로세스와 자원을 발견
◦
교착 상태 회복
▪
교착 상태를 일으킨 프로세스를 종료하거나 할당된 자원을 선점하여 프로세스나 자원을 회복
기아 상태 (Starvation)
•
기아 상태란?
◦
특정 프로세스의 우선 순위가 낮아서 원하는 자원을 계속 할당 받지 못하는 상태
•
교착 상태 vs 기아 상태
◦
교착 상태는 여러 프로세스가 동일 자원 점유를 요청할 때 발생
◦
기아 상태는 여러 프로세스가 부족한 자원을 점유하기 위해 경쟁할 때 특정 프로세스는 영원히 자원 할당이 안되는 경우를 주로 의미
•
해결 방법
◦
우선 순위 변경
▪
프로세스 우선 순위를 수시로 변경해서 각 프로세스가 높은 우선 순위를 가질 기회를 주기
▪
오래 기다린 프로세스의 우선 순위를 높여주기
▪
우선 순위가 아닌 요청 순서대로 처리하는 FIFO 기반 요청 큐 사용
가상 메모리 (Virtual Memory System)
•
가상 메모리의 필요성
◦
여러 프로세스 동시 실행 시 프로세스 메모리 영역 간에 침범 이슈
▪
프로세스 간 공간 분리로 프로세스 이슈가 전체 시스템에 영향을 주지 않음
◦
여러 프로세스 동시 실행 시 각 프로세스마다 메모리를 할당하기에는 메모리 크기의 한계
▪
리눅스는 하나의 프로세스가 4GB
▪
통상 메모리는 8GB, 16GB, 32GB
▪
폰노이만 구조 기반이므로 코드는 메모리에 반드시 있어야함
•
가상 메모리의 기본 아이디어
◦
프로세스는 가상 주소를 사용하고 실제 해당 주소에서 데이터를 읽고 쓸 때만 물리 주소로 바꿔줌
◦
가상 주소 (virtual address)
▪
프로세스가 참조하는 주소로 0~4GB의 주소
◦
물리 주소 (physical address)
▪
실제 메모리 주소로 RAM의 주소
MMU (Memory Management Unit)
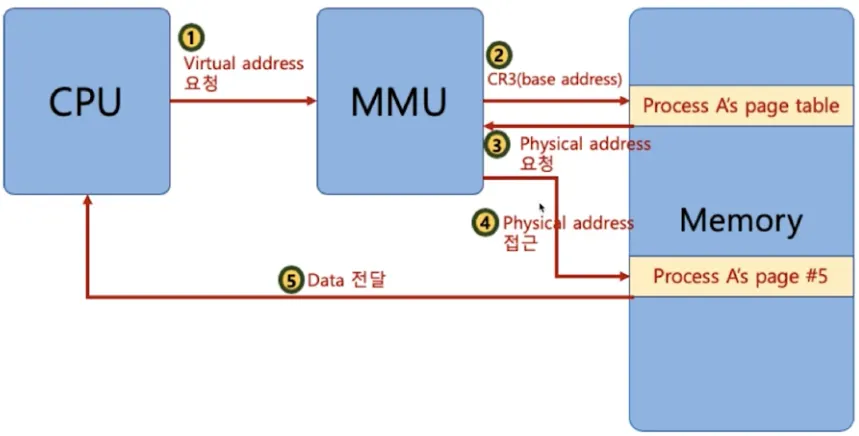
•
가상 메모리 주소에 접근이 필요할 때 해당 주소를 물리 주소값으로 변환해주는 하드웨어 장치
◦
하드웨어 장치를 이용해야 주소 변환이 빠르기 때문에 별도 장치를 둠
•
CPU는 가상 메모리를 다루고 실제 해당 주소 접근 시 MMU 하드웨어 장치를 통해 물리 메모리 접근
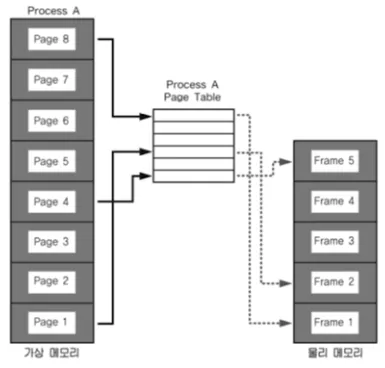
페이징 시스템 (Paging System)
•
Paging
◦
크기가 동일한 Page로 가상 주소 공간과 이에 매칭하는 물리 주소 공간을 관리
◦
Page 번호를 기반으로 가상 주소/물리 주소 매핑 정보를 기록/사용
◦
하드웨어 지원이 필요
▪
Intel x86 (32bit) : 4KB, 2MB, 1GB
▪
Linux : 4KB
•
Page Table
◦
프로세스(4GB)의 PCB에 Page Table 구조체를 가리키는 주소가 들어 있음
◦
Page Table에는 가상 주소와 물리 주소간 매핑 정보가 있음
◦
PCB 등에서 해당 Page Table 접근 가능하고 관련 정보는 물리 메모리에 적재
•
구조
◦
page 또는 page frame
▪
고정된 크기의 block (Linux는 4KB)
◦
virtual address

▪
p : 가상 메모리 페이지
▪
d : p 안에서 참조하는 위치
▪
page가 4KB인 경우 가상 주소는 32bit이고 0~11bit는 변위(d), 12bit부터 나머지는 페이지 번호
▪
p + d → 실제 물리 메로리의 해당 데이터 위치
◦
valid-invalid bit
▪
Page Table에 등록된 page가 실제로 물리 주소에 존재하는지 확인하는 값
•
동작
◦
프로세스 생성 시 Page Table 정보를 생성하는 동작
1.
프로세스 구동 시 해당 Page Table의 base 주소가 별도 레지스터(CR3)에 저장
2.
CPU가 가상 주소 접근 시 MMU가 Page Table의 base 주소를 접근해서 물리 주소를 가져옴
◦
CPU가 프로세스의 특정 가상 주소 엑세스를 하기 위한 동작
1.
MMU가 해당 프로세스의 Page Table에 해당 가상 주소가 포함된 Page 번호가 있는지 확인
2.
Page 번호가 있으면 이 Page가 매핑된 첫 물리 주소를 알아내고 (p’)
3.
p’ + d 가 실제 물리 주소가 됨
다중 단계 페이징 시스템
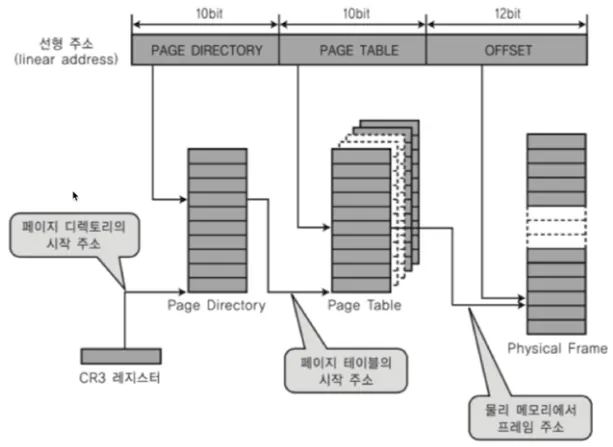
•
32bit 시스템에서 4KB 페이지를 위한 페이징 시스템
◦
하위 12bit는 오프셋
◦
상위 20bit가 페이징 번호이므로 2^20 (1048576) 개의 페이지 정보가 필요함
◦
굳이 상위 20bit를 모두 페이징 번호로 사용할 필요가 없음
•
페이징 정보를 단계를 나누어 생성
◦
필요 없는 페이지는 생성하지 않으면 공간 절약 가능
◦
상위 20bit 중 10bit는 Page Directory, 나머지 10bit는 Page Table을 나타냄
◦
CR3 레지스터는 Page Directory의 base 주소를 가짐
◦
Linux는 기본적으로 3단계, 최근엔 4단계
TLB (Translation Lookaside Buffer)
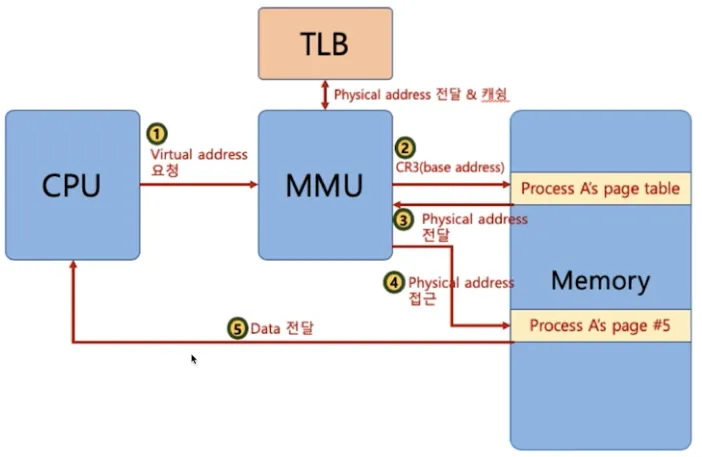
•
메인 메모리를 엑세스하는 시간이 오래 걸리므로 페이지 정보를 캐싱하기 위한 하드웨어
페이징 시스템과 공유 메모리
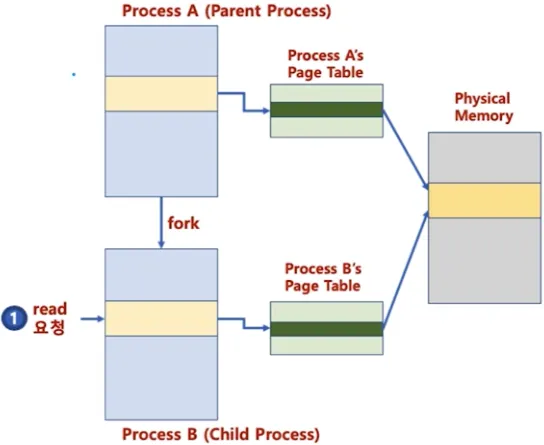
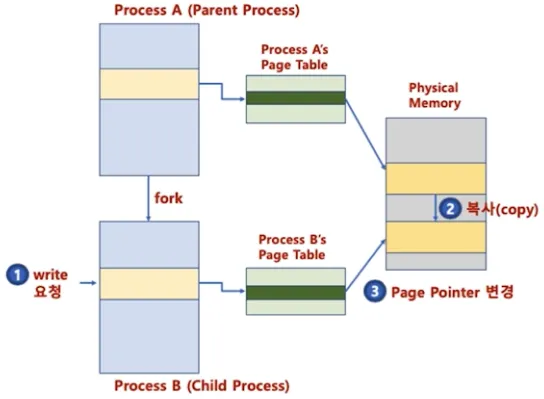
•
프로세스간 동일한 물리 주소를 가리킬 수 있음
◦
물리 메모리 공간 공유로 공간 절약
•
물리 주소 데이터 변경 시도 시 그 때 물리 주소를 복사하고 변경
◦
메모리 할당 시간 절약으로 프로세스 생성 시간 절약
요구 페이징 (Demand Paging)
•
요구 페이징이란?
◦
프로세스 모든 데이터를 메모리로 적재하지 않고 실행 중 필요한 시점에서만 메모리로 적재
◦
더 이상 필요하지 않은 Page는 다시 저장매체에 저장하는 페이지 교체 알고리즘 필요
•
Page Fault Interrupt
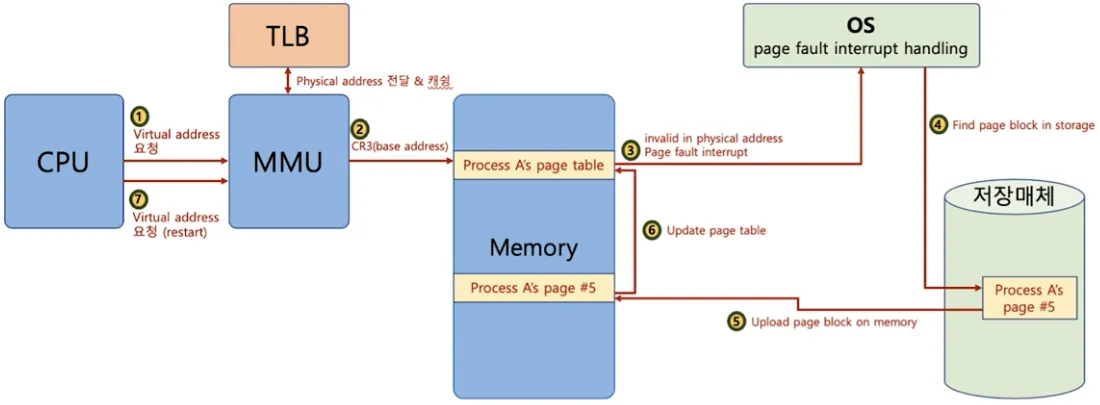
◦
valid-invalid bit의 값이 invalid면 인터럽트를 발생시키고 운영체제는 해당 Page를 메모리에 적재
•
고찰
◦
페이지 폴트가 자주 일어나면?
▪
실행 되기 전에 해당 페이지를 물리 메모리에 올려야함 → 시간이 오래 걸림
◦
페이지 폴트가 안 일어나게 하려면?
▪
향후 실행/참조될 코드/데이터를 미리 물리 메모리에 올려야함 → 앞으로 있을 일을 예측 (신의 영역)
페이지 교체 알고리즘 (Page Replacement Policy)
•
운영체제가 특정 페이지를 물리 메모리에 올려야 하는데 물리 메모리가 다 차있는 경우
◦
기존 페이지 중 하나를 물리 메모리에서 저장 매체로 내리고 (저장)
◦
새로운 페이지를 해당 물리 메모리 공간에 올린다. (교체)
•
FIFO(First-In, First-Out) 알고리즘
◦
가장 먼저 들어온 페이지를 내리기
•
OPT(Optimal) 알고리즘
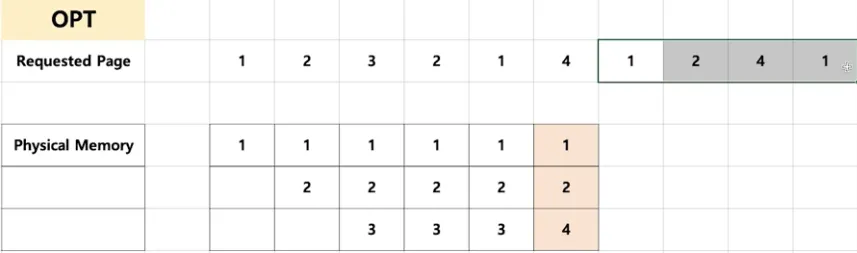
◦
최적 페이지 교체 알고리즘으로 앞으로 가장 오랫동안 사용하지 않을 페이지를 내리기
◦
일반 OS에서는 구현 불가
•
LRU(Least Recently Used) 알고리즘
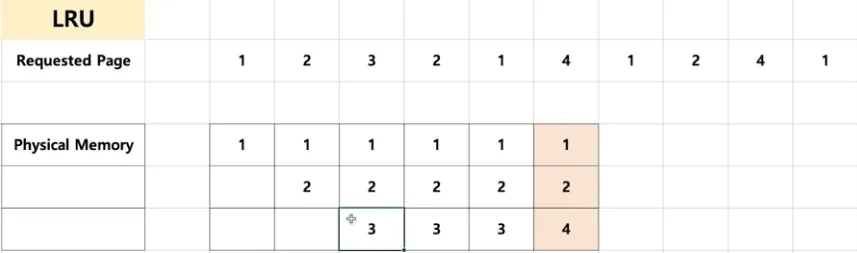
◦
가장 오래 전에 사용된 페이지를 교체
◦
OPT 교체 알고리즘이 구현이 불가하므로 과거 기록을 기반으로 시도
•
LFU(Least Frequently Used) 알고리즘
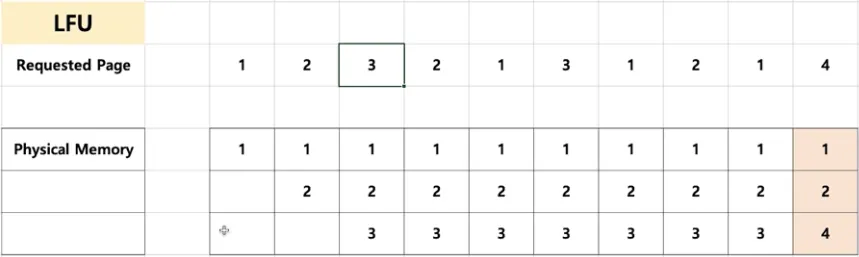
◦
가장 적게 사용된 페이지를 교체
•
NUR(Not Used Recently) 알고리즘
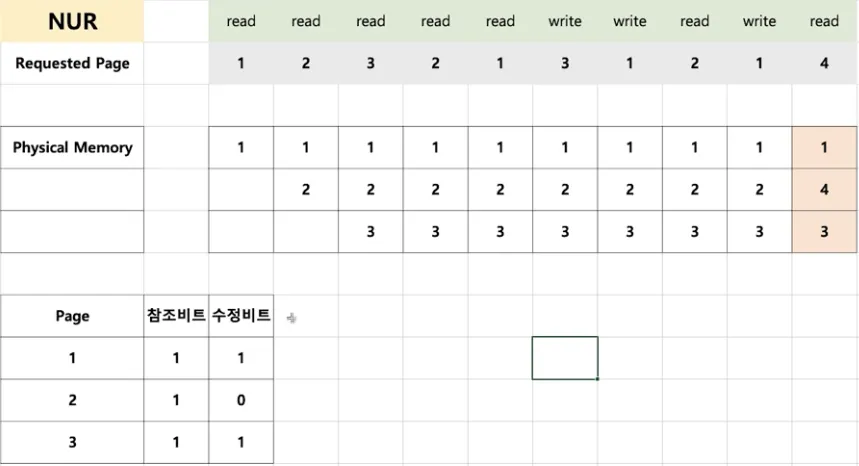
◦
LRU와 마찬가지로 최근에 사용하지 않은 페이지부터 교체
◦
각 페이지마다 참조 비트(R), 수정 비트(M)를 둠
◦
(R,M)이 (0,0), (0,1), (1,0), (1,1)인 순서대로 페이지 교체
스레싱 (Thrashing)
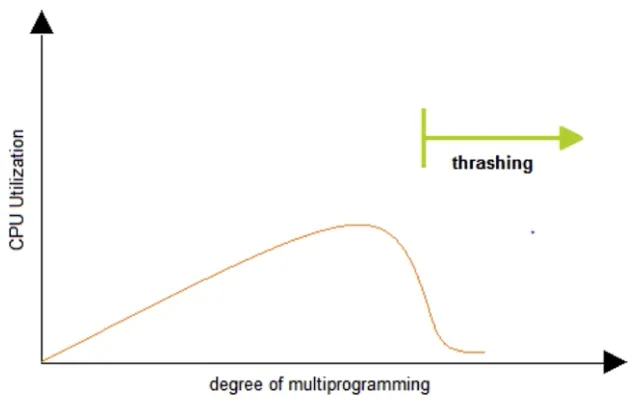
•
반복적으로 Page Fault Interrupt가 발생해서 과도하게 페이지 교체 작업이 일어나 실제로는 아무 일도 하지 못하는 상황
•
메모리를 늘림으로써 스레싱 현상을 완화할 수 있음
세그멘테이션 (Segmentation)
•
세그멘테이션 기법
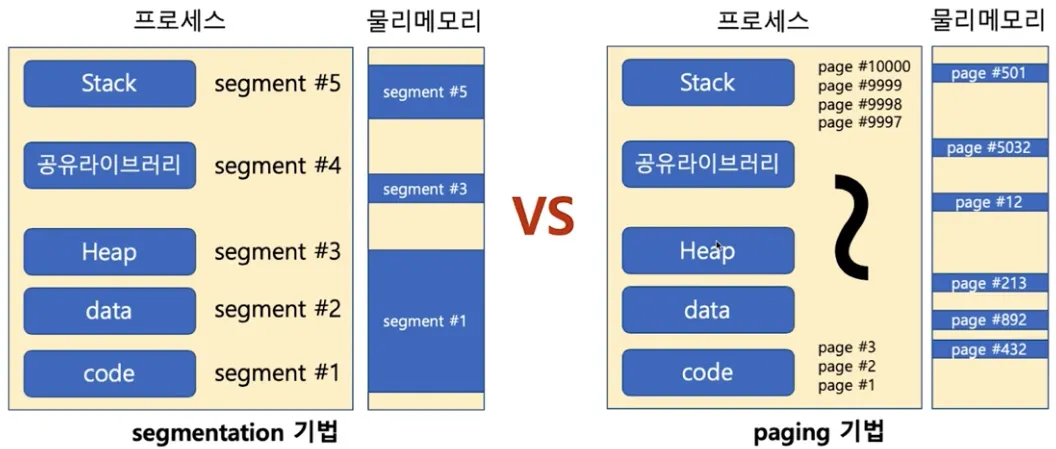
◦
가상 메모리를 서로 크기가 다른 논리적 단위인 세그먼트(Segment)로 분할
◦
크기가 다른 세그먼트 단위로 물리 메모리에 로딩
◦
ex) x86 리얼모드
x86 리얼모드란?
▪
CS(Code Segment), DS(Data Segment), SS(Stack Segment), ES(Extra Segment)로 세그먼트를 나누어 메모리 접근
•
세그먼트 가상주소
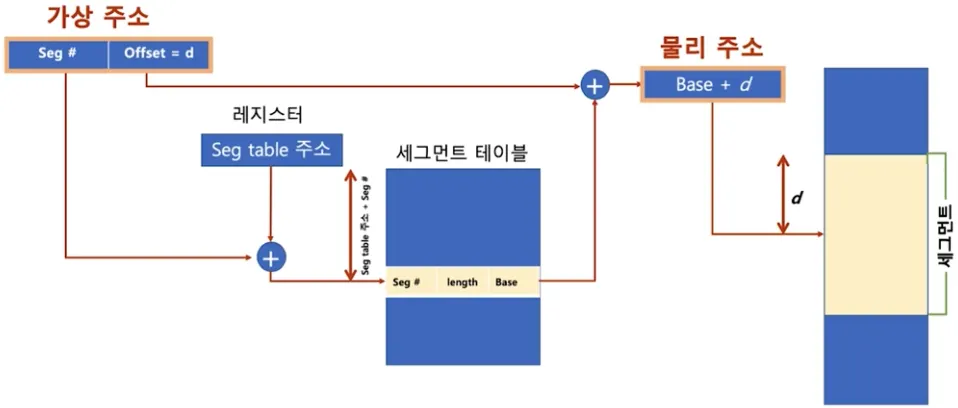
◦
v = (s, d)
▪
s : 세그먼트 번호
▪
d : 블록 내 세그먼트의 변위(오프셋)
페이징 기법 vs 세그멘테이션 기법
•
내부 단편화 (페이징 기법)
◦
페이지 블록만큼 데이터가 딱 맞게 채워져있지 않을 경우 공간 낭비
•
외부 단편화 (세그멘테이션 기법)
◦
물리 메모리가 원하는 연속된 크기의 메모리를 제공해주지 못하는 경우
•
페이징/세그멘테이션 기법 모두 하드웨어 지원 필요
◦
다양한 컴퓨터 시스템에 이식성을 중요시하는 리눅스는 페이징 기법을 기반으로 구현
파일 시스템
•
파일 시스템이란?
◦
운영체제가 저장매체에 파일을 쓰기 위한 자료구조 또는 알고리즘
•
파일 시스템이 만들어진 이유
1.
0과 1의 데이터를 비트로 관리하여 주소를 각각 부여하기엔 오버헤드가 너무 큼
2.
블록 단위로 관리하여 부여할 주소를 줄임 (보통 4KB)
3.
블록마다 고유 번호를 부여해서 관리
4.
사용자가 각 블록 고유 번호를 관리하기 어려우므로 추상적(논리적) 객체가 필요
5.
사용자는 파일 단위로 관리하며 각 파일에는 블록 단위로 관리
•
저장 매체에 효율적으로 파일을 저장하는 방법
1.
가능한 연속적인 공간에 파일을 저장하는 것이 좋음
2.
외부 단편화, 파일 사이즈 변경 문제로 불연속 공간에 파일 저장 기능 지원 필요
•
블럭 체인 : 블럭을 Linked List로 연결 (끝 블럭 찾기 어려움)
•
인덱스 블럭 기법 : 각 블럭에 대한 위치 정보를 기록 (끝 블럭 찾기 쉬움)
•
다양한 파일 시스템
◦
Windows
▪
FAT, FAT32, NTFS
▪
블럭 위치를 FAT라는 자료 구조에 기록
◦
Linux(Unix)
▪
ext2, ext3, ext4
▪
일종의 인덱스 블럭 기법인 inode 방식 사용
•
파일 시스템과 시스템 콜
◦
동일한 시스템 콜을 사용해서 다양한 파일 시스템을 지원 가능하도록 구현
◦
read/write 시스템 콜 호출 시 각 기기 및 파일 시스템에 따라 실질적인 처리를 담당하는 함수를 구현
◦
파일을 실제로 어떻게 저장할지는 다를 수 있음
inode 방식 파일 시스템
•
기본 구조
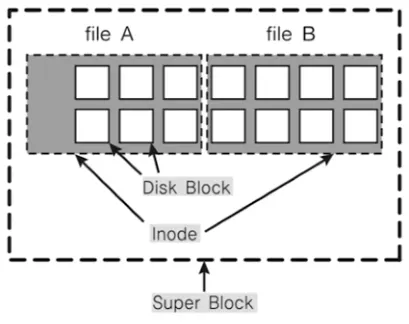
◦
수퍼 블럭
▪
파일 시스템 정보 및 파티션 정보 포함
◦
아이노드 블럭
▪
파일 상세 정보
◦
디스크(데이터) 블럭
▪
실제 데이터로 4KB의 공간을 가짐
•
파일
◦
inode 고유 값과 자료 구조에 의해 주요 정보 관리
◦
‘파일이름:inode’ 로 파일 이름은 inode 번호와 매칭
◦
파일 시스템에서는 inode를 기반으로 파일 엑세스
◦
inode 기반 메타 데이터 저장
•
inode 구조
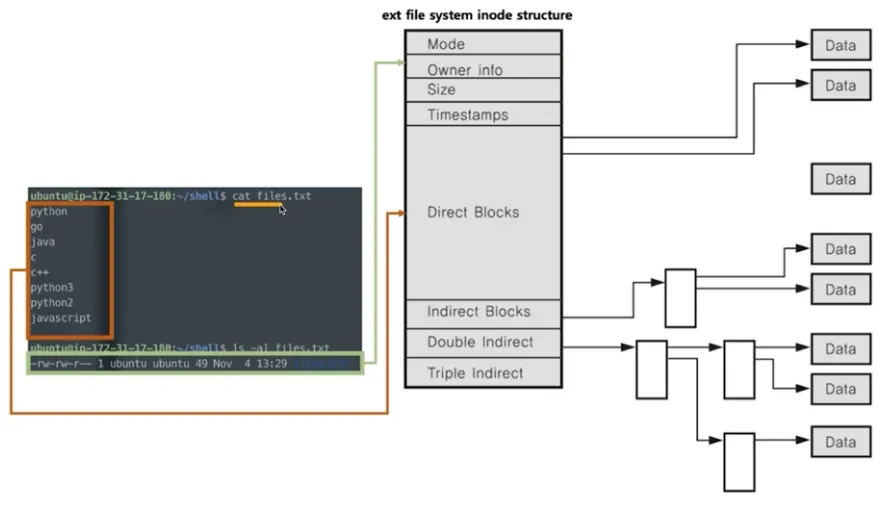
◦
inode 기반 메타 데이터
▪
파일 권한, 소유자 정보, 파일 사이즈, 생성 시간 등 시간 관련 정보, 데이터 저장 위치
◦
Direct Blocks
▪
일반적으로 12개의 주소 공간이 실제 데이터 블럭의 주소를 가리킴
◦
Single Indirect (Indirect Blocks)
▪
실제 데이터 블럭의 주소(4byte)로 하나의 데이터 블럭(4KB)을 나눈 갯수 만큼의 주소를 가짐 (4MB)
◦
Double Indirect
▪
Single Indirect의 주소(4byte)로 하나의 Single Indirect 블럭(4KB)을 나눈 갯수 만큼의 주소를 가짐 (4GB)
◦
Triple Indirect
▪
Double Indirect의 주소(4byte)로 하나의 Double Indirect 블럭(4KB)을 나눈 갯수 만큼의 주소를 가짐 (4TB)
•
디렉토리 엔트리
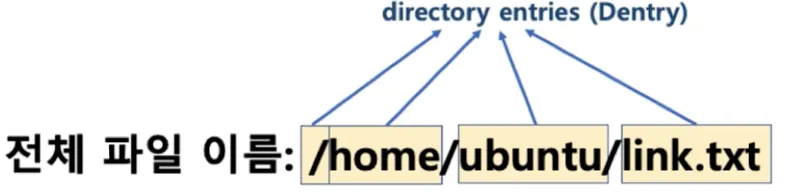
◦
리눅스 파일 탐색 (/home/ubuntu/link.txt)
1.
각 디렉토리 엔트리(dentry)를 탐색
a.
각 엔트리는 해당 디렉토리 파일/디렉토리 정보를 갖고 있음
2.
‘/’ dentry에서 ‘home’을 찾고, ‘home’에서 ‘ubuntu’를 찾고, ‘ubuntu’에서 link.txt 파일 이름에 해당하는 inode를 얻음
가상 파일 시스템 (Virtual File System)
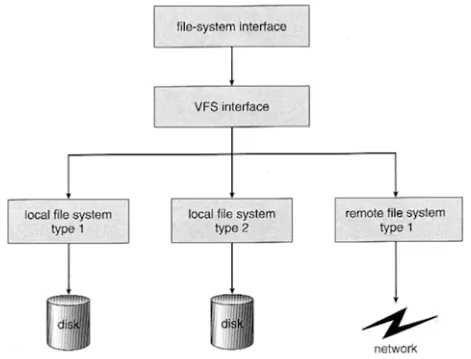
•
Network 등 다양한 기기도 동일한 파일 시스템 인터페이스를 통해 관리 가능
•
read/write 시스템 콜 사용, 각 기기별 read_spec/write_spec 코드 구현 (운영체제 내부)
리눅스의 철학과 특수 파일
•
모든 것은 파일이다
◦
모든 인터랙션은 파일을 읽고 쓰는 것처럼 이루어져 있음
◦
마우스, 키보드와 같은 모든 디바이스 관련된 기술로 파일과 같이 다루어짐
◦
모든 자원에 대한 추상화 인터페이스로 파일 인터페이스를 활용
•
디바이스
◦
블럭 디바이스 (Block Device)
▪
HDD, CD/DVD 와 같이 블럭 또는 섹터 등 정해진 단위로 데이터 전송
▪
I/O 송수신 속도가 높음
◦
캐릭터 디바이스 (Character Device)
▪
키보드, 마우스 등 byte 단위 데이터 전송
▪
I/O 송수신 속도가 낮음
Booting
•
부팅이란?
◦
컴퓨터를 켜서 동작시키는 절차
•
Boot 프로그램이란?
◦
운영체제 커널을 Storage에서 특정 주소의 물리 메모리로 복사하고 커널의 처음 실행 위치로 PC를 가져다 놓는 프로그램
•
부팅 과정
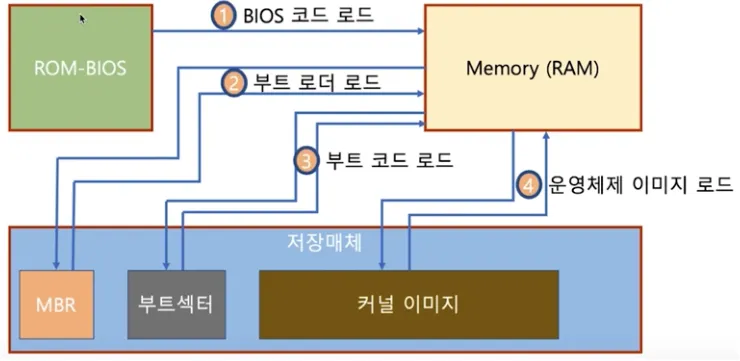
1.
CPU가 ROM의 BIOS의 주소를 읽음
2.
ROM은 실제 BIOS 프로그램을 로드하여 RAM(Memory)에 올림
3.
BIOS 프로그램이 하드웨어 초기화
4.
BIOS 프로그램이 저장매체 맨 앞에 있는 데이터인 MBR(Master Boot Record)을 읽어 Bootstrap Loader와 Partition Table을 RAM(Memory)로 읽어옴
5.
읽어 온 Partition Table에서 Boot Sector를 읽어 Boot Code를 RAM(Memory)로 읽어옴
6.
Boot Code를 통해 파티션 내의 커널 이미지의 위치를 찾은 후 RAM(Memory)로 읽어옴
7.
커널 이미지를 읽으며 운영체제 실행
가상 머신 (Virtual Machine)
•
가상 머신이란?
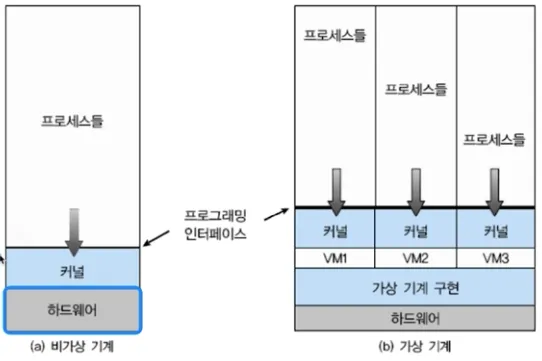
◦
하나의 하드웨어 (CPU, Memory 등)에 다수의 운영체제를 설치하고 개별 컴퓨터처럼 동작하도록 하는 프로그램
•
Virtual Machine Type1 VS Virtual Machine Type2
◦
Virtual Machine Type1 (native 또는 bare metal)
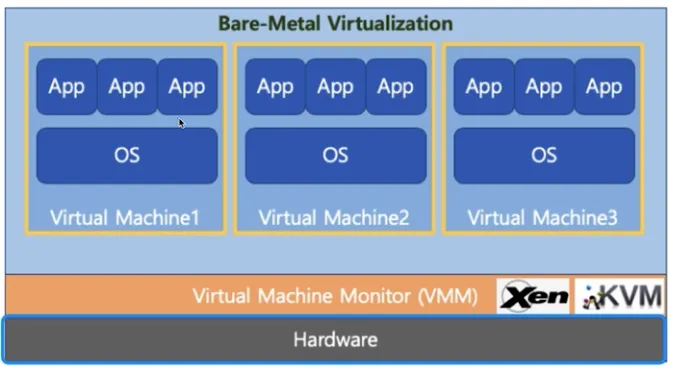
▪
운영 체제와 응용 프로그램을 물리적 하드웨어에서 분리하는 프로세스
▪
하이퍼 바이저 또는 버츄얼 머신 모니터 (VMM) 라고 하는 소프트웨어가 하드웨어에서 직접 구동
▪
ex) Xen, KVM
◦
Virtual Machine Type2
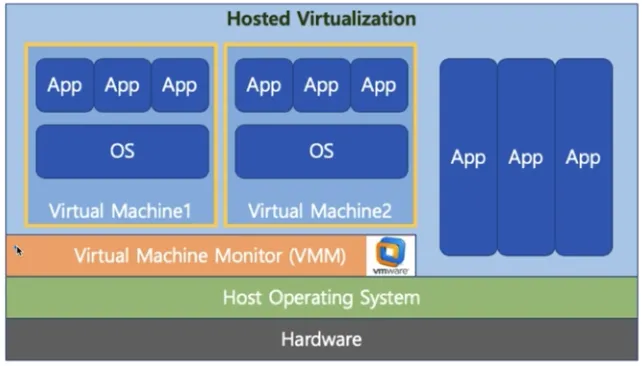
▪
하이퍼 바이저 또는 버츄얼 머신 모니터 (VMM) 라고 하는 소프트웨어가 Host OS 상위에 설치
▪
ex) VMWare, Parallels Desktop (Mac)
•
전가상화 VS 반가상화
◦
전가상화 (Full Virtualization)
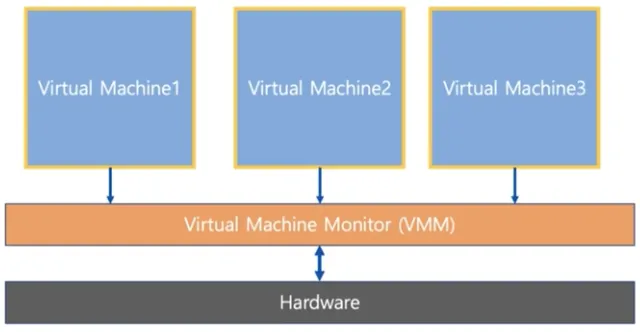
▪
각 가상머신이 하이퍼 바이저를 통해서 하드웨어와 통신
▪
하이퍼 바이저는 마치 하드웨어인 것처럼 동작하므로 가상머신의 OS는 자신이 가상머신인 상태인지 모름
◦
반가상화 (Half Virtualization)
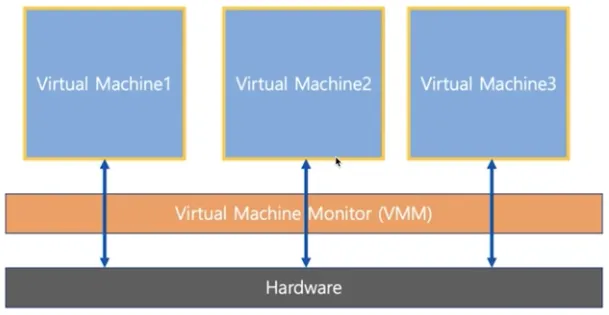
▪
각 가상머신에서 직접 하드웨어와 통신
▪
각 가상머신에 설치되는 OS는 가상머신인 경우 이를 인지하고 각 명령에 하이퍼 바이저 명령을 추가해서 하드웨어와 통신
•
Docker
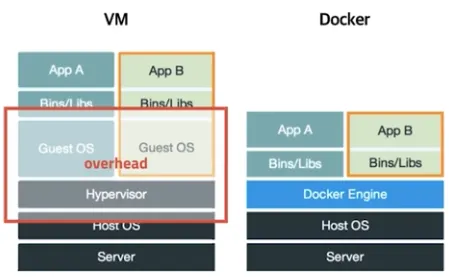
◦
가상 머신은 컴퓨터 하드웨어를 가상화 (하드웨어 전체 추상화)
▪
하이퍼 바이저 사용, 추가 OS 필요 등 성능 저하 이슈 존재
◦
Docker는 운영체제 레벨에서 별도로 분리된 실행 환경을 제공 (커널 추상화)
▪
마치 리눅스를 처음 설치 했을 때와 유사한 실행 환경을 만들어주는 리눅스 컨테이너 기술 기반
▪
리눅스 컨테이너 기술이므로 MacOS나 Windows에 설치할 경우는 가상 머신 기반 제공
•
Java Virtual Machine
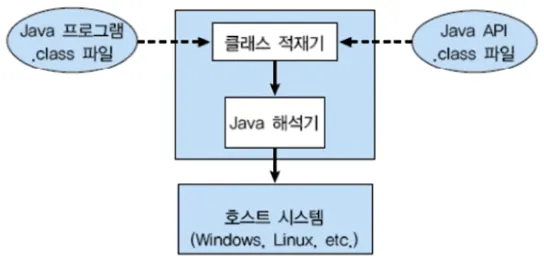
◦
가상 머신과는 다른 목적 (응용 프로그램 레벨 가상화)
◦
Java 컴파일러는 CPU Dependency를 가지지 않는 bytecode를 생성
◦
이 bytecode를 Java Virtual Machine에서 실행
◦
각 운영체제를 위한 Java Virtual Machine 프로그램이 존재