
Chapter1. 도메인 모델 시작하기
도메인이란?
개발자 입장에서 바라보면 온라인 서점은 구현해야 할 소프트웨어의 대상이 된다.
온라인 서점 소프트웨어는 온라인으로 책을 판매하는 데 필요한 상품 조회, 구매, 결제, 배송 추적 등의 기능을 제공해야 한다.
이때 온라인 서점은 소프트웨어로 해결하고자 하는 문제 영역, 즉 도메인에 해당한다.
한 도메인은 다시 하위 도메인으로 나눌 수 있다.
예를 들어 온라인 서점 도메인은 몇 개의 하위 도메인으로 나눌 수 있다.
특정 도메인을 위한 소프트웨어라고 해서 도메인이 제공해야 할 모든 기능을 직접 구현하는 것은 아니다.
많은 온라인 쇼핑몰이 자체적으로 배송 시스템을 구축하기 보다는 외부 배송 업체의 시스템을 사용하고 배송 추적 정보를 제공하는 데 필요한 기능만 일부 연동한다.
도메인 전문가와 개발자 간 지식 공유
요구사항은 개발의 첫 단추와 같다.
첫 단추를 잘못 끼우면 모든 단추가 잘못 끼워지듯이 요구사항을 올바르게 이해하지 못하면 요구하지 않은 엉뚱한 기능을 만들게 된다.
요구사항을 올바르게 이해하는 것이 중요하다.
요구사항을 올바르게 이해하려면 개발자와 전문가가 직접 대화해야 하며 도메인 전문가 만큼은 아니겠지만 이해관계자와 개발자도 도메인 지식을 갖춰야 한다.
도메인 모델
도메인 모델을 사용하면 여러 관계자들이 동일한 모습으로 도메인을 이해하고 도메인 지식을 공유하는 데 도움이 된다.
도메인을 이해하려면 도메인이 제공하는 기능과 도메인의 주요 데이터 구성을 파악해야 하는데, 이런 면에서 기능과 데이터를 함께 보여주는 객체 모델은 도메인을 모델링하기에 적합하다.
도메인 모델은 기본적으로 도메인 자체를 이해하기 위한 개념 모델이다.
개념 모델을 이용해서 바로 코드를 작성할 수 있는 것은 아니기에 구현 기술에 맞는 구현 모델이 따로 필요하다.
개념 모델과 구현 모델은 서로 다른 것이지만 구현 모델이 개념 모델을 최대한 따르도록 할 수는 있다.
개념 모델은 순수하게 문제를 분석한 결과물이다.
개념 모델은 데이터베이스, 트랜잭션 처리, 성능, 구현 기술과 같은 것을 고려하고 있지 않기 때문에 실제 코드를 작성할 때 개념 모델을 있는 그대로 사용할 수 없다.
그래서 개념 모델을 구현 가능한 형태의 모델로 전환하는 과정을 거치게 된다.
따라서 처음부터 완벽한 개념 모델을 만들기보다는 전반적인 개요를 알 수 있는 수준으로 개념 모델을 작성해야 한다.
프로젝트 초기에는 개요 수준의 개념 모델로 도메인에 대한 전체 윤곽을 이해하는데 집중하고, 구현하는 과정에서 개념 모델을 구현 모델로 점진적으로 발전시켜 나가야 한다.
도메인 모델 패턴
일반적인 애플리케이션의 아키텍처는 표현, 응용, 도메인, 인프라스트럭처 네 개의 영역으로 구성된다.
영역 | 설명 |
사용자 인터페이스
또는 표현 | 사용자의 요청을 처리하고 사용자에게 정보를 보여준다.
여기서 사용자는 소프트웨어를 사용하는 사람뿐만 아니라 외부 시스템일 수도 있다. |
응용 | 사용자가 요청한 기능을 실행한다.
업무 로직을 직접 구현하지 않으며 도메인 계층을 조합해서 기능을 실행한다. |
도메인 | 시스템이 제공할 도메인 규칙을 구현한다. |
인프라스트럭처 | 데이터베이스나 메시징 시스템과 같은 외부 시스템과의 연동을 처리한다. |
도메인 계층은 도메인의 핵심 규칙을 구현한다.
주문 도메인의 경우 ‘출고 전에 배송지를 변경할 수 있다’ 라는 규칙과 ‘주문 취소는 배송 전에만 할 수 있다’라는 규칙을 구현한 코드가 도메인 계층에 위치하게 된다.
이런 도메인 규칙을 객체 지향 기법으로 구현하는 패턴이 도메인 모델 패턴이다.
도메인 모델 도출
도메인을 모델링할 때 기본이 되는 작업은 모델을 구성하는 핵심 구성요소, 규칙, 기능을 찾는 것이다.
이 과정은 요구사항에서 출발한다.
•
최소 한 종류 이상의 상품을 주문해야 한다.
•
한 상품은 한 개 이상 주문할 수 있다.
•
총 주문 금액은 각 상품의 구매 가격 합을 모두 더한 금액이다.
public class Order {
private List<OrderLine> orderLines;
private Money totalAmounts;
public Order(List<OrderLine> orderLines) {
setOrderLines(orderLines);
}
private void setOrderLines(List<OrderLines> orderLines) {
verifyAtLeastOrMoreOrderLines(orderLines);
this.orderLines = orderLines;
calculateTotalAmounts();
}
private void verifyAtLeastOrMoreOrderLines(List<OrderLine> orderLines) {
if (orderLines == null || orderLines.isEmpty()) {
throw new IllegalArgumentException("no OrderLine");
}
}
private void calculateTotalAmounts() {
int sum = orderLines.stream()
.mapToInt(x -> x.getAmounts())
.sum();
this.totalAmounts = new Money(sum);
}
}
Java
복사
Order는 한 개 이상의 OrderLine을 가질 수 있으므로 Order를 생성할 때 OrderLine 목록을 List로 전달한다.
생성자에서 호출하는 setOrderLines() 메서드는 요구사항에 정의한 제약 조건을 검사한다.
요구사항에 따르면 최소 한 종류 이상의 상품을 주문해야 하므로 verifyAtLeastOrMoreOrderLines() 메서드를 이용해서 OrderLine이 한 개 이상 존재하는지 검사한다.
또한 calculateTotalAmounts() 메서드를 이용해서 총 주문 금액을 계산한다.
엔티티와 밸류
도출한 모델은 크게 엔티티와 밸류로 구분할 수 있다.
엔티티와 밸류를 제대로 구분해야 도메인을 올바르게 설계하고 구현할 수 있기 때문에 이 둘의 차이를 명확하게 이해하는 것은 도메인을 구현하는데 있어 중요하다.
엔티티
엔티티의 가장 큰 특징은 식별자를 가진다는 것이다.
식별자는 엔티티 객체마다 고유해서 각 엔티티는 서로 다른 식별자를 갖는다.
밸류 타입
밸류 타입은 개념적으로 완전한 하나를 표현할 때 사용한다.
밸류 객체의 데이터를 변경할 때는 기존 데이터를 변경하기보다는 변경한 데이터를 갖는 새로운 밸류 객체를 생성하는 방식을 선호한다.
도메인 모델에 set 메서드 넣지 않기
도메인 모델에 get/set 메서드를 무조건 추가하는 것은 좋지 않은 버릇이다.
set 메서드는 도메인의 핵심 개념이나 의도를 코드에서 사라지게 하며, 도메인 객체를 생성할 때 온전하지 않은 상태가 될 수 있다.
도메인 객체가 불완전한 상태로 사용되는 것을 막으려면 생성 시점에 필요한 것을 전달해 주어야 한다.
즉 생성자를 통해 필요한 데이터를 모두 받아야 한다.
도메인 용어와 유비쿼터스 언어
코드를 작성할 때 도메인에서 사용하는 용어는 매우 중요하다.
도메인에서 사용하는 용어를 코드에 반영하지 않으면 그 코드는 개발자에게 코드의 의미를 해석해야 하는 부담을 준다.
에릭 에반스는 도메인 주도 설계에서 언어의 중요함을 강조하기 위해 유비쿼터스 언어라는 용어를 사용했다.
전문가, 관계자, 개발자가 도메인과 관련된 공통의 언어를 만들고 이를 대화, 문서, 도메인 모델, 코드, 테스트 등 모든 곳에서 같은 용어를 사용한다.
이렇게 하면 소통 과정에서 발생하는 용어의 모호함을 줄일 수 있고 개발자는 도메인과 코드 사이에서 불필요한 해석 과정을 줄일 수 있다.
Chapter2. 아키텍처 개요
네 개의 영역
표현, 응용, 도메인, 인프라스트럭처는 아키텍처를 설계할 때 출현하는 전형적인 네 가지 영역이다.
웹 애플리케이션의 표현 영역은 HTTP 요청을 응용 영역이 필요로 하는 형식으로 변환해서 응용 영역에 전달하고 응용 영역의 응답을 HTTP 응답으로 변환하여 전송한다.
응용 영역은 시스템이 사용자에게 제공해야 할 기능을 구현하며 기능을 구현하기 위해 도메인 영역의 도메인 모델을 사용한다.
도메인 영역은 도메인 모델을 구현하며 도메인 모델은 도메인의 핵심 로직을 구현한다.
인프라스트럭처 영역은 구현 기술에 대한 것을 다루며 논리적인 개념을 표현하기보다는 실제 구현을 다룬다.
계층 구조 아키텍처
네 영역을 구성할 때 가장 많이 사용하는 아키텍처가 아래와 같은 계층 구조이다.
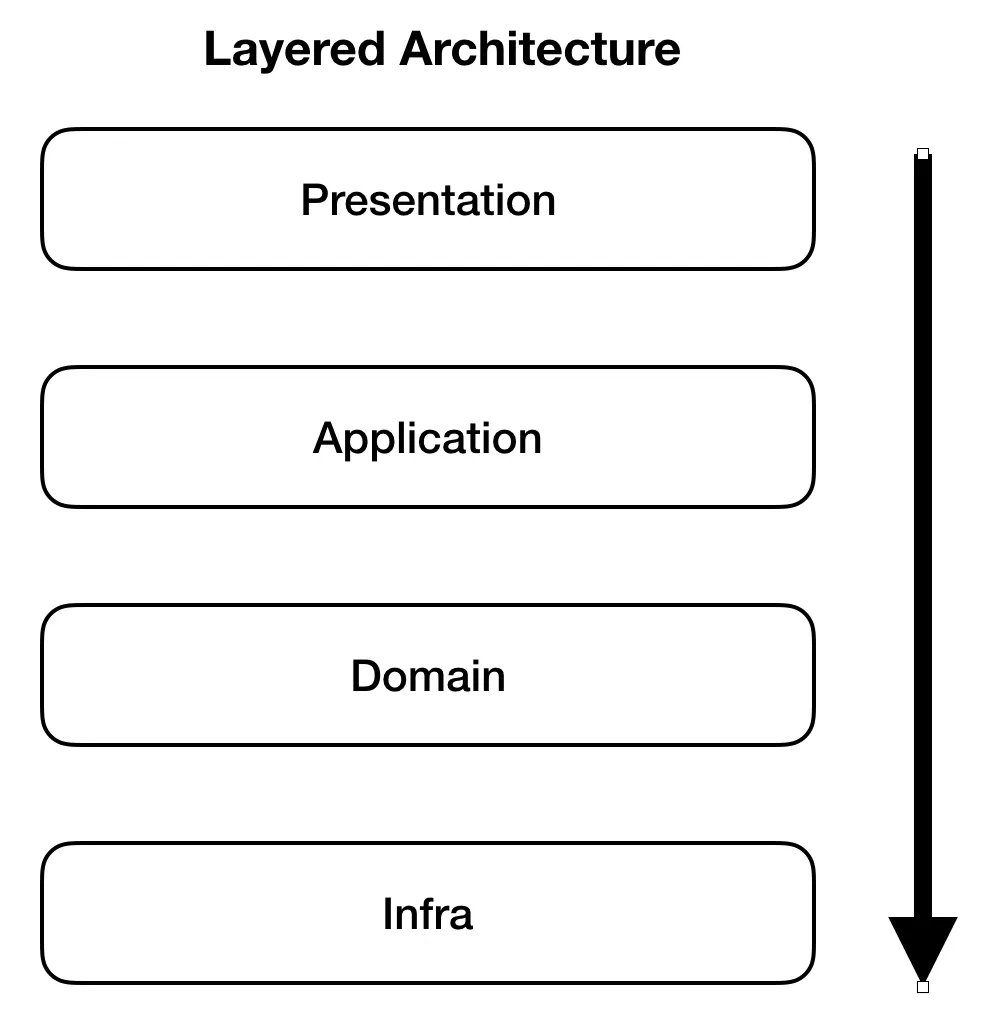
계층 구조는 그 특성상 상위 계층에서 하위 계층으로의 의존만 존재하고 하위 계층은 상위 계층에 의존하지 않는다.
계층 구조를 엄격하게 적용한다면 상위 계층은 바로 아래의 계층에만 의존을 가져야 하지만 구현의 편리함을 위해 계층 구조를 유연하게 적용하기도 한다.
하지만 짚고 넘어가야 할 것은 표현, 응용, 도메인 계층이 상세한 구현 기술을 다루는 인프라스트럭처 계층에 종속된다는 점이다.
DIP
고수준 모듈이 제대로 동작하려면 저수준 모듈을 사용해야 한다.
그런데 고수준 모듈이 저수준 모듈을 사용하면 앞서 계층 구조 아키텍처에서 언급했던 두 가지 문제, 즉 구현 변경과 테스트가 어렵다는 문제가 발생한다.
DIP는 이 문제를 해결하기 위해 저수준 모듈이 고수준 모듈에 의존하도록 바꾼다.
DIP 주의사항
DIP를 잘못 생각하면 단순히 인터페이스와 구현 클래스를 분리하는 정도로 받아들일 수 있다.
DIP의 핵심은 고수준 모듈이 저수준 모듈에 의존하지 않도록 하기 위함인데 DIP를 적용한 결과 구조만 보고 저수준 모듈에서 인터페이스를 추출하는 경우가 있다.
DIP를 적용할 때 하위 기능을 추상화한 인터페이스는 고수준 모듈 관저에서 도출한다.
DIP와 아키텍처
인프라스트럭처 영역은 구현 기술을 다루는 저수준 모듈이고 응용 영역과 도메인 영역은 고수준 모듈이다.
인프라스트럭처 계층이 가장 하단에 위치하는 계층형 구조와 달리 아키텍처에 DIP를 적용하면 인프라스트럭처 영역이 응용 영역과 도메인 영역에 의존(상속)하는 구조가 된다.
인프라스트럭처에 위치한 클래스가 도메인이나 응용 영역에 정의한 인터페이스를 상속받아 구현하는 구조가 되므로 도메인과 응용 영역에 대한 영향을 주지 않거나 최소화하면서 구현 기술을 변경하는 것이 가능하다.
도메인 영역의 주요 구성요소
요소 | 설명 |
엔티티 | 고유의 식별자를 갖는 객체로 자신의 라이프 사이클을 갖는다.
주문, 회원, 상품과 같이 도메인의 고유한 개념을 표현한다.
도메인 모델의 데이터를 포함하며 해다 데이터와 관련된 기능을 함께 제공한다. |
밸류 | 고유의 식별자를 갖지 않는 객체로 주로 개념적으로 하나인 값을 표현할 때 사용된다.
배송지 주소를 표현하기 위한 주소나 구매 금액을 위한 금액과 같은 타입이 밸류 타입이다.
엔티티의 속성으로 사용할 뿐만 아니라 다른 밸류 타입의 속성으로도 사용할 수 있다. |
애그리거트 | 애그리거트는 연관된 엔티티와 밸류 객체를 개념적으로 하나로 묶은 것이다.
예를 들어 주문과 관련된 Order 엔티티, OrderLine 밸류, Orderer 밸류 객체를 ‘주문’ 애그리거트로 묶을 수 있다. |
레포지터리 | 도메인 모델의 영속성을 처리한다.
예를 들어 DBMS 테이블에서 엔티티 객체를 로딩하거나 저장하는 기능을 제공한다. |
도메인 서비스 | 특정 엔티티에 속하지 않은 도메인 로직을 제공한다.
’할인 금액 계산’은 상품, 쿠폰, 회원 등급, 구매 금액 등 다양한 조건을 이용해서 구현하게 되는데, 이렇게 도메인 로직이 여러 엔티티와 밸류를 필요로 하면 도메인 서비스에서 로직을 구현한다. |
엔티티와 밸류
도메인 모델의 엔티티는 단순히 데이터를 담고 있는 데이터 구조라기보다는 데이터와 함께 기능을 제공하는 객체이다.
도메인 관점에서 기능을 구현하고 기능 구현을 캡슐화해서 데이터가 임의로 변경되는 것을 막는다.
또 다른 차이점은 도메인 모델의 엔티티는 두 개 이상의 데이터가 개념적으로 하나인 경우 밸류 타입을 이용해서 표현할 수 있다는 것이다.
애그리거트
도메인이 커질수록 개발할 도메인 모델도 커지면서 많은 엔티티와 밸류가 출현하고 모델은 점점 더 복잡해진다.
도메인 모델이 복잡해지면 개발자가 전체 구조가 아닌 한 개 엔티티와 밸류에만 집중하는 상황이 발생한다.
도메인 모델을 개별 객체뿐만 아니라 상위 수준에서 모델을 볼 수 있어야 전체 모델의 관계와 개별 모델을 이해하는 데 도움이 된다.
애그리거트를 사용하면 개별 객체가 아닌 관련 객체를 묶어서 객체 군집 단위로 모델을 바라볼 수 있게 된다.
애그리거트는 군집에 속한 객체를 관리하는 루트 엔티티를 갖는다.
루트 엔티티는 애그리거트에 속해 있는 엔티티와 밸류 객체를 이용해서 애그리거트가 구현해야 할 기능을 제공한다.
이것은 애그리거트의 내부 구현을 숨겨서 애그리거트 단위로 구현을 캡슐화할 수 있도록 돕는다.
레포지터리
도메인 객체를 지속적으로 사용하려면 RDBMS, NoSQL, 로컬 파일과 같은 물리적인 저장소에 도메인 객체를 보관해야 한다.
이를 위한 도메인 모델이 레포지터리이다.
엔티티나 밸류가 요구사항에서 도출되는 도메인 모델이라면 레포지터리는 구현을 위한 도메인 모델이다.
레포지터리는 애그리거트 단위로 도메인 객체를 저장하고 조회하는 기능을 정의한다.
요청 처리 흐름
사용자 입장에서 봤을 때 웹 어플리케이션이나 데스크톱 어플리케이션과 같은 소프트웨어는 기능을 제공한다.
사용자가 어플리케이션에 기능 실행을 요청하면 그 요청을 처음 받는 영역은 표현 영역이다.
표현 영역은 사용자가 전송한 데이터 형식이 올바른지 검사하고 문제가 없다면 데이터를 이용해서 응용 서비스에 기능 실행을 위임한다.
이때 표현 영역은 사용자가 전송한 데이터를 응용 서비스가 요구하는 형식으로 변환해서 전달한다.
응용 서비스는 도메인 모델을 이용해서 기능을 구현한다.
기능 구현에 필요한 도메인 객체를 레포지터리에서 가져와 실행하거나 신규 도메인 객체를 생성해서 레포지터리에 저장한다.
두 개 이상의 도메인 객체를 사용해서 구현하기도 한다.
이때 응용 서비스는 도메인의 상태를 변경하므로 변경 상태가 물리 저장소에 올바르게 반영되도록 트랜잭션을 관리해야 한다.
인프라스트럭처 개요
인프라스트럭처는 표현 영역, 응용 영역, 도메인 영역을 지원한다.
도메인 객체의 영속성 처리, 트랜잭션, SMTP 클라이언트, REST 클라이언트 등 다른 영역에서 필요로 하는 프레임워크, 구현 기술, 보조 기능을 지원한다.
도메인 영역과 응용 영역에서 인프라스트럭처의 기능을 직접 사용하는 것보다 이 두 영역에 정의한 인터페이스를 인프라스트럭처 영역에서 구현하는 것이 시스템을 더 유연하고 테스트하기 쉽게 만들어준다.
하지만 무조건 인프라스트럭처에 대한 의존을 없앨 필요는 없다.
응용 영역과 도메인 영역이 인프라스트럭처에 대한 의존을 완전히 갖지 않도록 시도하는 것은 자칫 구현을 더 복잡하고 어렵게 만들 수 있다.
모듈 구성
아키텍처의 각 영역은 별도 패키지에 위치한다.
패키지 구성 규칙에 정답이 존재하는 것은 아니지만 영역별로 모듈이 위치할 패키지를 구성할 수 있다.
도메인이 크다면 하위 도메인으로 나누고 각 하위 도메인마다 별도 패키지를 구성한다.
도메인 모듈은 도메인에 속한 애그리거트를 기준으로 다시 패키지를 구성한다.
모듈 구조를 얼마나 세분화해야 하는지에 대해 정해진 규칙은 없다.
한 패키지에 너무 많은 타입이 몰려서 코드를 찾을 때 불편할 정도만 아니면 된다.
개인적으로는 한 패키지에 10~15개 미만으로 타입 개수를 유지하고 넘어가면 패키지를 분리하려는 시도를 해본다.
Chapter3. 애그리거트
애그리거트
도메인 객체 모델이 복잡해지면 개별 구성요소 위주로 모델을 이해하게 되고 전반적인 구조나 큰 수준에서 도메인 간의 관계를 파악하기 어려워진다.
주요 도메인 요소 간의 관계를 파악하기 어렵다는 것은 코드를 변경하고 확장하는 것이 어려워진다는 것을 의미한다.
복잡한 도메인을 이해하고 관리하기 쉬운 단위로 만들려면 상위 수준에서 모델을 조망할 수 있는 방법이 필요한데, 그 방법이 바로 애그리거트다.
애그리거트는 관련된 모델을 하나로 모았기 때문에 한 애그리거트에 속한 객체는 유사하거나 동일한 라이프 사이클을 갖는다.
한 애그리거트에 속한 객체는 다른 애그리거트에 속하지 않기 때문에 경계를 갖는다.
애그리거트는 독립된 객체 군이며 각 애그리거트는 자기 자신을 관리할 뿐 다른 애그리거트를 관리하지 않는다.
경계를 설정할 때 기본이 되는 것은 도메인 규칙과 요구사항이다.
도메인 규칙에 따라 함께 생성되는 구성요소는 한 애그리거트에 속할 가능성이 높다.
하지만 ‘A가 B를 갖는다’로 해석할 수 있는 요구사항이 있다고 하더라도 이것이 반드시 A와 B가 한 애그리거트에 속한다는 것을 의미하는 것은 아니다.
애그리거트 루트
애그리거트는 여러 객체로 구성되기 때문에 한 객체만 상태가 정상이면 안 된다.
애그리거트에 속한 모든 객체가 일관된 상태를 유지하려면 애그리거트 전체를 관리할 주체가 필요한데, 이 책임을 지는 것이 바로 애그리거트의 루트 엔티티이다.
애그리거트에 속한 객체는 애그리거트의 대표 엔티티인 루트 엔티티에 직접 또는 간접적으로 속하게 된다.
도메인 규칙과 일관성
애그리거트 루트의 핵심 역할은 애그리거트의 일관성이 깨지지 않도록 하는 것이다.
애그리거트 루트가 제공하는 메서드는 도메인 규칙에 따라 애그리거트에 속한 객체의 일관성이 깨지지 않도록 구현해야 한다.
애그리거트 외부에서 애그리거트에 속한 객체를 직접 변경하면 안 된다.
이는 업무 규칙을 무시하고 직접 DB 테이블의 데이터를 수정하는 것과 같은 결과를 만든다.
불필요한 중복을 피하고 애그리거트 루트를 통해서만 도메인 로직을 구현하게 만들려면 도메인 모델에 대해 다음의 두 가지를 습관적으로 적용해야 한다.
1.
단순히 필드를 변경하는 set 메서드를 공개(public) 범위로 만들지 않는다.
공개 set 메서드는 도메인의 의미나 의도를 표현하지 못하고 도메인 로직을 도메인 객체가 아닌 응용 영역이나 표현 영역으로 분산시킨다.
2.
밸류 타입은 불변으로 구현한다.
밸류 객체가 불변이면 밸류 객체의 값을 변경하는 방법은 새로운 밸류 객체를 할당하는 것뿐이다.
즉, 애그리거트 루트가 제공하는 메서드에 새로운 밸류 객체를 전달해서 값을 변경하는 방법 밖에 없다.
애그리거트 루트의 기능 구현
애그리거트 루트는 애그리거트 내부의 다른 객체를 조합해서 기능을 완성한다.
애그리거트 루트가 구성 요소의 상태만 참조하는 것은 아니고, 기능 실행을 위임하기도 한다.
보통 한 애그리거트에 속하는 모델은 한 패키지에 속하기 때문에 패키지나 protected 범위를 사용하면 애그리거트 외부에서 상태 변경 기능을 실행하는 것을 방지할 수 있다.
트랜잭션 범위
트랜잭션 범위를 작을수록 좋다.
한 트랜잭션에서는 한 개의 애그리거트만 수정해야 한다.
한 트랜잭션에서 두 개 이상의 애그리거트를 수정하면 트랜잭션 충돌이 발생할 가능성이 더 높아지기 때문에 한 번에 수정하는 애그리거트 개수가 많아질수록 전체 처리량이 떨어지게 된다.
만약 부득이하게 한 트랜잭션으로 두 개 이상의 애그리거트를 수정해야 한다면 애그리거트에서 다른 애그리거트를 직접 수정하지 말고 응용 서비스에서 두 애그리거트를 수정하도록 구현한다.
레포지터리와 애그리거트
애그리거트는 개념상 완전한 한 개의 도메인 모델을 표현하므로 객체의 영속성을 처리하는 레포지터리는 애그리거트 단위로 존재한다.
애그리거트를 저장할 때 애그리거트 루트와 매핑되는 테이블뿐만 아니라 애그리거트에 속한 모든 구성요소에 매핑된 테이블에 데이터를 저장해야 한다.
동일하게 애그리거트를 조회하는 레포지터리 메서드는 완전한 애그리거트를 제공해야 한다.

JPA와 같은 ORM에서 1:N, N:M 관계 같은 경우 ‘완전한 애그리거트’ 를 실현하려면 어떻게 해야할까?
FetchType을 LAZY로 설정하면 해당 객체를 사용할 때 쿼리가 실행되며 조회된다.
Repository의 Entity와 Domain의 Entity는 서로 다르기 때문에 Repository에서 조회를 한 후 응용 계층에서는 Domain Entity로 변환해서 다룬다.
이때 완전한 애그리거트를 만들려면 LAZY가 아니라 EAGER 로 Fetch 할 수 밖에 없다.
EAGER는 성능에 굉장히 안좋기 때문에 LAZY가 일반적이며 권장된다.
ID를 이용한 애그리거트 참조
한 객체가 다른 객체를 참조하는 것처럼 애그리거트도 다른 애그리거트를 참조한다.
애그리거트 관리 주체는 애그리거트 루트이므로 애그리거트에서 다른 애그리거트를 참조한다는 것은 다른 애그리거트의 루트를 참조한다는 것과 같다.
ORM 기술 덕에 애그리거트 루트에 대한 참조를 쉽게 구현할 수 있고 필드(또는 get 메서드)를 이용한 애그리거트 참조를 사용하면 다른 애그리거트의 데이터를 쉽게 조회할 수 있다.
하지만 필드를 이용한 애그리거트 참조는 다음 문제를 야기할 수 있다.
•
편한 탐색 오용
한 애그리거트 내부에서 다른 애그리거트 객체에 접근할 수 있으면 다른 애그리거트의 상태를 쉽게 변경할 수 있게 된다.
한 애그리거트에서 다른 애그리거트의 상태를 변경하는 것은 애그리거트 간의 의존 결합도를 높여서 결과적으로 애그리거트의 변경을 어렵게 만든다.
•
성능에 대한 고민
JPA를 사용하면 참조한 객체를 지연(Lazy) 로딩과 즉시(Eager) 로딩의 두 가지 방식으로 로딩할 수 있다.
단순히 연관된 객체의 데이터를 함께 화면에 보여줘야 하면 즉시 로딩이 조회 성능에 유리하지만 애그리거트의 상태를 변경하는 기능을 실행하는 경우에는 불필요한 객체를 함께 로딩할 필요가 없으므로 지연 로딩이 유리할 수 있다.
•
확장 어려움
사용자가 늘고 트래픽이 증가하면 자연스럽게 부하를 분산하기 위해 하위 도메인별로 시스템을 분리하기 시작한다.
이 과정에서 하위 도메인마다 서로 다른 종류의 DBMS 또는 데이터 저장소를 사용할 때도 있다.
이것은 더 이상 다른 애그리거트 루트를 참조하기 위해 JPA와 같은 단일 기술을 사용할 수 없음을 의미한다.
이런 세 가지 문제를 완화할 때 사용할 수 있는 것이 ID를 이용해서 다른 애그리거트를 참조하는 것이다.
ID 참조를 사용하면 모든 객체가 참조로 연결되지 않고 한 애그리거트에 속한 객체들만 참조로 연결된다.
참조하는 애그리거트가 필요하면 응용 서비스에서 ID를 이용해서 로딩하면 되므로 애그리거트 수준에서 지연 로딩을 하는 것과 동일한 결과를 만든다.
ID를 이용한 참조와 조회 성능
다른 애그리거트를 ID로 참조하면 참조하는 여러 애그리거트를 읽을 때 조회 속도가 문제 될 수 있다.
N + 1 조회 문제는 더 많은 쿼리를 실행하기 때문에 전체 조회 속도가 느려지는 원인이 된다.
ID 참조 방식을 사용하면서 N + 1 조회와 같은 문제가 발생하지 않도록 하려면 조회 전용 쿼리를 사용하면 된다.
애그리거트마다 서로 다른 저장소를 사용하면 한 번의 쿼리로 관련 애그리거트를 조회할 수 없다.
이때는 조회 성능을 높이기 위해 캐시를 적용하거나 조회 전용 저장소를 따로 구성한다.
이 방법은 코드가 복잡해지는 단점이 있지만 시스템의 처리량을 높일 수 있다는 장점이 있다.
애그리거트 간 집합 연관
개념적으로 존재하는 애그리거트 간의 연관을 실제 구현에 반영하는 것이 요구사항을 충족하는 것과는 상관없을 때가 있다.
카테고리에 속한 상품을 구할 필요가 있다면 상품 입장에서 자신이 속한 카테고리를 연관 지어 구하면 된다.
이를 구현 모델에 반영하면 Product에 Category로의 연관을 추가하고 그 연관을 이용해서 특정 Category에 속한 Product 목록을 구하면 된다.
JPA를 이용하면 다음과 같은 매핑 설정을 사용하여 ID 참조를 이용한 M-N 단방향 연관을 구현할 수 있다.
@Entity
@Table(name = "product")
public class Product {
@EmbeddedId
private ProductId id;
@ElementCollection
@CollectionTable(name = "product_category", joinColumns = @JoinColumn(name = "product_id"))
private Set<CategoryId> categoryIds;
...
}
Java
복사
이 매핑을 사용하면 다음과 같이 JPQL의 member of 연산자를 이용해서 특정 Category에 속한 Product 목록을 구하는 기능을 구현할 수 있다.
@Repository
public class JpaProductRepository implements ProductRepository {
@PersistenceContext
private EntityManager entityManager;
@Override
public List<Product> findByCategoryId(CategoryId catId, int page, int size) {
TypedQuery<Product> query = entityManager.createQuery(
"select p from Product p" +
"where :catId member of p.categoryIds" +
"order by p.id.id desc",
Product.class
);
query.setParameter("catId", catId);
query.setFirstResult((page - 1) * size);
query.setMaxResults(size);
return query.getResultList();
}
}
Java
복사
애그리거트를 팩토리로 사용하기
고객이 특정 상점을 여러 차례 신고해서 해당 상점이 더 이상 물건을 등록하지 못하도록 차단한 상태라고 해보자.
Store가 Product를 생성할 수 있는지를 판단하고 Product를 생성하는 것은 논리적으로 하나의 도메인 기능인데 이 도메인 기능을 응용 서비스에서 구현할 수 있을 것이다.
public class ProductService {
...
public ProductId registerNewProduct(NewProductRequest request) {
Store store = storeRepository.findById(request.getStoreId());
checkNull(store);
if (store.isBlocked()) {
throw new StoreBlockedException();
}
ProductId id = productRepository.nextId();
Product product = new Product(id, store.getId(), ...);
productRepository.save(product);
return id;
}
...
}
Java
복사
Store 애그리거트의 createProduct()는 Product 애그리거트를 생성하는 팩토리 역할을 하면서도 중요한 도메인 로직을 구현하고 있다.
팩토리 기능을 구현했으므로 이제 응용 서비스는 팩토리 기능을 이용해서 Product를 생성하면 된다.
public class Store {
public Product createProduct(ProductId newProductId, ...) {
if (isBlocked() throw new StoreBlockedException();
return new Product(newProductId, getId(), ...);
}
}
Java
복사
이제 Product 생성 가능 여부를 확인하는 도메인 로직을 변경해도 도메인 영역의 Store만 변경하면 되고 응용 서비스는 영향을 받지 않고 도메인의 응집도도 높아졌다.
이것이 바로 애그리거트를 팩토리로 사용할 때 얻을 수 있는 장점이다.
다른 팩토리에 위임하더라도 차단 상태의 상점은 상품을 만들 수 없다는 도메인 로직은 한곳에 계속 위치한다.
Chapter4. 레포지터리와 모델 구현
JPA를 이용한 레포지터리 구현
도메인 모델과 레포지터리를 구현할 때 선호하는 기술을 꼽자면 JPA를 들 수 있다.
데이터 보관소로 RDBMS를 사용할 때, 객체 기반의 도메인 모델과 관계형 데이터 모델 간의 매핑을 처리하는 기술로 ORM 만한 것이 없다.
모듈 위치
레포지터리 인터페이스는 애그리거트와 같이 도메인 영역에 속하고, 레포지터리를 구현한 클래스는 인프라스트럭처 영역에 속한다.
가능하면 레포지터리 구현 클래스를 인프라스트럭처 영역에 위치시켜서 인프라스트럭처에 대한 의존을 낮춰야 한다.
레포지터리 기본 기능 구현
인터페이스는 애그리거트 루트를 기준으로 작성한다.
public interface OrderRepository {
Order findById(OrderNo no);
}
Java
복사
애그리거트를 조회하는 기능의 이름을 지을 때 특별한 규칙은 없지만, 널리 사용되는 규칙은 ‘findBy프로퍼티이름’ 형식을 사용하는 것이다.
프로퍼티이름에 해당하는 애그리거트가 존재하면 루트 엔티티를 리턴하고 존재하지 않으면 null을 리턴한다.
null을 사용하고 싶지 않다면 Optional을 사용해도 된다.
public class OrderService {
@Transactional
public void changeShippingInfo(OrderNo no, ShippingInfo newShippingInfo) {
Optional<Order> orderOpt = orderRepository.findById(no);
Order order = orderOpt.orElseThrow(() -> new OrderNotFoundException());
order.changeShippingInfo(newShippingInfo);
}
}
Java
복사
애그리거트를 수정한 결과를 저장소에 반영하는 메서드를 추가할 필요는 없다.
JPA를 사용하면 트랜잭션 범위에서 변경한 데이터를 자동으로 DB에 반영하기 때문이다.
public interface OrderRepository {
public void delete(Order order);
}
Java
복사
애그리거트를 삭제하는 기능이 필요할 수도 있다.
하지만 삭제 요구사항이 있더라도 데이터를 실제로 삭제하는 경우는 많지 않다.
사용자가 삭제 기능을 실행할 때 데이터를 바로 삭제하기보다는 삭제 플래그를 사용해서 데이터를 화면에 보여줄지 여부를 결정하는 방식으로 구현한다.
스프링 데이터 JPA를 이용한 레포지터리 구현
스프링 데이터 JPA는 지정한 규칙에 맞게 레포지터리 인터페이스를 정의하면 레포지터리를 구현한 객체를 알아서 만들어 스프링 빈으로 등록해 준다.
•
org.springframework.data.repository.Repository<T, ID> 인터페이스 상속
•
T는 엔티티 타입을 지정하고 ID는 식별자 타입을 지정
스프링 데이터 JPA를 사용하려면 지정한 규칙에 맞게 메서드를 작성해야 한다.
•
엔티티를 저장하는 메서드
Order save(Order entity)
void save(Order entity)
Java
복사
•
식별자를 이용해서 엔티티를 조회하는 메서드
Order findById(OrderNo id)
Optional<Order> findById(OrderNo id)
Java
복사
•
특정 프로퍼티를 이용해서 엔티티를 조회하는 메서드
List<Order> findByOrderer(Orderer orderer)
Java
복사
•
중첩 프로퍼티를 이용해서 엔티티를 조회하는 메서드
List<Order> findByOrdererMemeberId(MemeberId memeberId)
Java
복사
•
엔티티를 삭제하는 메서드
void delete(Order order)
void deleteById(OrderNo id)
Java
복사
매핑 구현
엔티티와 밸류 기본 매핑 구현
•
애그리거트와 JPA 매핑을 위한 기본 규칙
애그리거트 루트는 엔티티이므로 @Entity로 매핑 설정한다.
@Entity
@Table(name = "purchase_order")
public class Order {
}
Java
복사
•
한 테이블에 엔티티와 밸류 데이터가 같이 있는 경우
밸류는 @Embeddable로 매핑 설정한다.
밸류 타입 프로퍼티는 @Embedded로 매핑 설정한다.
@Embeddable
public class Orderer {
@Embedded
@AttributeOverrides(
@AttributeOverride(name = "id", column = @Column(name = "orderer_id"))
)
private MemberId memberId;
}
@Embeddable
public class MemberId implements Serializable {
@Column(name = "member_id")
private String id;
}
Java
복사
기본 생성자
엔티티와 밸류의 생성자는 객체를 생성할 때 필요한 것을 전달받는다.
하지만 JPA에서 @Entity와 @Embeddable로 클래스를 매핑하려면 기본 생성자를 제공해야 한다.
DB에서 데이터를 읽어와 매핑된 객체를 생성할 때 기본 생성자를 사용해서 객체를 생성하기 때문이다.
기본 생성자는 JPA 프로바이더가 객체를 생성할 때만 사용한다.
기본 생성자를 다른 코드에서 사용하면 값이 없는 온전하지 못한 객체를 만들 수 있게 때문에 다른 코드에서 기본 생성자를 사용하지 못하도록 protected로 선언한다.
Hibernate를 사용하면 왜 기본 생성자가 없이도 오류가 발생하지 않는 것일까?
JPA는 추상적인 스펙이고 Hibernate는 JPA의 구현체이다.
또한 Spring Data JPA는 Hibernate를 기반으로 추가적인 기능을 제공한다.
JPA 스펙에서는 Entity에 기본 생성자를 사용하는 것을 권장한다.
Hibernate 구현체는 Reflection API를 이용하여 기본 생성자 없이도 인스턴스를 생성하여 매핑하므로 기본 생성자가 없어도 오류가 발생하지 않는다.
하지만 다른 구현체를 사용한다면 오류가 발생할 수 있다.
필드 접근 방식 사용
JPA는 필드와 메서드의 두 가지 방식으로 매핑을 처리할 수 있다.
메서드 방식을 사용하기 위해 get/set 메서드를 추가하면 도메인의 의도가 사라지고 객체가 아닌 데이터 기반으로 엔티티를 구현할 가능성이 높아진다.
특히 set 메서드는 내부 데이터를 외부에서 변경할 수 있는 수단이 되기 때문에 캡슐화를 깨는 원인이 될 수 있다.
객체가 제공할 기능 중심으로 엔티티를 구현하게끔 유도하려면 JPA 매핑 처리를 프로퍼티 방식이 아닌 필드 방식으로 선택해서 불필요한 get/set 메서드를 구현하지 말아야 한다.
접근 방식을 지정하려면 어떻게 해야할까?
JPA 구현체인 Hibernate는 @Access를 이용해서 명시적으로 접근 방식을 지정하지 않으면 @Id나 @EmbeddedId가 어디에 위치했느냐에 따라 접근 방식을 결정한다.
@Id나 @EmbeddedId가 필드에 위치하면 필드 접근 방식을 선택하고 get 메서드에 위치하면 메서드 접근 방식을 선택한다.
AttributeConverter를 이용한 밸류 매핑 처리
int, long, String, LocalDate와 같은 타입은 DB 테이블의 한 개 컬럼에 매핑된다.
두 개 이상의 프로퍼티를 가진 밸류 타입을 한 개 컬럼에 매핑하려면 @AttributeConverter를 사용할 수 있다.
convertToDatabaseColumn() 메서드는 밸류 타입을 DB 컬럼 값으로 변환하는 기능을 구현하고, convertToEntityAttribute() 메서드는 DB 컬럼 값을 밸류로 변환하는 기능을 구현한다.
public interface AttributeConverter<X, Y> {
public Y convertToDatabaseColumn(X attribute);
public X convertToEntityAttribute(Y dbData);
}
Java
복사
타입 파라미터 X는 밸류 타입이고 Y는 DB 타입이다.
@Converter(autoApply = true)
public class MoneyConverter implements AttributeConverter<Money, Integer> {
...
}
@Entity
@Table(name = "purchase_order")
public class Order {
@Column(name = "total_amounts")
@Convert(converter = MoneyConverter.class)
private Money totalAmounts;
}
Java
복사
AttributeConverter 인터페이스를 구현한 클래스는 @Converter 어노테이션을 적용한다.
@Converter의 autoApply 속성을 true로 지정하면 모든 Money 타입의 프로퍼티에 대해 MoneyConverter를 자동으로 적용한다.
@Converter의 autoApply 속성을 false로 지정하면 프로퍼티 값을 변환할 때 사용할 컨버터를 직접 지정해야 한다.
밸류 컬렉션: 별도 테이블 매핑
밸류 컬렉션을 별도 테이블에 매핑할 때는 @ElementCollection, @CollectionTable, @OrderColumn을 함께 사용한다.
@Entity
@Table(name = "purchase_order")
public class Order {
@ElementCollection(fetch = FetchType.EAGER)
@CollectionTable(name = "order_line", joinColumns = @JoinColumn(name = "order_number"))
@OrderColumn(name = "list_idx")
private List<OrderLine> orderLines;
}
Java
복사
@OrderColumn 어노테이션을 이용해서 지정한 컬럼에 리스트의 인덱스 값을 지정한다.
@CollectionTable은 밸류를 저장할 테이블을 지정한다.
name 속성은 테이블 이름을 지정하고 joinColumns 속성은 외부키로 사용할 컬럼을 지정한다.
밸류 컬렉션: 한 개 컬럼 매핑
밸류 컬렉션을 별도 테이블이 아닌 한 개 컬럼에 구분자로 구분해서 저장해야 할 때가 있다.
이때 AttributeConverter를 사용하면 밸류 컬렉션을 한 개 컬럼에 쉽게 매핑할 수 있다.
단, AttributeConverter를 사용하려면 밸류 컬렉션을 표현하는 새로운 밸류 타입을 추가해야 한다.
public class EmailSet {
private Set<Email> emails = new HashSet<>();
...
}
Java
복사
이제 AttributeConverter를 구현한 후 EmailSet 타입 프로퍼티가 Conveter로 EmailSetConverter를 사용하도록 지정하면 된다.
밸류를 이용한 ID 매핑
식별자라는 의미를 부각시키기 위해 식별자 자체를 밸류 타입으로 만들 수도 있다.
밸류 타입을 식별자로 매핑하면 @Id 대신 @EmbeddedId 어노테이션을 사용한다.
@Entity
@Table(name = "purchase_order")
public class Order {
@EmbeddedId
private OrderNo number;
}
@Embeddable
public class OrderNo implements Serializable {
@Column(name = "order_number")
private String number;
}
Java
복사
JPA에서 식별자 타입은 Serializable 타입이어야 하므로 식별자로 사용할 밸류 타입은 Serializable 인터페이스를 상속받아야 한다.
또한 JPA는 내부적으로 엔티티를 비교할 목적으로 equals() 메서드와 hashCode() 값을 사용하므로 식별자로 사용할 밸류 타입은 이 두 메서드를 알맞게 구현해야 한다.
밸류 타입으로 식별자를 구현할 때 얻을 수 있는 장점은 식별자에 기능을 추가할 수 있다는 점이다.
별도 테이블에 저장하는 밸류 매핑
애그리거트에서 루트 엔티티를 뺀 나머지 구성요소는 대부분 밸류이며 별도 테이블에 데이터를 저장한다고 해서 엔티티인 것은 아니다.
밸류가 아니라 엔티티가 확실하다면 해당 엔티티가 다른 애그리거트는 아닌지 확인해야 하고 자신만의 독자적인 라이프 사이클을 갖는다면 구분되는 애그리거트일 가능성이 높다.
이때 애그리거트에 속한 객체가 밸류인지 엔티티인지 구분하는 방법은 고유 식별자를 갖는지를 확인하는 것이다.
하지만 식별자를 찾을 때 매핑되는 테이블의 식별자를 애그리거트 구성요소의 식별자와 동일한 것으로 착각하면 안 된다.
별도 테이블로 저장하고 테이블에 PK가 있다고 해서 테이블과 매핑되는 애그리거트 구성요소가 항상 고유 식별자를 갖는 것은 아니기 때문이다.
@Entity
@Table(name = "article")
@SecondaryTable(
name = "article_content",
pkJoinColumns = @PrimaryKeyJoinColumn(name = "id")
)
public class Article {
...
@Embedded
@AttributeOverrides({
@AttributeOverride(
name = "content",
column = @Column(table = "article_content", name = "content")
),
@AttributeOverride(
name = "contentType",
column = @Column(table = "article_content", name = "content_type")
)
})
private ArticleContent
}
Java
복사
밸류를 매핑한 테이블을 지정하기 위해 @SecondaryTable과 @AttributeOverride를 사용할 수 있다.
@SecondaryTable을 이용하면 Article을 조회할 때 ArticleContent 테이블을 조인해서 데이터를 조회한다.
이 문제를 해소하고자 ArticleContent를 엔티티로 매핑하고 Article에서 ArticleContent로의 로딩을 지연 로딩 방식으로 설정할 수도 있다.
하지만 이 방식은 밸류인 모델을 엔티티로 만드는 것이므로 좋은 방법은 아니다.
대신 조회 전용 기능을 구현하는 방법을 사용하는 것이 좋다.
밸류 컬렉션을 @Entity로 매핑하기
JPA는 @Embeddable 타입의 클래스 상속 매핑을 지원하지 않는다.
상속 구조를 갖는 밸류 타입을 사용하려면 @Entity를 이용해서 상속 매핑으로 처리해야 한다.
밸류 타입을 @Entity로 매핑해야 하므로 식별자 매핑을 위한 필드도 추가해야 한다.
또한 구현 클래스를 구분하기 위한 타입 식별 컬럼을 추가해야 한다.
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "image_type")
@Table(name = "image")
public abstract class Image {
@Id
...
}
@Entity
@DiscriminatorValue("II")
public class InternalImage extends Image {}
@Entity
@DiscriminatorValue("EI")
public class ExternalImage extends Image {}
Java
복사
Image가 @Entity이므로 목록을 담고 있는 Product는 @OneToMany를 이용해서 매핑을 처리한다.
@Entity
@Table(name = "product")
public class Product {
...
@OneToMany(
cascade = {CascadeType.PERSIST, CascadeType.REMOVE},
orphanRemoval = true
)
@JoinColumn(name = "product_id")
@OrderColumn(name = "list_idx")
private List<Image> images = new ArrayList<>();
}
Java
복사
@Entity에 대한 @OneToMany 매핑에서 컬렉션의 clear() 메서드를 호출하면 select 쿼리로 대상 엔티티를 로딩하고 각 개별 엔티티에 대해 delete 쿼리를 실행하므로 삭제 과정이 효율적이지는 않다.
Hibernate는 @Embeddable 타입에 대한 컬렉션의 clear() 메서드를 호출하면 컬렉션에 속한 객체를 로딩하지 않고 한 번에 delete 쿼리로 삭제 처리를 수행한다.
따라서 애그리거트의 특성을 유지하면서 이 문제를 해소하려면 결국 상속을 포기하고 @Embeddable로 매핑된 단일 클래스로 구현해야 한다.
ID 참조와 조인 테이블을 이용한 단방향 M-N 매핑
@Entity
@Table(name = "product")
public class Product {
...
@ElementCollection
@CollectionTable(
name = "product_category",
joinColumns = @JoinColumn(name = "product_id"))
)
private Set<CategoryId> categoryIds;
}
Java
복사
ID 참조를 이용한 애그리거트 간 단방향 M-N 연관은 밸류 컬렉션 매핑과 동일한 방식으로 설정할 수 있다.
차이점이 있다면 집합의 값에 밸류 대신 연관을 맺는 식별자가 온다는 점이다.
애그리거트를 직접 참조하는 방식을 사용했다면 조인 테이블의 데이터를 삭제할 때 영속성 전파나 로딩 전략을 고민해야 한다.
애그리거트 로딩 전략
애그리거트는 개념적으로 하나여야 한다.
하지만 루트 엔티티를 로딩하는 시점에 애그리거트에 속한 객체를 모두 로딩해야 하는 것은 아니다.
애그리거트가 완전해야 하는 이유는 두 가지 정도로 생각해 볼 수 있다.
1.
상태를 변경하는 기능을 실행할 때 애그리거트 상태가 완전해야 한다.
별도의 조회 전용 기능과 모델을 구현하는 방식을 사용하는 것이 더 유리하다.
2.
표현 영역에서 애그리거트의 상태 정보를 보여줄 때 필요하다.
JPA는 트랜잭션 범위 내에서 지연 로딩을 허용하기 때문에 실제로 상태를 변경하는 시점에 필요한 구성요소만 로딩해도 문제가 되지 않는다.
지연 로딩은 동작 방식이 항상 동일하기 때문에 즉시 로딩처럼 경우의 수를 따질 필요가 없는 장점이 있다.
(즉시 로딩 설정은 @Entity나 @Embeddable에 대해 다르게 동작하고, JPA 프로바이더에 따라 구현 방식이 다를 수 있다.)
물론 지연 로딩은 즉시 로딩보다 쿼리 실행 횟수가 많아질 가능성이 높다.
따라서 무조건 즉시 로딩이나 지연 로딩으로만 설정하기보다는 애그리거트에 맞게 즉시 로딩과 지연 로딩을 선택해야 한다.
애그리거트의 영속성 전파
애그리거트가 완전한 상태여야 한다는 것은 애그리거트 루트를 조회할 때뿐만 아니라 저장하고 삭제할 때도 하나로 처리해야 함을 의미한다.
•
저장 메서드는 애그리거트 루트만 저장하면 안 되고 애그리거트에 속한 모든 객체를 저장해야 한다.
•
삭제 메서드는 애그리거트 루트뿐만 아니라 애그리거트에 속한 모든 객체를 삭제해야 한다.
@Embeddable 매핑 타입은 함께 저장되고 삭제되므로 cascade 속성을 추가로 설정하지 않아도 된다.
반면에 애그리거트에 속한 @Entity 타입에 대한 매핑은 cascade 속성을 사용해서 저장과 삭제 시에 함께 처리되도록 설정해야 한다.
@OneToOne, @OneToMany는 cascade 속성의 기본값이 없으므로 CascadeType.PERSIST, CascadeType.REMOVE를 설정한다.
식별자 생성 기능
식별자는 크게 세 가지 방식 중 하나로 생성한다.
1.
사용자가 직접 생성
식별자 생성 주체가 사용자이기 때문에 도메인 영역에서 식별자 생성 기능을 구현할 필요가 없다.
2.
도메인 로직으로 생성
엔티티를 생성할 때 식별자를 엔티티가 별도 서비스로 식별자 생성 기능을 분리해야 한다.
식별자 생성 규칙은 도메인 규칙이므로 도메인 영역에 식별자 생성 기능을 위치시켜야 한다.
또 다른 적합한 장소는 레포지터리 인터페이스에 식별자 생성 기능을 위치시키는 것이다.
3.
DB를 이용한 일련번호 사용
식별자 매핑에서 @GeneratedValue를 사용한다.
JPA의 식별자 생성 기능은 DB의 insert 쿼리를 실행해야 식별자가 생성되므로 도메인 객체를 레포지터리에 저장할 때 식별자가 생성된다.
도메인 구현과 DIP
DIP에 따르면 @Entity, @Table은 구현 기술에 속하므로 도메인 모델은 구현 기술인 JPA에 의존하지 말아야 한다.
레포지터리 인터페이스 또한 마찬가지로 구현 기술인 Spring Data JPA의 레포지터리 인터페이스를 상속하므로 도메인이 인프라에 의존하고 있다.
DIP를 적용하는 주된 이유는 저수준 구현이 변경되더라도 고수준이 영향을 받지 않도록 하기 위함이다.
하지만 레포지터리와 도메인 모델의 구현 기술은 거의 바뀌지 않는다.
JPA 전용 어노테이션을 사용하긴 했지만 도메인 모델을 단위 테스트하는데 문제는 없다.
레포지터리도 마찬가지로 Spring Data JPA가 제공하는 레포지터리 인터페이스를 상속하고 있지만 레포지터리 자체는 인터페이스이고 테스트 가능성을 해치지 않는다.
Chapter5. 스프링 데이터 JPA를 이용한 조회 기능
스프링 데이터 JPA를 이용한 스펙 구현
스프링 데이터 JPA는 검색 조건을 표현하기 위한 인터페이스인 Specification을 제공한다.
public interface Specification<T> extends Serializable {
// not, where, and, or 메서드 생략
@Nullable
Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder cb);
}
Java
복사
스펙 인터페이스에서 제네릭 타입 파라미터 T는 JPA 엔티티 타입을 의미한다.
toPredicate() 메서드는 JPA 크리테리아 API에서 조건을 표현하는 Predicate을 생성한다.
public class OrderSummarySpecs {
public static Specification<OrderSummary> ordererId(String ordererId) {
return (Root<OrderSummary> root, CriteriaQuery<?> query, CriteriaBuilder cb) ->
cb.equal(root.get(OrderSummary_.ordererId), ordererId);
}
}
Java
복사
스펙 인터페이스는 함수형 인터페이스이므로 람다식을 이용해서 객체를 생성할 수 있다.
레포지터리/DAO에서 스펙 사용하기
스펙을 충족하는 엔티티를 검색하고 싶다면 findAll() 메서드를 사용하면 된다.
public interface OrderSummaryDao extends Repository<OrderSummary, String> {
List<OrderSummary> findAll(Specification<OrderSummary> spec);
}
Java
복사
스펙 조합
스프링 데이터 JPA가 제공하는 스펙 인터페이스는 스펙을 조합할 수 있는 두 메서드를 제공하고 있다.
public interface Specification<T> extends Serializable {
default Specification<T> and(@Nullable Specification<T> other) { ... }
default Specification<T> or(@Nullable Specification<T> other) { ... }
}
Java
복사
and()와 or() 메서드는 기본 구현을 가진 디폴트 메서드이다.
and() 메서드는 두 스펙을 모두 충족하는 조건을 표현하는 새로운 스펙을 생성하고, or() 메서드는 두 스펙 중 하나 이상 충족하는 조건을 표현하는 새로운 스펙을 생성한다.
Specification<OrderSummary> spec = Specification.where(createNullableSpec()).and(createOtherSpec());
Java
복사
where() 메서드를 사용하면 매번 null 여부를 검사하는 귀찮음을 줄일 수 있다.
where() 메서드는 스펙 인터페이스의 정적 메서드로 null을 전달하면 아무 조건도 생성하지 않는 스펙 객체를 리턴하고 null이 아니면 인자로 받은 스펙 객체를 그대로 리턴한다.
정렬 지정하기
스프링 데이터 JPA는 두 가지 방법을 사용해서 정렬을 지정할 수 있다.
•
메서드 이름에 OrderBy를 사용해서 정렬 기준 지정
public interface OrderSummaryDao extends Repository<OrderSummary, String> {
List<OrderSummary> findByOrdererIdOrderByOrderDateDescNumberAsc(String ordererId);
}
Java
복사
이 메서드는 ordererId 프로퍼티 값을 기준으로 검색 조건을 지정하고 OrderDate 프로퍼티를 기준으로 내림차순 정렬 후 Number 프로퍼티를 기준으로 오름차순 정렬하는 조회 쿼리를 생성한다.
메서드 이름에 OrderBy를 사용하는 방법은 간단하지만 정렬 기준 프로퍼티가 두 개 이상이면 메서드 이름이 길어지는 단점이 있다.
또한 메서드 이름으로 정렬 순서가 정해지기 때문에 상황에 따라 정렬 순서를 변경할 수도 없다.
•
Sort를 인자로 전달
public interface OrderSummaryDao extends Repository<OrderSummary, String> {
List<OrderSummary> findByOrdererId(String ordererId, Sort sort);
}
Sort sort = Sort.by("number").ascending().and(Sort.by("orderDate").descending());
List<OrderSummary> results = orderSummaryDao.findByOrdererId("user1", sort);
Java
복사
스프링 데이터 JPA는 파라미터로 전달 받은 Sort를 사용해서 알맞게 정렬 쿼리를 생성한다.
페이징 처리하기
스프링 데이터 JPA는 페이징 처리를 위해 Pageable 타입을 이용한다.
public interface MemberDataDao extends Repository<MemberData, String> {
List<MemberData> findByNameLike(String name, Pageable pageable);
}
PageRequest pageReq = PageRequest.of(1, 10);
List<MemberData> user = memberDataDao.findByNameLike("사용자%", pageReq);
Java
복사
Pageable 타입은 인터페이스로 실제 Pageable 타입 객체는 PageRequest 클래스를 이용해서 생성한다.
PageRequest.of() 메서드의 첫 번째 인자는 페이지 번호를, 두 번째 인자는 한 페이지의 개수를 의미한다.
Pageble을 사용하는 메서드의 리턴 타입이 Page일 경우 스프링 데이터 JPA는 목록 조회 쿼리와 함께 COUNT 쿼리도 실행해서 조건에 해당하는 데이터 개수를 구한다.
Page는 전체 개수, 페이지 개수 등 페이징 처리에 필요한 데이터도 함께 제공한다.
List<MemberData> findFirst3ByNameLikeOrderByName(String name)
MemberData findTopByBlockedOrdererById(boolean blocked)
Java
복사
처음부터 N개의 데이터가 필요하다면 Pageable을 사용하지 않고 findFirstN 형식의 메서드를 사용할 수도 있다.
First 뒤에 숫자가 없거나 Top을 사용한다면 한 개 결과만 리턴한다.
스펙 조합을 위한 스펙 빌더 클래스
스펙을 생성하다 보면 조건에 따라 스펙을 조합해야 할 때가 있다.
if문과 각 스펙을 조합하는 코드가 섞여 있으면 복잡한 구조를 갖고 실수하기 좋기 때문에 스펙 빌더를 만들어 사용한다.
Specification<MemberData> spec = SpecBuilder.builder(MemberData.class)
.ifTrue(searchRequest.isOnlyNotBlocked(),
() -> MemberDataSpecs.nonBlocked())
.ifHasText(searchRequest.getName(),
name -> MemberDataSpecs.nameLike(searchRequest.getName())
.toSpec();
Java
복사
코드 양은 비슷한데 메서드를 사용해서 조건을 표현하고 메서드 호출 체인으로 연속된 변수 할당을 줄여 코드 가독성을 높이고 구조가 단순해졌다.
동적 인스턴스 생성
JPA는 쿼리 결과에서 임의의 객체를 동적으로 생성할 수 있는 기능을 제공하고 있다.
public interface OrderSummaryDao extends Repository<OrderSummary, String> {
@Query("""
select new com.myshop.order.query.dto.OrderView(
o.number, o.state, m.name, m.id, p.name
)
from Order o join o.orderLines ol, Member m, Product p
where o.orderer.memberId.id = :ordererId
and o.orderer.memberId.id = m.id
and index(ol) = 0
and ol.productId.id = p.id
order by o.number.number desc
""")
List<OrderView> findOrderView(String ordererId);
}
Java
복사
new 키워드 뒤에 생성할 인스턴스의 완전한 클래스 이름을 지정하고 괄호 안에 생성자에 인자로 전달할 값을 지정한다.
조회 전용 모델을 만드는 이유는 표현 영역을 통해 사용자에게 데이터를 보여주기 위함이다.
Money와 같은 밸류 타입을 원하는 형식으로 출력하도록 프레임워크를 확장해서 조회 전용 모델에서 밸류 타입의 의미가 사라지지 않도록 할 수 있다.
동적 인스턴스의 장점은 JPQL을 그대로 사용하므로 객체 기준으로 쿼리를 작성하면서도 동시에 지연/즉시 로딩과 같은 고민 없이 원하는 모습으로 데이터를 조회할 수 있다는 점이다.
하이버네이트 @SubSelect 사용
하이버네이트는 JPA 확장 기능으로 쿼리 결과를 @Entity로 매핑할 수 있는 @SubSelect를 제공한다.
@Entity
@Immutable
@Subselect(
"""
select
o.order_number as number,
o.version,
o.orderer_id,
o.orderer_name,
o.total_amounts,
o.receiver_name,
o.state,
o.order_date,
p.product_id,
p.name as product_name
from
purchase_order o
inner join
order_line ol
on
o.order_number = ol.order_number
cross join
product p
where
ol.line_idx = 0
and
ol.product_id = p.product_id
"""
)
@Synchronize({"purchase_order", "order_line", "product"})
public class OrderSummary {
...
}
Java
복사
@Immutable, @Subselect, @Synchronize는 하이버네이트 전용 어노테이션인데 이 태그를 사용하면 테이블이 아닌 쿼리 결과를 @Entity로 매핑할 수 있다.
@Subselect를 이용한 @Entity의 매핑 필드를 수정하면 하이버네이트는 변경 내역을 반영하는 update 쿼리를 실행하지만 매핑 한 테이블이 없으므로 에러가 발생한다.
이런 문제를 방지하기 위해 @Immutable을 사용하여 해당 엔티티의 매핑 필드/프로퍼티가 변경되어도 DB에 반영하지 않고 무시한다.
Order order = orderRepository.findById(orderNumber);
order.changeShippingInfo(newInfo); // 상태 변경
// 변경 내역 반영 없이 조회
List<OrderSummary> summaries = orderSummaryRepository.findByOrdererId(userId);
Java
복사
특별한 이유가 없으면 하이버네이트는 트랜잭션을 커밋하는 시점에 변경사항을 DB에 반영하므로 OrderSummary에는 최신 값이 아닌 이전 값이 담기게 된다.
@Synchronize는 해당 엔티티와 관련된 테이블 목록을 명시하고 엔티티를 로딩하기 전에 지정한 테이블과 관련된 변경이 발생하면 플러시를 먼저 한다.
select
osm.number as number1_0_,
...
from (
select
o.order_number as number,
o.version,
o.orderer_id,
o.orderer_name,
o.total_amounts,
o.receiver_name,
o.state,
o.order_date,
p.product_id,
p.name as product_name
from
purchase_order o
inner join
order_line ol
on
o.order_number = ol.order_number
cross join
product p
where
ol.line_idx = 0
and
ol.product_id = p.product_id
) osm
where
osm.orderer_id = ?
order by
osm.number desc
SQL
복사
@Subselect는 이름처럼 @Subselect의 값으로 지정한 쿼리를 from 절의 서브 쿼리로 사용한다.
Chapter6. 응용 서비스와 표현 영역
표현 영역과 응용 영역
도메인 영역이 제 기능을 하려면 사용자와 도메인을 연결해 주는 매개체인 응용 영역과 표현 영역이 필요하다.
요청을 받은 표현 영역은 URL, 요청 파라미터, 쿠키, 헤더 등을 이용해서 사용자가 실행하고 싶은 기능을 판별하고 그 기능을 제공하는 응용 서비스를 실행한다.
응용 서비스는 기능을 실행하는데 필요한 입력 값을 메서드 인자로 받고 실행 결과를 리턴한다.
표현 영역은 응용 서비스가 요구하는 형식으로 사용자 요청을 변환한다.
응용 서비스는 표현 영역에 의존하지 않고 기능 실행에 필요한 입력 값을 받고 실행 결과만 리턴하면 된다.
응용 서비스의 역할
도메인 로직 넣지 않기
응용 서비스는 주로 도메인 객체 간의 흐름을 제어하기 때문에 단순한 형태를 갖는다.
응용 서비스가 복잡하다면 응용 서비스에서 도메인 로직의 일부를 구현하고 있을 가능성이 높다.
응용 서비스가 도메인 로직을 일부 구현하면 코드 품질에 문제가 발생한다.
첫 번째 문제는 코드의 응집성이 떨어진다는 것이다.
도메인 데이터와 그 데이터를 조작하는 도메인 로직이 한 영역에 위치하지 않고 서로 다른 영역에 위치한다는 것은 도메인 로직을 파악하기 위해 여러 영역을 분석해야 한다는 것을 의미한다.
두 번째 문제는 여러 응용 서비스에서 동일한 도메인 로직을 구현할 가능성이 높아진다는 것이다.
코드 중복을 막기 위해 응용 서비스 영역에 별도의 보조 클래스를 만들 수 있지만, 애초에 도메인 영역에 기능을 구현했으면 응용 서비스는 그 기능을 사용하기만 하면 된다.
트랜잭션 처리 담당
응용 서비스는 트랜잭션 처리도 담당한다.
응용 서비스는 도메인의 상태 변경을 트랜잭션으로 처리해야 한다.
응용 서비스의 기능이 트랜잭션 범위에서 실행되지 않으면 상태 변경을 DB에 반영하는 도중 문제가 발생했을 때 데이터 일관성이 깨지게 된다.
이런 상황이 발생하지 않으려면 트랜잭션 범위에서 응용 서비스를 실행해야 한다.
응용 서비스의 구현
응용 서비스의 크기
응용 서비스는 보통 다음의 두 가지 방법 중 한 가지 방식으로 구현한다.
•
한 응용 서비스 클래스에 도메인의 모든 기능 구현하기
각 기능에서 동일한 로직을 위한 코드 중복을 제거하기 쉽다는 것이 장점이라면 한 서비스 클래스의 크기(코드 줄 수)가 커진다는 것이 단점이다.
코드 크기가 커지면 연관성이 적은 코드가 한 클래스에 함께 위치할 가능성이 높아지게 되는데 결과적으로 관련 없는 코드가 뒤섞여 코드를 이해하는 데 방해가 된다.
게다가 한 클래스에 코드가 모이기 시작하면 엄연히 분리하는 것이 좋은 상황임에도 습관적으로 기존에 존재하는 클래스에 억지로 끼워 넣게 된다.
이것은 코드를 점점 얽히게 만들어 코드 품질을 낮추는 결과를 초래한다.
•
구분되는 기능별로 응용 서비스 클래스를 따로 구현하기
한 응용 서비스 클래스에서 한 개 내지 2~3개의 기능을 구현한다.
이 방식을 사용하면 클래스 개수는 많아지지만 한 클래스에 관련 기능을 모두 구현하는 것과 비교해서 코드 품질을 일정 수준으로 유지하는데 도움이 된다.
또한 각 클래스별로 필요한 의존 객체만 포함하므로 다른 기능을 구현한 코드에 영향을 받지 않는다.
각 기능마다 동일한 로직을 구현할 경우 별도 클래스에 로직을 구현하면 코드가 중복되는 것을 방지할 수 있다.
응용 서비스의 인터페이스와 클래스
인터페이스가 필요한 몇 가지 상황이 있는데 그중 하나는 구현 클래스가 여러 개인 경우다.
구현 클래스가 다수 존재하거나 런타임에 구현 객체를 교체해야 할 때 인터페이스를 유용하게 사용할 수 있다.
그런데 응용 서비스는 런타임에 교체하는 경우가 거의 없고 한 응용 서비스의 구현 클래스가 두 개인 경우도 드물기 때문에 인터페이스와 클래스를 따로 구현하면 소스 파일만 많아지고 구현 클래스에 대한 간접 참조가 증가해서 전체 구조가 복잡해진다.
표현 영역부터 개발을 시작한다면 응용 서비스의 인터페이스를 이용해서 컨트롤러의 구현을 완성해 나갈 수 있다.
도메인 영역이나 응용 영역의 개발을 먼저 시작하면 응용 서비스 클래스가 먼저 만들어진다.
Mockito와 같은 테스트 도구는 클래스에 대해서도 테스트용 대역 객체를 만들 수 있기 때문에 응용 서비스에 대한 인터페이스가 없어도 표현 영역을 테스트할 수 있다.
메서드 파라미터와 값 리턴
스프링 MVC와 같은 웹 프레임워크는 웹 요청 파라미터를 자바 객체로 변환하는 기능을 제공하므로 응용 서비스에 데이터로 전달할 요청 파라미터가 두 개 이상 존재하면 데이터 전달을 위한 별도 클래스를 사용하는 것이 편리하다.
응용 서비스의 결과를 표현 영역에서 사용해야 하면 응용 서비스 메서드의 결과로 필요한 데이터를 리턴한다.
응용 서비스에서 애그리거트 자체를 리턴하면 코딩은 편할 수 있지만 도메인의 로직 실행을 응용 서비스와 표현 영역 두 곳에서 할 수 있게 된다.
이것은 기능 실행 로직을 응용 서비스와 표현 영역에 분산시켜 코드의 응집도를 낮추는 원인이 된다.
표현 영역에 의존하지 않기
응용 서비스의 파라미터 타입을 결정할 때 주의할 점은 표현 영역과 관련된 타입을 사용하면 안 된다는 점이다.
예를 들어 표현 영역에 해당하는 HttpServletRequest나 HttpSession을 응용 서비스에 파라미터로 전달하면 안 된다.
응용 서비스에서 표현 영역에 대한 의존이 발생하면 응용 서비스만 단독으로 테스트하기가 어려워진다.
게다가 표현 영역의 구현이 변경되면 응용 서비스의 구현도 함께 변경해야 하는 문제도 발생한다.
HttpSession이나 쿠키는 표현 영역의 상태에 해당하는데 이 상태를 응용 서비스에서 변경해 버리면 표현 영역의 코드만으로 표현 영역의 상태가 어떻게 변경되는지 추적하기 어려워진다.
즉, 표현 영역의 응집도가 깨지는 것이다.
이것은 결과적으로 코드 유지 보수 비용을 증가시키는 원인이 된다.
트랜잭션 처리
회원가입에 성공했다고 하면서 실제로 회원 정보를 DB에 삽입하지 않으면 고객은 로그인을 할 수 없다.
비슷하게 배송지 주소를 변경하는데 실패했다는 안내 화면을 보여줬는데 실제로는 DB에 변경된 배송지 주소가 반영되어 있다면 고객은 물건을 제대로 받지 못하게 된다.
이 두 가지는 트랜잭션과 관련된 문제로 트랜잭션을 관리하는 것은 응용 서비스의 중요한 역할이다.
표현 영역
표현 영역의 책임은 크게 다음과 같다.
•
사용자가 시스템을 사용할 수 있는 흐름(화면)을 제공하고 제어한다.
웹 서비스의 표현 영역은 사용자가 요청한 내용을 응답으로 제공한다.
응답에는 다음 화면으로 이동할 수 있는 링크나 데이터를 입력하는데 필요한 폼 등이 포함된다.
•
사용자의 요청을 알맞은 응용 서비스에 전달하고 결과를 사용자에게 제공한다.
화면을 보여주는데 필요한 데이터를 읽거나 도메인의 상태를 변경해야 할 때 응용 서비스를 사용한다.
이 과정에서 표현 영역은 사용자의 요청 데이터를 응용 서비스가 요구하는 형식으로 변환하고 응용 서비스의 결과를 사용자에게 응답할 수 있는 형식으로 변환한다.
•
사용자의 세션을 관리한다.
웹은 쿠키나 서버 세션을 이용해서 사용자의 연결 상태를 관리한다.
세션 관리는 권한 검사와도 연결된다.
값 검증
값 검증은 표현 영역과 응용 서비스 두 곳에서 모두 수행할 수 있다.
원칙적으로 모든 값에 대한 검증은 응용 서비스에서 처리한다.
그런데 표현 영역은 잘못된 값이 존재하면 이를 사용자에게 알려주고 값을 다시 입력받아야 한다.
표현 영역에서 필수 값과 값의 형식을 검사하면 실질적으로 응용 서비스는 ID 중복 여부와 같은 논리적 오류만 검사하면 된다.
즉, 표현 영역과 응용 서비스가 값 검사를 나눠서 수행하는 것이다.
•
표현 영역 : 필수 값, 값의 형식, 범위 등을 검증한다.
•
응용 서비스 : 데이터의 존재 유무와 같은 논리적 오류를 검증한다.
응용 서비스에서 얼마나 엄격하게 값을 검증해야 하는지에 대해서는 의견이 갈릴 수 있다.
응용 서비스에서 필요한 값 검증을 모두 처리하면 프레임워크가 제공하는 검증 기능을 사용할 때보다 작성할 코드가 늘어나는 불편함이 있지만 반대로 응용 서비스의 완성도가 높아지는 이점이 있다.
권한 검사
개발하는 시스템마다 권한의 복잡도가 다르다.
단순한 시스템은 인증 여부만 검사하면 되는데 반해, 어떤 시스템은 관리자인지에 따라 사용할 수 있는 기능이 달라지기도 한다.
또 실행할 수 있는 기능이 역할마다 달라지는 경우도 있다.
스프링 시큐리티 같은 프레임워크는 유연하고 확장 가능한 구조를 갖고 있지만 이해가 부족하면 무턱대고 도입하는 것보다 개발할 시스템에 맞는 권한 검사 기능을 구현하는 것이 시스템 유지 보수에 유리할 수 있다.
보통 다음 세 곳에서 권한 검사를 수행할 수 있다.
•
표현 영역
기본적인 검사는 인증된 사용자인지 아닌지 검사하는 것이다.
이런 접근 제어를 하기에 좋은 위치가 서블릿 필터이다.
서블릿 필터에서 사용자의 인증 정보를 생성하고 인증 여부를 검사한다.
인증 여부뿐만 아니라 권한에 대해서 동일한 방식으로 필터를 사용해서 URL별 권한 검사를 할 수 있다.
•
응용 서비스
URL만으로 접근 제어를 할 수 없는 경우 응용 서비스의 메서드 단위로 권한 검사를 수행해야 한다.
이것이 꼭 응용 서비스의 코드에서 직접 권한 검사를 해야 한다는 것을 의미하는 것은 아니다.
예를 들어 스프링 시큐리티는 AOP를 활용해서 어노테이션으로 서비스 메서드에 대한 권한 검사를 할 수 있는 기능을 제공한다.
public class BlockMemberService {
@PreAuthorize("hasRole('ADMIN')")
public void block(String memberId) {
...
}
}
Java
복사
•
도메인
개별 도메인 객체 단위로 권한 검사를 해야 하는 경우는 구현이 복잡해진다.
응용 서비스의 메서드 수준에서 권한 검사를 할 수 없기 때문에 직접 권한 검사 로직을 구현해야 한다.
public class DeleteArticleService {
public void delete(String userId, Long articleId) {
Article article = articleRepository.findById(articleId);
checkArticleExistence(article);
permissionService.checkDeletePermission(userId, article);
article.markDeleted();
}
}
Java
복사
조회 전용 기능과 응용 서비스
서비스에서 조회 전용 기능을 사용하면 서비스 코드가 단순히 조회 전용 기능을 호출하는 형태로 끝날 수 있다.
서비스에서 수행하는 추가적인 로직이 없을뿐더러 단일 쿼리만 실행하는 조회 전용 기능이어서 트랜잭션이 필요하지도 않다.
이 경우라면 굳이 서비스를 만들 필요 없이 표현 영역에서 바로 조회 전용 기능을 사용해도 문제가 없다.
Chapter7. 도메인 서비스
여러 애그리거트가 필요한 기능
도메인 영역의 코드를 자성하다 보면, 한 애그리거트로 기능을 구현할 수 없을 때가 있다.
대표적인 예가 결제 금액 계산 로직이다.
•
상품 애그리거트
구매하는 상품의 가격이 필요하다. 또한 상품에 따라 배송비가 추가되기도 한다.
•
주문 애그리거트
상품별로 구매 개수가 필요하다.
•
할인 쿠폰 애그리거트
쿠폰별로 지정한 할인 금액이나 비율에 따라 주문 총 금액을 할인한다.
할인 쿠폰을 조건에 따라 중복 사용할 수 있다거나 지정한 카테고리의 상품에만 적용할 수 있다는 제약 조건이 있다면 할인 계산이 복잡해진다.
•
회원 애그리거트
회원 등급에 따라 추가 할인이 가능하다.
이 상황에서 실제 결제 금액을 계산해야 하는 주체는 어떤 애그리거트일까?
결제 금액 계산 로직이 주문 애그리거트의 책임이 맞을까?
한 애그리거트에 넣기 애매한 도메인 기능을 억지로 특정 애그리거트에 구현하면 안 된다.
억지로 구현하면 애그리거트는 자신의 책임 범위를 넘어서는 기능을 구현하기 때문에 코드가 길어지고 외부에 대한 의존이 높아지게 되며 코드를 복잡하게 만들어 수정을 어렵게 만드는 요인이 된다.
게다가 애그리거트의 범위를 넘어서는 도메인 개념이 애그리거트에 숨어들어 명시적으로 드러나지 않게 된다.
이런 문제를 해소하는 가장 쉬운 방법은 도메인 기능을 별도 서비스로 구현하는 것이다.
도메인 서비스
도메인 서비스는 도메인 영역에 위치한 도메인 로직을 표현할 때 사용한다.
주로 다음 상황에서 도메인 서비스를 사용한다.
•
계산 로직
여러 애그리거트가 필요한 계산 로직이나 한 애그리거트에 넣기에는 다소 복잡한 계산 로직을 구현하려면 애그리거트에 억지로 넣기보다는 도메인 서비스를 이용해서 도메인 개념을 명시적으로 드러내면 된다.
도메인 영역의 애그리거트나 밸류와 같은 구성요소와 도메인 서비스를 비교할 때 다른 점은 도메인 서비스는 상태 없이 로직만 구현한다는 점이다.
도메인 서비스를 구현하는데 필요한 상태는 다른 방법으로 전달받는다.
도메인 서비스를 사용하는 주체는 애그리거트가 될 수도 있고 응용 서비스가 될 수도 있다.
애그리거트 객체에 도메인 서비스를 전달하는 것은 응용 서비스의 책임이다.
애그리거트 메서드를 실행할 때 도메인 서비스를 인자로 전달하지 않고 반대로 도메인 서비스의 기능을 실행할 때 애그리거트를 전달하기도 한다.
•
외부 시스템 연동이 필요한 도메인 로직
외부 시스템이나 타 도메인과의 연동 기능도 도메인 서비스가 될 수 있다.
예를 들어 설문 조사 시스템과 사용자 역할 관리 시스템이 분리되어 있다고 하자.
설문 조사 도메인 입장에서는 사용자가 설문 조사 생성 권한을 가졌는지 확인하는 도메인 로직으로 볼 수 있다.
public interface SurveyPermissionChecker {
boolean hasUserCreationPermission(String userId);
}
public class CreateSurveyService {
private SurveyPermissionChecker permissionChecker;
public Long createSurvey(CreateSurveyRequest req) {
if (!permissionChecker.hasUserCreationPermission(req.getRequestorId())) {
throw new NoPermissionException();
}
}
}
Java
복사
응용 서비스인 CreateSurveyService는 도메인 서비스인 SurveyPermissionChecker를 이용해서 생성 권한을 검사한다.
SurveyPermissionChecker 인터페이스를 구현한 클래스는 인프라스트럭처 영역에 위치해 연동을 포함한 권한 검사 기능을 구현한다.
도메인 서비스의 패키지 위치
도메인 서비스는 도메인 로직을 표현하므로 도메인 서비스의 위치는 다른 도메인 구성요소와 동일한 패키지에 위치한다.
도메인 서비스의 개수가 많거나 엔티티나 밸류와 같은 다른 구성요소와 명시적으로 구분하고 싶다면 domain 패키지 밑에 domain.model, domain.service, domain.repository와 같이 하위 패키지를 구분하여 위치시켜도 된다.
도메인 서비스의 인터페이스와 클래스
도메인 서비스의 로직이 고정되어 있지 않은 경우 도메인 서비스 자체를 인터페이스로 구현하고 이를 구현한 클래스를 둘 수도 있다.
특히 도메인 로직을 외부 시스템이나 별도 엔진을 이용해서 구현할 때 인터페이스와 클래스를 분리하게 된다.
도메인 서비스의 구현이 특정 구현 기술에 의존하거나 외부 시스템의 API를 실행한다면 도메인 영역의 도메인 서비스는 인터페이스로 추상화해야 한다.
이를 통해 도메인 영역이 특정 구현에 종속되는 것을 방지할 수 있고 도메인 영역에 대한 테스트가 쉬워진다.
Chapter8. 애그리거트 트랜잭션 관리
애그리거트와 트랜잭션
한 주문 애그리거트에 대해 운영자가 배송 상태로 변경할 때 사용자가 배송지 주소를 변경하면 어떻게 될까?
트랜잭션마다 레포지터리는 새로운 애그리거트 객체를 생성하므로 운영자 스레드와 고객 스레드는 개념적으로 동일한 애그리거트지만 물리적으로 서로 다른 애그리거트 객체를 사용한다.
두 스레드는 각각 트랜잭션을 커밋할 때 수정한 내용을 DB에 반영한다.
이 순서의 문제점은 운영자는 기존 배송지 정보를 이용해서 배송 상태로 변경했는데, 그 사이 고객은 배송지 정보를 변경하면서 애그리거트의 일관성이 깨진다는 것이다.
애그리거트를 위한 추가적인 트랜잭션 처리 기법인 선점 잠금과 비선점 잠금이 필요하다.
선점 잠금
선점 잠금은 먼저 애그리거트를 구한 스레드가 애그리거트 사용이 끝날 때까지 다른 스레드가 해당 애그리거트를 수정하지 못하게 블로킹하는 방식이다.
한 스레드가 애그리거트를 구하고 수정하는 동안 다른 스레드가 수정할 수 없으므로 동시에 애그리거트를 수정할 때 발생하는 데이터 충돌 문제를 해소할 수 있다.
선점 잠금은 보통 DBMS가 제공하는 행단위 잠금을 사용해서 구현한다.
오라클을 비롯한 다수의 DBMS가 for update와 같은 쿼리를 사용해서 특정 레코드에 한 커넥션만 접근할 수 있는 잠금장치를 제공한다.
JPA EntityManager는 LockModeType을 인자로 받는 find() 메서드를 제공하며 LockModeType.PESSIMISTIC_WRITE를 값으로 전달하면 해당 엔티티와 매핑된 테이블을 이용해서 선점 잠금 방식을 적용할 수 있다.
JPA 프로바이더와 DBMS에 따라 잠금 모드 구현이 다르며, 하이버네이트의 경우 PESSIMISTIC_WRITE를 잠금 모드로 사용하면 for update 쿼리를 이용해서 선점 잠금을 구현하고 스프링 데이터 JPA는 @Lock 어노테이션을 사용해서 잠금 모드를 지정한다.
선점 잠금과 교착 상태
선점 잠금 기능을 사용할 때는 잠금 순서에 따른 교착 상태가 발생하지 않도록 주의해야 한다.
이런 문제가 발생하지 않도록 하려면 잠금을 구할 때 최대 대기 시간을 지정해야 한다.
Map<String, Object> hints = new HashMap<>();
hints.put("javax.persistence.lock.timeout", 2000);
Order order = entityManager.find(Order.class, orderNo, LockModeType.PESSIMISTIC_WRITE, hints);
Java
복사
JPA에서 선점 잠금을 시도할 때 최대 대기 시간을 지정하려면 힌트를 사용한다.
지정한 시간 이내 잠금을 구하지 못하면 익셉션을 발생시킨다.
이 힌트를 사용할 때 주의할 점은 DBMS에 따라 힌트가 적용되지 않을 수도 있다는 것이다.
public interface MemberRepository extends Repository<Member, MemberId> {
@Lock(LockModeType.PESSIPMISTIC_WRITE)
@QueryHints({
@QueryHint(name = "javax.persistence.lock.timeout", value = "2000")
})
@Query("select m from Member m where m.id = :id")
Optional<Member> findByIdForUpdate(@Param("id") MemberId memberId);
}
Java
복사
스프링 데이터 JPA는 @QueryHints 어노테이션을 사용해서 쿼리 힌트를 지정할 수 있다.
비선점 잠금
선점 잠금으로 모든 트랜잭션 충돌 문제가 해결되는 것은 아니다.
운영자가 배송지 정보를 조회하고 배송 상태로 변경하는 사이에 고객이 배송지를 변경하면 운영자는 고객이 변경하기 전 배송지 정보를 이용하여 배송 준비를 한 뒤에 배송 상태로 변경하게 된다.
이 문제를 해결하기 위해 필요한 것이 비선점 잠금이다.
비선점 잠금은 동시에 접근하는 것을 막는 대신 변경한 데이터를 실제 DBMS에 반영하는 시점에 변경 가능 여부를 확인하는 방식이다.
비선점 잠금을 구현하려면 애그리거트에 버전으로 사용할 숫자 타입 프로퍼티를 추가해야 한다.
UPDATE aggtable SET version = version + 1, colx = ?, coly = ?
WHERE aggid = ? and version = 현재버전
SQL
복사
이 쿼리는 수정할 애그리거트와 매핑되는 테이블의 버전 값이 현재 애그리거트의 버전과 동일한 경우에만 데이터를 수정하고 수정에 성공하면 버전 값을 1 증가시킨다.
다른 트랜잭션이 먼저 데이터를 수정해서 버전 값이 바뀌면 데이터 수정에 실패하게 된다.
@Entity
@Table(name = "purchase_order")
@Access(AccessType.FIELD)
public class Order {
@Version
private long version;
}
Java
복사
JPA는 버전으로 사용할 필드에 @Version 어노테이션을 붙이고 매핑되는 테이블에 버전을 저장할 컬럼을 추가하면 된다.
JPA는 엔티티가 변경되어 UPDATE 쿼리를 실행할 때 @Version에 명시한 필드를 이용해서 비선점 잠금 쿼리를 실행한다.
트랜잭션이 종료되는 시점에 충돌이 발생하면 OptimisticLockingFailureException이 발생한다.
강제 버전 증가
애그리거트에 애그리거트 루트 외에 다른 엔티티가 존재하는데 기능 실행 도중 루트가 아닌 다른 엔티티의 값만 변경된다고 하자.
연관된 엔티티의 값이 변경된다고 해도 루트 엔티티 자체의 값은 바뀌는 것이 없으므로 루트 엔티티의 버전 값은 증가되지 않는다.
그런데 애그리거트 관점에서 보면 루트 엔티티의 값이 바뀌지 않았더라도 애그리거트의 구성요소 중 일부 값이 바뀌면 논리적으로 그 애그리거트는 바뀐 것이다.
JPA는 이런 문제를 처리할 수 있도록 find() 메서드로 엔티티를 구할 때 강제로 버전 값을 증가시키는 잠금 모드를 지원한다.
@Repository
public class JpaOrderRepository implements OrderRepository {
@PersistenceContext
private EntityManager entityManager;
@Override
public Order findByIdOptimisticLockMode(OrderNo id) {
return entityManager.find(Order.class, id, LockModeType.OPTIMISTIC_FORCE_INCREMENT);
}
}
Java
복사
LockModeType.OPTIMISTIC_FORCE_INCREMENT를 사용하면 해당 엔티티의 상태가 변경되었는지에 상관없이 트랜잭션 종료 시점에 버전 값 증가 처리를 한다.
오프라인 선점 잠금
아틀라시안의 컨플루언스는 문서를 편집할 때 누군가 먼저 편집을 하는 중이면 다른 사용자가 문서를 수정하고 있다는 안내 문구를 보여준다.
한 트랜잭션 범위에서만 적용되는 선점 잠금 방식이나 나중에 버전 충돌을 확인하는 비선점 잠금 방식으로는 이를 구현할 수 없다.
이때 필요한 것이 오프라인 선점 잠금 방식이다.
단일 트랜잭션에서 동시 변경을 막는 선점 잠금 방식과 달리 오프라인 선점 잠금은 여러 트랜잭션에 걸쳐 동시 변경을 막는다.
첫 번째 트랜잭션을 시작할 때 오프라인 잠금을 선점하고, 마지막 트랜잭션에서 잠금을 해제한다.
잠금을 해제하기 전까지 다른 사용자는 잠금을 구할 수 없다.
예를 들어 수정 기능은 두 개의 트랜잭션으로 구성된다.
첫 번째 트랜잭션은 폼을 보여주고, 두 번째 트랜잭션은 데이터를 수정한다.
사용자 A가 수정 요청을 수행하지 않고 프로그램을 종료하면 잠금을 해제하지 않으므로 다른 사용자는 영원히 잠금을 구할 수 없는 상황이 발생한다.
이런 사태를 방지하기 위해 오프라인 선점 방식은 잠금 유효 시간을 가져야 한다.
사용자 A가 잠금 유효 시간이 지난 후 1초 뒤에 수정 요청을 하면 잠금이 해제되어 수정에 실패하게 된다.
이런 상황을 만들지 않으려면 일정 주기로 유효 시간을 증가시키는 방식이 필요하다.
오프라인 선점 잠금을 위한 LockManager 인터페이스와 관련 클래스
오프라인 선점 잠금은 크게 잠금 선점 시도, 잠금 확인, 잠금 해제, 잠금 유효시간 연장의 네 가지 기능이 필요하다.
public interface LockManager {
LockId tryLock(String type, String id) throw LockException;
void checkLock(LockId lockId) throw LockException;
void releaseLock(LockId lockId) throw LockException;
void extendLockExpiration(LockId lockId, long inc) throw LockException;
}
Java
복사
예를 들어 식별자가 10인 Article에 대한 오프라인 선점 잠금이 필요하면 tryLock() 에 Article을 type 값으로 주고 10을 id 값으로 주어 잠금을 시도한다.
public class Service {
public DataAndLockId getDataWithLock(Long id) {
LockId lockId = lockManager.tryLock("data", id);
Data data = repository.findById(id)
return new DataAndLockId(data, lockId);
}
public void edit(EditRequest req, LockId lockId) {
lockManager.checkLock(lockId);
...
lockManager.releaseLock(lockId);
}
}
Java
복사
오프라인 선점 잠금을 이용하여 데이터 수정 폼에 동시에 접근하는 것을 제어하는 코드의 예이다.
데이터를 조회할 때 잠금을 선점하는데 실패하면 LockException이 발생하고 다른 사용자가 데이터를 수정 중이니 나중에 다시 시도하라느 안내 화면을 보여줄 수 있다.
데이터를 수정할 땐 조회하면서 함께 받았던 LockId를 이용하여 잠금이 유효한지 확인한다.
Chapter9. 도메인 모델과 바운디드 컨텍스트
도메인 모델과 경계
처음 도메인 모델을 만들 때 빠지기 쉬운 함정이 도메인을 완벽하게 표현하는 단일 모델을 만드는 시도를 하는 것이다.
한 도메인은 다시 여러 하위 도메인으로 구분되기 때문에 한 개의 모델로 여러 하위 도메인을 모두 표현하려고 시도하면 오히려 모든 하위 도메인에 맞지 않는 모델을 만들게 된다.
하위 도메인마다 같은 용어라도 의미가 다르고 같은 대상이라도 지칭하는 용어가 다를 수 있기 때문에 한 개의 모델로 모든 하위 도메인을 표현하려는 시도는 올바른 방법이 아니며 표현할 수도 없다.
하위 도메인마다 사용하는 용어가 다르기 때문에 올바른 도메인 모델을 개발하려면 하위 도메인마다 모델을 만들어야 한다.
각 모델은 특정한 컨텍스트(문맥) 하에서 완전한 의미를 갖기 때문에 명시적으로 구분되는 경계를 가져서 섞이지 않도록 해야 한다.
이렇게 구분되는 경계를 갖는 컨텍스트를 DDD에서는 바운디드 컨텍스트라고 부른다.
바운디드 컨텍스트
바운디드 컨텍스트는 모델의 경계를 결정하며 한 개의 바운디드 컨텍스트는 논리적으로 한 개의 모델을 갖는다.
바운디드 컨텍스트는 용어를 기준으로 구분하며 실제로 사용자에게 기능을 제공하는 물리적 시스템으로 도메인 모델은 이 바운디드 컨텍스트 안에서 도메인을 구현한다.
이상적으로 하위 도메인과 바운디드 컨텍스트가 일대일 관계를 가지면 좋겠지만 그렇지 않을 때가 많다.
여러 하위 도메인을 하나의 바운디드 컨텍스트에서 개발할 때 주의할 점은 하위 도메인의 모델이 섞이지 않도록 하는 것이다.
비록 한 개의 바운디드 컨텍스트가 여러 하위 도메인을 포함하더라도 하위 도메인마다 구분되는 패키지를 갖도록 구현해야 하며, 이렇게 함으로써 하위 도메인을 위한 모델이 서로 뒤섞이지 않고 하위 도메인마다 바운디드 컨텍스트를 갖는 효과를 낼 수 있다.
바운디드 컨텍스트는 도메인 모델을 구분하는 경계가 되기 때문에 바운디드 컨텍스트는 구현하는 하위 도메인에 알맞은 모델을 포함한다.
같은 사용자라 하더라도 주문 바운디드 컨텍스트와 회원 바운디드 컨텍스트가 갖는 모델이 달라진다.
바운디드 컨텍스트 구현
바운디드 컨텍스트가 도메인 모델만 포함하는 것은 아니다.
바운디드 컨텍스트는 도메인 기능을 사용자에게 제공하는데 필요한 표현 영역, 응용 서비스, 인프라스트럭처 영역을 모두 포함한다.
도메인 모델의 데이터 구조가 바뀌면 DB 테이블 스키마도 함께 변경해야 하므로 테이블도 바운디드 컨텍스트에 포함된다.
모든 바운디드 컨텍스트를 반드시 도메인 주도로 개발할 필요는 없다.
서비스-DAO 구조를 사용하면 도메인 기능이 서비스에 흩어지게 되지만 도메인 기능 자체가 단순하면 서비스-DAO로 구성된 CRUD 방식을 사용해도 코드를 유지 보수 하는데 문제가 되지 않는다고 생각한다.
한 바운디드 컨텍스트에서 두 방식을 혼합해서 사용할 수도 있으며 대표적인 예가 CQRS 패턴이다.
각 바운디드 컨텍스트는 서로 다른 구현 기술을 사용할 수도 있으며 반드시 사용자에게 보여지는 UI를 가지고 있어야 하는 것은 아니다.
바운디드 컨텍스트 간 통합
기존 카탈로그 시스템을 개발하던 팀과 별도로 추천 시스템을 담당하는 팀이 새로 생겨서 이 티멩서 주도적으로 추천 시스템을 만들기로 했다.
이렇게 되면 카탈로그 하위 도메인에는 기존 카탈로그를 위한 바운디드 컨텍스트와 추천 기능을 위한 바운디드 컨텍스트가 생긴다.
카탈로그와 추천 바운디드 컨텍스트 간 통합이 필요한 기능은 다음과 같다.
•
사용자가 제품 상세 페이지를 볼 때, 보고 있는 상품과 유사한 상품 목록을 하단에 보여준다.
카탈로그 시스템은 추천 시스템으로부터 추천 데이터를 받아오지만, 카탈로그 시스템에서는 추천의 도메인 모델을 사용하기보다는 카탈로그 도메인 모델을 사용해서 추천 상품을 표현해야 한다.
REST API를 호출하는 것은 두 바운디드 컨텍스트를 직접 통합하는 방식이다.
직접 통합하는 대신 간접적으로 통합하는 대표적인 방법으로는 메세지 큐를 사용하는 것이다.
추천 시스템은 사용자가 조회한 상품 이력이나 구매 이력과 같은 사용자 활동 이력을 필요로 하는데 이 내력을 전달할 때 메세지 큐를 사용할 수 있다.
두 바운디드 컨텍스트를 개발하는 팀은 메세징 큐에 담을 데이터의 구조를 협의하게 되는데 그 큐를 누가 제공하느냐에 따라 데이터 구조가 결정된다.
바운디드 컨텍스트 간 관계
바운디드 컨텍스트는 어떤 식으로든 연결되기 때문에 두 바운디드 컨텍스트는 다양한 방식으로 관계를 맺는다.
두 바운디드 컨텍스트 간 관계 중 가장 흔한 관계는 한쪽에서 API를 제공하고 다른 한쪽에서 그 API를 호출하는 관계이며 REST API가 대표적이다.
공개 호스트 서비스
이 관계에서 하류 컴포넌트(API를 사용하는 바운디드 컨텍스트)는 상류 컴포넌트(API를 제공하는 바운디드 컨텍스트)에 의존하게 된다.
상류 팀의 고객인 하류 팀이 다수 존재하면 상류 팀은 여러 하류 팀의 요구사항을 수용할 수 있는 API를 만들고 이를 서비스 형태로 공개해서 서비스의 일관성을 유지할 수 있다.
도메인 모델
상류 컴포넌트의 서비스는 상류 바운디드 컨텍스트의 도메인 모델을 따른다.
따라서 하류 컴포넌트는 상류 서비스의 모델이 자신의 도메인 모델에 영향을 주지 않도록 보호해 주는 완충 지대를 만들어야 한다.
두 바운디드 컨텍스트가 같은 모델을 공유하는 경우도 있으며 공유 커널이라고 부른다.
공유 커널의 장점은 중복을 줄여준다는 것이지만 두 팀이 한 모델을 공유하기 때문에 한 팀에서 임의로 모델을 변경하면 안 되며 두 팀이 밀접한 관계를 유지해야 한다.
독립 방식
독립 방식 관계는 두 바운디드 컨텍스트 간에 통합하지 않고 서로 독립적으로 모델을 발전시키는 방식이다.
독립 방식에서 두 바운디드 컨텍스트 간의 통합은 수동으로 이루어진다.
규모가 커질수록 수동 통합에는 한계가 있으므로 두 바우니듣 컨텍스트를 통합해야 한다.
이때 외부에서 구매한 솔루션과 ERP를 완전히 대체할 수 없다면 두 바운디드 컨텍스트를 통합해 주는 별도의 시스템을 만들어야 할 수도 있다.
컨텍스트 맵
개별 바운디드 컨텍스트에 매몰되면 전체를 보지 못할 때가 있다.
나무만 보고 숲을 보지 못하는 상황을 방지하려면 전체 비즈니스를 조망할 수 있는 지도가 필요한데 그것이 바로 컨텍스트 맵이다.
컨텍스트 맵은 시스템의 전체 구조를 보여준다.
이는 하위 도메인과 일치하지 않는 바운디드 컨텍스트를 찾아 도메인에 맞게 바운디드 컨텍스트를 조절하고 사업의 핵심 도메인을 위해 조직 역량을 어떤 바운디드 컨텍스트에 집중할지 파악하는데 도움을 준다.
Chapter10. 이벤트
시스템 간 강결합 문제
쇼핑몰에서 구매를 취소하면 환불을 처리해야 한다.
보통 결제 시스템은 외부에 존재하므로 환불 도메인 서비스는 외부에 있는 결제 시스템이 제공하는 환불 서비스를 호출한다.
이때 여러 가지 문제가 발생할 수 있다.
•
외부 서비스가 정상이 아닐 경우 트랜잭션 처리를 어떻게 해야 할지 에매하다.
외부의 환불 서비스를 실행하는 과정에서 익셉션이 발생하면 환불에 실패했으므로 주문 취소 트랜잭션을 롤백하는 것이 맞아 보인다.
하지만 반드시 트랜잭션을 롤백해야 하는 것은 아니다.
주문은 취소 상태로 변경하고 환불만 나중에 다시 시도하는 방식으로 처리할 수도 있다.
•
환불을 처리하는 외부 시스템의 응답 시간이 길어지면 그만큼 대기 시간도 길어진다.
환불 처리 기능이 30초가 걸리면 주문 취소 기능은 30초만큼 대기 시간이 증가하므로 외부 서비스 성능의 직접적인 영향을 받게 된다.
•
도메인 객체에 서비스를 전달하면 주문 로직과 결제 로직이 섞여서 설계상 문제가 나타날 수 있다.
주문 도메인 객체의 코드를 결제 도메인 때문에 변경할지도 모르는 상황은 좋아 보이지 않는다.
환불 도메인 서비스와 동일하게 파라미터로 통지 서비스를 받도록 구현하면 로직이 섞이는 문제가 더 커지고 트랜잭션 처리가 더 복잡해지며 영향을 주는 외부 서비스가 두 개로 증가한다.
지금까지 언급한 문제가 발생하는 이유는 바운디드 컨텍스트 간의 강결합 때문이다.
이벤트를 사용하면 두 시스템 간의 결합을 크게 낮출 수 있다.
이벤트 개요
이벤트라는 용어는 ‘과거에 벌어진 어떤 것’을 의미한다.
이벤트 관련 구성요소
도메인 모델에 이벤트를 도입하려면 네 개의 구성요소인 이벤트, 이벤트 생성 주체, 이벤트 디스패처(퍼블리셔), 이벤트 핸들러(구독자)를 구현해야 한다.
도메인 모델에서 이벤트 생성 주체는 엔티티, 밸류, 도메인 서비스와 같은 도메인 객체이다.
이들 도메인 객체는 도메인 로직을 실행해서 상태가 바뀌면 관련 이벤트를 발생시킨다.
이벤트 핸들러는 이벤트 생성 주체가 발생한 이벤트에 반응하며 이벤트를 전달받아 이벤트에 담긴 데이터를 이용해서 원하는 기능을 실행한다.
이벤트 생성 주체와 이벤트 핸들러를 연결해 주는 것이이벤트 디스패처다.
이벤트 생성 주체는 이벤트를 생성해서 디스패처에 이벤트를 전달하며 디스패처는 해당 이벤트를 처리할 수 있는 핸들러에 이벤트를 전파한다.
이벤트 디스패처의 구현 방식에 따라 이벤트 생성과 처리를 동기나 비동기로 실행하게 된다.
이벤트의 구성
이벤트는 발생한 이벤트에 대한 정보를 담는다.
•
이벤트 종류 (클래스 이름으로 이벤트 종류를 표현)
•
이벤트 발생 시간
•
추가 데이터 (이벤트와 관련된 정보)
이벤트는 이벤트 핸들러가 작업을 수행하는데 필요한 데이터를 담아야 한다.
이 데이터가 부족하면 핸들러는 필요한 데이터를 읽기 위해 관련 API를 호출하거나 DB에서 데이터를 직접 읽어와야 한다.
이벤트 용도
이벤트는 크게 두 가지 용도로 쓰인다.
•
트리거
도메인 상태가 바뀔 때 다른 후처리가 필요하면 후처리를 실행하기 위한 트리거로 이벤트를 사용할 수 있다.
•
서로 다른 시스템 간의 데이터 동기화
주문 도메인은 배송지 변경 이벤트를 발생시키고 이벤트 핸들러는 외부 배송 서비스와 배송지 정보를 동기화할 수 있다.
이벤트 장점
이벤트를 사용하면 서로 다른 도메인 로직이 섞이는 것을 방지할 수 있으며 도메인 간의 의존을 제거할 수 있다.
이벤트 핸들러를 사용하면 기능 확장을 할 때 핸들러를 구현하기만 하면 되므로 용이하다.
이벤트, 핸들러, 디스패처 구현
이벤트 클래스
이벤트 자체를 위한 상위 타입은 존재하지 않는다.
이벤트 클래스의 이름을 결정할 때에는 과거 시제를 사용해야 한다는 점만 유의하면 원하는 클래스를 이벤트로 사용하면 된다.
모든 이벤트가 공통으로 갖는 프로퍼티가 존재한다면 관련 상위 클래스를 만들고 각 이벤트 클래스가 상속받도록 할 수 있다.
Events 클래스와 ApplicationEventPublisher
이벤트 발생과 출판을 위해 스프링이 제공하는 ApplicationPublisher를 사용한다.
Events 클래스는 ApplicationEventPublisher를 사용해서 이벤트를 발생시키도록 구현할 것이다.
public class Events {
private static ApplicationEventPublisher publisher;
static void setPublisher(ApplicationEventPublisher publisher) {
Events.publisher = publisher;
}
public static void raise(Object event) {
if (publisher != null) {
publisher.publishEvent(event);
}
}
}
Java
복사
Events 클래스의 raise() 메서드는 ApplicationEventPublisher가 제공하는 publishEvent() 메서드를 이용해서 이벤트를 발생시킨다.
@Configuration
public class EventsConfiguration {
@Autowired
private ApplicationContext applicationContext;
@Bean
public InitializingBean eventsInitializer() {
return () -> Events.setPublisher(applicationContext);
}
}
Java
복사
setPublisher() 메서드에 이벤트 퍼블리셔를 전달하기 위해 스프링 설정 클래스를 작성한다.
eventInitializer() 메서드는 InitializingBean 타입 객체를 빈으로 설정한다.
이 타입은 스프링 빈 객체를 초기화할 때 사용하는 인터페이스로 Events 클래스를 초기화한다.
참고로 ApplicationContext는 ApplicationEventPublisher를 상속한다.
이벤트 발생과 이벤트 핸들러
이벤트를 발생시킬 코드는 Events.raise() 메서드를 사용한다.
이벤트를 처리할 핸들러는 스프링이 제공하는 @EventListener 어노테이션을 사용해서 구현한다.
ApplicationEventPublisher.publishEvent() 메서드를 실행할 때 Events 타입 객체를 전달하면 해당 Events.class 값을 갖는 @EventListener 어노테이션을 붙인 메서드를 찾아 실행한다.
흐름 정리
1.
도메인 기능을 실행한다.
2.
도메인 기능은 Events.raise() 를 이용해서 이벤트를 발생시킨다.
3.
Events.raise() 는 스프링이 제공하는 ApplicationEventPublisher를 이용해서 이벤트를 출판한다.
4.
ApplicationEventPublisher는 @EventListener(Events.class) 어노테이션이 붙은 메서드를 찾아 실행한다.
코드 흐름을 보면 응용 서비스와 동일한 트랜잭션 범위에서 이벤트 핸들러를 실행하고 있다.
즉, 도메인 상태 변경과 이벤트 핸들러는 같은 트랜잭션 범위에서 실행된다.
동기 이벤트 처리 문제
이벤트를 사용해서 강결합 문제는 해소했지만 외부 서비스에 영향을 받는 문제는 아직 남아 있다.
외부 서비스의 성능 저하가 내 시스템의 성능 저하로 연결되는 것뿐만 아니라 외부 서비스 실행에 실패했다고 해서 반드시 트랜잭션을 롤백 해야 하는지에 대한 문제다.
외부 시스템과의 연동을 동기로 처리할 때 발생하는 성능과 트랜잭션 범위 문제를 해소하는 방법은 이벤트를 비동기로 처리하거나 이벤트와 트랜잭션을 연계하는 것이다.
비동기 이벤트 처리
우리가 구현해야 할 것 중에서 ‘A하면 이어서 B 하라’는 내용을 담고 있는 요구사항은 실제로 ‘A하면 최대 언제까지 B하라’인 경우가 많다.
즉, 일정 시간 안에만 후속 조치를 처리하면 되는 경우가 적지 않다.
게다가 ‘A하면 이어서 B하라’는 요구사항에서 B를 하는데 실패하면 일정 간격으로 재시도를 하거나 수동 처리를 해도 상관없는 경우가 있다.
‘A하면 이어서 B하라’는 요구사항 중에서 ‘A하면 최대 언제까지 B하라’로 바꿀 수 있는 요구사항은 이벤트를 비동기로 처리하는 방식으로 구현할 수 있다.
로컬 핸들러 비동기 실행
이벤트 핸들러를 비동기로 실행하는 방법은 이벤트 핸들러를 별도 스레드로 실행하는 것이다.
@EnableAsync
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
Java
복사
@Service
public class EventHandler {
@Async
@EventListener(Event.class)
public void handle(Event event) {
service.usecase(event.getId());
}
}
Java
복사
스프링이 제공하는 @Async 어노테이션을 사용하면 손쉽게 비동기로 이벤트 핸들러를 실행할 수 있다.
메시징 시스템을 이용한 비동기 구현
비동기로 이벤트를 처리해야 할 때 사용하는 또 다른 방법은 카프카나 래빗MQ와 같은 메시징 시스템을 사용하는 것이다.
이벤트가 발생하면 이벤트 디스패처는 이벤트를 메시지 큐에 보낸다.
메시지 큐는 이벤트를 메시지 리스너에 전달하고, 메시지 리스너는 알맞은 이벤트 핸들러를 이용해서 이벤트를 처리한다.
이때 이벤트를 메시지 큐에 저장하는 과정과 메시지 큐에서 이벤트를 읽어와 처리하는 과정은 별도 스레드나 프로세스로 처리된다.
필요하다면 이벤트를 발생시키는 도메인 기능과 메시지 큐에 이벤트를 저장하는 절차를 한 트랜잭션으로 묶어야 한다.
글로벌 트랜잭션을 사용하면 안전하게 이벤트를 메시지 큐에 전달할 수 있는 장점이 있지만 반대로 글로벌 트랜잭션으로 인해 전체 성능이 떨어진다는 단점도 있으며 글로벌 트랜잭션을 지원하지 않는 메시징 시스템도 있다.
메시지 큐를 사용하면 보통 이벤트를 발생시키는 주체와 이벤트 핸들러가 별도 프로세스에서 동작하는데 이것은 이벤트 발생 JVM과 이벤트 처리 JVM이 다르다는 것을 의미한다.
동일 JVM에서 비동기 처리를 위해 메시지 큐를 사용하는 것은 시스템을 복잡하게 만들뿐이다.
이벤트 저장소를 이용한 비동기 처리
•
포워더 이용
이벤트를 비동기로 처리하는 또 다른 방법은 이벤트를 일단 DB에 저장한 뒤에 별도 프로그램을 이용해서 이벤트 핸들러에 전달하는 것이다.
이벤트가 발생하면 핸들러는 스토리지에 이벤트를 저장한다.
포워더는 주기적으로 이벤트 저장소에서 이벤트를 가져와 이벤트 핸들러를 실행한다.
포워더는 별도 스레드를 이용하기 때문에 이벤트 발행과 처리가 비동기로 처리된다.
이 방식은 도메인의 상태와 이벤트 저장소로 동일한 DB를 사용하기 때문에 도메인의 상태 변화와 이벤트 저장이 로컬 트랜잭션으로 처리된다.
이벤트를 물리적 저장소에 보관하기 때문에 핸들러가 이벤트 처리에 실패할 경우 포워더는 다시 이벤트 저장소에서 이벤트를 읽어와 핸들러를 실행하면 된다.
•
API 이용
API 방식과 포워더 방식의 차이점은 이벤트를 전달하는 방식에 있다.
포워더 방식이 포워더를 이용해서 이벤트를 외부에 전달한다면, API 방식은 외부 핸들러가 API 서버를 통해 이벤트 목록을 가져간다.
포워더 방식은 이벤트를 어디까지 처리했는지 추적하는 역할이 포워더에 있다면 API 방식에서는 이벤트 목록을 요구하는 외부 핸들러가 자신이 어디까지 이벤트를 처리했는지 기억해야 한다.
이벤트 적용 시 추가 고려 사항
1.
이벤트 소스를 EventEntry에 추가할지 여부
‘Order가 발생시킨 이벤트만 조회하기’처럼 특정 주체가 발생시킨 이벤트만 조회하는 기능을 구현하려면 이벤트에 발생 주체 정보를 추가해야 한다.
2.
포워더에서 전송 실패를 얼마나 허용할 것이냐에 대한 것
포워더는 이벤트 전송에 실패하면 실패한 이벤트부터 다시 읽어와 전송을 시도한다.
특정 이벤트에서 계속 전송에 실패하면 나머지 이벤트를 전송할 수 없게 된다.
따라서 포워더를 구현할 때는 실패한 이벤트의 재전송 횟수 제한을 두어야 한다.
3.
이벤트 손실에 대한 것
이벤트 저장소를 사용하는 방식은 이벤트 발생과 이벤트 저장을 한 트랜잭션으로 처리하기 때문에 트랜잭션에 성공하면 이벤트 저장소에 보관된다는 것을 보장할 수 있다.
반면에 로컬 핸들러를 이용해서 이벤트를 비동기로 처리할 경우 이벤트 처리에 실패하면 이벤트를 유실하게 된다.
4.
이벤트 순서에 대한 것
이벤트 발생 순서대로 외부 시스템에 전달해야 할 경우 이벤트 저장소를 사용하는 것이 좋다.
반면에 메시징 시스템은 사용 기술에 따라 이벤트 발생 순서와 메시지 전달 순서가 다를 수도 있다.
5.
이벤트 재처리에 대한 것
동일한 이벤트를 다시 처리해야 할 때 이벤트를 어떻게 할지 결정해야 한다.
가장 쉬운 방법은 마지막으로 처리한 이벤트의 순번을 기억해 두었다가 이미 처리한 순번의 이벤트가 도착하면 해당 이벤트를 처리하지 않고 무시하는 것이다.
이 외에도 이벤트를 멱등으로 처리하는 방법도 있다.
이벤트 처리와 DB 트랜잭션 고려
외부 시스템을 사용할 경우 이벤트 처리를 동기로 하든 비동기로 하든 이벤트 처리 실패와 트랜잭션 실패를 함께 고려해야 한다.
트랜잭션 실패와 이벤트 처리 실패를 모두 고려하면 복잡해지므로 트랜잭션이 성공할 때만 이벤트 핸들러를 실행하는 방법으로 경우의 수를 줄이면 도움이 된다.
@TransactionalEventListener(
classes = Event.class,
phase = TransactionalPhase.AFTER_COMMIT
)
public void handle(Event event) {
service.usecase(event.getId());
}
Java
복사
스프링은 @TransactionalEventListener 어노테이션을 지원한다.
이 어노테이션은 스프링 트랜잭션 상태에 따라 이벤트 핸들러를 실행할 수 있게 한다.
phase의 속성 값으로 AFTER_COMMIT을 지정하면 스프링은 트랜잭션 커밋에 성공한 뒤에 핸들러 메서드를 실 행하고 중간에 에러가 발생해서 트랜잭션이 롤백되면 핸들러 메서드를 실행하지 않는다.
이벤트 저장소로 DB 를 사용해도 동일한 효과를 볼 수 있다.
이벤트 발생 코드와 이벤트 저장 처리를 한 트랜잭션으로 처리하면 트랜잭션이 성공할 때만 이벤트가 DB에 저장되므로 트랜잭션은 실패했는데 이벤트 핸들러가 실행되는 상황은 발생하지 않는다.
Chapter11. CQRS
단일 모델의 단점
시스템이 제공하는 기능은 크게 두 가지로 나눌 수 있다.
•
상태를 변경하는 기능
현재 저장하고 있는 데이터를 변경하는 방식으로 기능을 구현한다.
•
사용자 입장에서 상태 정보를 조회하는 기능
필요한 데이터를 읽어와 UI를 통해 보여주는 방식으로 구현한다.
도메인 모델 관점에서 상태 변경 기능은 주로 한 애그리거트의 상태를 변경한다.
반면에 조회 기능에 필요한 데이터를 표시하려면 두 개 이상의 애그리거트가 필요할 때가 많다.
객체 지향으로 도메인 모델을 구현할 때 주로 사용하는 ORM 기법은 도메인 상태 변경 기능을 구현하는 데는 적합하지만 여러 애그리거트에서 데이터를 가져와 출력하는 기능을 구현하기에는 고려할게 많아서 구현을 복잡하게 만드는 원인이 된다.
이런 고민이 발생하는 이유는 시스템 상태를 변경할 때와 조회할 때 단일 도메인 모델을 사용하기 때문이다.
단일 모델을 사용할 때 발생하는 복잡도를 해결하기 위해 사용하는 방법이 CQRS이다.
CQRS
CQRS는 상태를 변경하는 명령을 위한 모델과 상태를 제공하는 조회를 위한 모델을 분리하는 패턴이다.
CQRS를 사용하면 각 모델에 맞는 구현 기술을 선택할 수 있다.
예를 들어 명령 모델은 객체 지향에 기반해서 도메인 모델을 구현하기에 적당한 JPA를 사용해서 구현하고, 조회 모델은 DB 테이블에서 SQL로 데이터를 조회할 때 좋은 마이바티스를 사용해서 구현하면 된다.
명령 모델은 상태를 변경을 위한 객체 기반 도메인 모델을 이용해서 도메인 로직을 수행하는데 초점을 맞춰 설계하고, 조회 모델은 화면에 보여줄 필요한 정보를 담고 있는 데이터 타입에 초점을 맞춰 설계한다.
명령 모델과 조회 모델이 서로 다른 데이터 저장소를 사용할 수도 있다.
명령 모델은 트랜잭션을 지원하는 RDBMS를 사용하고, 조회 모델은 조회 성능이 좋은 메모리 기반 NoSQL을 사용할 수 있을 것이다.
웹과 CQRS
일반적인 웹 서비스는 상태를 변경하는 요청보다 상태를 조회하는 요청이 많다.
조회 기능 요청 비율이 월등히 높은 서비스를 만드는 개발팀은 조회 성능을 높이기 위해 다양한 기법을 사용한다.
기본적으로 쿼리를 최적화해서 쿼리 실행 속도 자체를 높이고, 메모리에 조회 데이터를 캐싱 해서 응답 속도를 높이기도 하고, 조회 전용 저장소를 따로 사용하기도 한다.
이렇게 조회 성능을 높이기 위해 다양한 기법을 사용하는 것은 결과적으로 알게 모르게 CQRS를 적용하는 것과 같은 효과를 만든다.
조회 속도를 높이기 위해 별도 처리를 하고 있다면 명시적으로 명령 모델과 조회 모델을 구분하자.
이를 통해 조회 기능 때문에 명령 모델이 복잡해지는 것을 막을 수 있고, 명령 모델에 관계없이 조회 기능에 특화된 구현 기법을 보다 쉽게 적용할 수 있다.
CQRS 장단점
•
장점
◦
명령 모델을 구현할 때 도메인 자체에 집중할 수 있다는 점이다.
복잡한 도메인은 주로 상태 변경 로직이 복잡한데 명령 모델과 조회 모델을 구분하면 조회 성능을 위한 코드가 명령 모델에 없으므로 도메인 로직을 구현하는데 집중할 수 있다.
◦
조회 성능을 향상시키는데 유리하다는 점이다.
조회 단위로 캐시 기술을 적용할 수 있고, 조회에 특화된 쿼리를 마음대로 사용할 수도 있다.
캐시뿐만 아니라 조회 전용 저장소를 사용하면 조회 처리량을 대폭 늘릴 수도 있다.
조회 전용 모델을 사용하기 때문에 조회 성능을 높이기 위한 코드가 명령 모델에 영향을 주지 않는다.
•
단점
◦
구현해야 할 코드가 더 많다는 점이다.
단일 모델을 사용할 때 발생하는 복잡함 때문에 발생하는 구현 비용과 조회 전용 모델을 만들 때 발생하는 구현 비용을 따져봐야 한다.
도메인이 복잡하거나 대규모 트래픽이 발생하는 서비스라면 조회 전용 모델을 만드는 것이 향후 유지 보수에 유리하다.
◦
더 많은 구현 기술이 필요하다는 것이다.
명령 모델과 조회 모델을 다른 구현 기술을 사용해서 구현하기도 하고 경우에 따라 다른 저장소를 사용하기도 한다.
또한 데이터 동기화를 위해 메시징 시스템을 도입해야 할 수도 있다.
이러한 장단점을 고려해서 CQRS 패턴을 도입할지 여부를 결정해야 한다.
도메인이 복잡하지 않은데 CQRS를 도입하면 두 모델을 유지하는 비용만 높아지고 얻을 수 있는 이점은 없다.
반면에 트래픽이 높은 서비스인데 단일 모델을 고집하면 유지 보수 비용이 오히려 높아질 수 있다.