
@Annotaion
•
@EventListener(AppllicationReadyEvent.class)
◦
스프링 컨테이너가 완전히 초기화를 다 끝내고, 실행 준비가 되었을 때 해당 메서드를 호출한다.
◦
@PostConstruct를 사용해도 되나 AOP 같은 부분이 처리되지 않은 시점에서 호출될 수도 있다.
•
@Import(MemoryConfig.class)
◦
미리 설정한 MemoryConfig.java 파일을 설정 파일로 사용하며 해당 클래스엔 @Configuration을 붙여야 함
•
@SpringBootApplication(scanBasePackages = “hello.itemservice.web”)
◦
컴포넌트 스캔을 할 경로를 지정한다. (지정된 경로와 그 하위 패키지만 수행한다.)
•
@Profile(”local”)
◦
특정 프로필에 경우에만 해당 스프린 빈을 등록한다.
◦
application.properties에 spring.profiles.active 속성을 읽어서 프로필로 사용한다.
◦
이걸 이용해 main과 test를 따로 사용할 수 있고 프로필을 지정하지 않으면 “default”가 지정된다.
JdbcTemplate
•
장점
◦
spring-jdbc 라이브러리로 스프링으로 JDBC를 사용할 때 기본으로 사용되어 복잡한 설정이 없다.
◦
템플릿 콜백 패턴을 사용해 대부분의 반복 작업을 대신 처리해준다.
•
단점
◦
동적 SQL을 해결하기 어렵다.
private final JdbcTemplate template;
public JdbcTemplateItemRepositoryV1(DataSource dataSource) {
this.template = new JdbcTemplate(dataSource);
}
Java
복사
•
JdbcTemplate는 데이터소스가 필요하다.
•
생성자를 통해 데이터소스 의존관계를 주입 받고 JdbcTemplate를 생성한다.
@Override
public Item save(Item item) {
String sql = "insert into item(item_name, price, quantity) values (?, ?, ?)";
KeyHolder keyHolder = new GeneratedKeyHolder();
template.update(connection -> {
PreparedStatement pstmt = connection.prepareStatement(sql, new String[]{"id"});
pstmt.setString(1, item.getItemName());
pstmt.setInt(2, item.getPrice());
pstmt.setInt(3, item.getQuantity());
return pstmt;
}, keyHolder);
long key = keyHolder.getKey().longValue();
item.setId(key);
return item;
}
Java
복사
•
template.update()
◦
데이터를 변경할 때 사용하며 INSERT, UPDATE, DELETE SQL에 사용한다.
◦
반환 값은 int로 영향 받은 로우 수를 반환한다.
•
ID 생성 전략은 IDENTITY를 사용한다.
◦
데이터베이스가 ID를 대신 생성해주고 INSERT가 완료되어야 ID 값을 확인할 수 있다.
◦
KeyHolder 와 connection → {} 람다식을 통해 INSERT를 미리 실행시키고 ID 값을 조회한다.
@Override
public void update(Long itemId, ItemUpdateDto updateParam) {
String sql = "update item set item_name=?, price=?, quantity=? where id=?";
template.update(sql, updateParam.getItemName(), updateParam.getPrice(), updateParam.getQuantity(), itemId);
}
Java
복사
•
update()를 사용할 때 ?에 바인딩 할 파라미터를 순서대로 전달하며 DTO에서 꺼내서 전달한다.
@Override
public Optional<Item> findById(Long id) {
String sql = "select id, item_name, price, quantity where id=?";
try {
Item item = template.queryForObject(sql, itemRowMapper(), id);
return Optional.of(item);
} catch (EmptyResultDataAccessException e) {
return Optional.empty();
}
}
private RowMapper<Item> itemRowMapper() {
return ((rs, rowNum) -> {
Item item = new Item();
item.setId(rs.getLong("id"));
item.setItemName(rs.getString("item_name"));
item.setPrice(rs.getInt("price"));
item.setQuantity(rs.getInt("quantity"));
return item;
});
}
Java
복사
•
template.queryForObject()
◦
결과 로우가 하나일 때 사용하며 sql, RowMapper, 파라미터를 전달해야 한다.
◦
결과가 없으면 EmptyResultDataAccessException 예외를 터트린다.
◦
결과가 둘 이상이면 IncorrectResultSizeDataAccessException 예외를 터트린다.
•
RowMapper
◦
데이터베이스의 반환 결과인 ResultSet을 객체에 매핑해서 반환한다.
•
Optional
◦
결과가 없으면 Optional.empty() 를 반환하고 있으면 Optional.of()로 감싸서 반환한다.
@Override
public List<Item> findAll(ItemSearchCond cond) {
String itemName = cond.getItemName();
Integer maxPrice = cond.getMaxPrice();
String sql = "select id, item_name, price, quantity from item";
if(StringUtils.hasText(itemName) || maxPrice != null) {
sql += " where";
}
boolean andFlag = false;
List<Object> param = new ArrayList<>();
if(StringUtils.hasText(itemName)) {
sql += " item_name like concat('%', ?, '%')";
param.add(itemName);
andFlag = true;
}
if(maxPrice != null) {
if(andFlag) {
sql += " and";
}
sql += " price <= ?";
param.add(maxPrice);
}
log.info("sql={}", sql);
return template.query(sql, itemRowMapper(), param.toArray());
}
Java
복사
•
template.query()
◦
결과가 하나 이상일 때 사용한다. SELECT SQL에 사용한다.
◦
RowMapper는 ResultSet의 커서에 대한 while문을 돌려 객체에 매핑해 컬렉션으로 반환한다.
•
여기서 if문은 동적 쿼리를 처리하는 부분으로 조건이 많아지면 코드가 복잡해지는 문제점이 있다.
이름 지정 파라미터
•
SQL 에 ? 는 JdbcTemplate를 사용하면 데이터를 순서대로 바인딩한다.
•
파라미터가 많아지게되면 순서가 바뀌게 되고 DB에 데이터가 잘못 들어가게 되는 버그가 발생한다.
private final NamedParameterJdbcTemplate template;
public JdbcTemplateItemRepositoryV2(DataSource dataSource) {
this.template = new NamedParameterJdbcTemplate(dataSource);
}
Java
복사
•
NamedParameterJdbcTemplate와 SqlParameterSource 를 사용하면 해결할 수 있다.
String sql = "insert into item (item_name, price, quantity) values (?, ?, ?)";
String sql = "insert into item (item_name, price, quantity) values (:itemName, :price, :quantity)";
Java
복사
•
SQL에서 “?” 를 “:프로퍼티이름” 으로 바꿔 직접 지정한다.
template.update(sql, param, keyHolder);
template.queryForObject(sql, param, itemRowMapper());
template.query(sql, param, itemRowMapper());
Java
복사
•
template를 이용해 query를 호출할 때 파라미터를 전달해야 한다.
파라미터의 종류
•
Map
String sql = "select id, item_name, price, quantity from item where id=:id";
Map<String, Object> param = Map.of("id", id);
Item item = template.queryForObject(sql, param, itemRowMapper());
Java
복사
◦
단순히 Map을 사용하는 방식 (key는 :프로퍼티이름, value는 값)
•
SqlParameterSource
◦
MapSqlParameterSource
String sql = "update item set item_name=:itemName, price=:price, quantity=:quantity where id=:id";
MapSqlParameterSource param = new MapSqlParameterSource()
.addValue("itemName", updateParam.getItemName())
.addValue("price", updateParam.getPrice())
.addValue("quantity", updateParam.getQuantity())
.addValue("id", itemId);
template.update(sql, param);
Java
복사
▪
Map과 유사하며 SQL 타입을 지정할 수 있는 등 SQL에 좀 더 특화된 기능을 제공한다.
▪
메서드 체인을 통해 편리한 사용을 제공한다.
◦
BeanPropertySqlParameterSource
String sql = "insert into item (item_name, price, quantity) values (:itemName, :price, :quantity)";
SqlParameterSource param = new BeanPropertySqlParameterSource(item);
KeyHolder keyHolder = new GeneratedKeyHolder();
template.update(sql, param, keyHolder);
Java
복사
▪
자바빈 프로퍼티 규약을 통해서 자동으로 파라미터 객체를 생성한다.
getXXX() → XXX
BeanPropertyRowMapper
//전
private RowMapper<Item> itemRowMapper() {
return ((rs, rowNum) -> {
Item item = new Item();
item.setId(rs.getLong("id"));
item.setItemName(rs.getString("item_name"));
item.setPrice(rs.getInt("price"));
item.setQuantity(rs.getInt("quantity"));
return item;
});
}
//후
private RowMapper<Item> itemRowMapper() {
return BeanPropertyRowMapper.newInstance(Item.class);
}
Java
복사
•
ResultSet의 결과를 받아서 자바빈 프로퍼티 규약에 맞춰 데이터를 변환해준다.
별칭
select member_name as username
Java
복사
•
데이터베이스에 컬럼이름은 member_name인데 객체에 프로퍼티 이름이 username인 경우 별칭을 사용
관례 불일치
select item_name -> setItemName()
Java
복사
•
자바는 camelCase를 사용하고 데이터베이스는 snake_case를 사용한다.
•
BeanPropertyRowMapper는 이러한 스네이크 표기법을 카멜 표기법으로 자동으로 변환해준다.
SimpleJdbcInsert
private final NamedParameterJdbcTemplate template;
private final SimpleJdbcInsert jdbcInsert;
public JdbcTemplateItemRepositoryV3(DataSource dataSource) {
this.template = new NamedParameterJdbcTemplate(dataSource);
this.jdbcInsert = new SimpleJdbcInsert(dataSource)
.withTableName("item")
.usingGeneratedKeyColumns("id")
.usingColumns("item_name", "price", "quantity");
}
Java
복사
•
SimpleJdbcInsert 를 주입 받아 사용할 수 있다.
◦
withTableName : 데이터를 저장할 테이블 명을 지정한다.
◦
usingGeneratedKeyColumns : key를 생성하는 PK 컬럼 명을 지정한다.
◦
usingColumns : INSERT SQL에 사용할 컬럼을 지정하며 생략하면 테이블 내 전체 컬럼 지정
JdbcInsert for table [item] compiled
The following parameters are used for call INSERT INTO item (item_name, price, quantity) VALUES(?, ?, ?) with: [org.springframework.jdbc.core.SqlParameterValue@16132f21, org.springframework.jdbc.core.SqlParameterValue@2cd388f5, org.springframework.jdbc.core.SqlParameterValue@4640195a]
Java
복사
•
SimpleJdbcInsert는 생성 시점에 지정된 테이블의 메타 데이터를 조회해 INSERT SQL을 만든다.
//전
@Override
public Item save(Item item) {
String sql = "insert into item (item_name, price, quantity) values (:itemName, :price, :quantity)";
SqlParameterSource param = new BeanPropertySqlParameterSource(item);
KeyHolder keyHolder = new GeneratedKeyHolder();
template.update(sql, param, keyHolder);
long key = keyHolder.getKey().longValue();
item.setId(key);
return item;
}
//후
@Override
public Item save(Item item) {
BeanPropertySqlParameterSource param = new BeanPropertySqlParameterSource(item);
Number key = jdbcInsert.executeAndReturnKey(param);
item.setId(key.longValue());
return item;
}
Java
복사
•
SimpleJdbcInsert가 제공하는 executeAndReturnKey를 사용하면 INSERT SQL를 실행하고 생성된 키 값을 편리하게 조회할 수 있다.
데이터베이스 연동 테스트
•
데이터베이스 연동 테스트의 중요한 원칙
◦
테스트는 다른 테스트와 격리해야 한다.
◦
테스트는 반복해서 실행할 수 있어야 한다.
@SpringBootTest
class ItemRepositoryTest {}
Java
복사
•
@SpringBootTest 가 붙은 테스트는 @SpringBootApplication 를 찾아서 설정으로 사용한다.
//main
spring.profiles.active=local
spring.datasource.url=jdbc:h2:tcp://localhost/~/test
spring.datasource.username=sa
spring.datasource.password=
logging.level.org.springframework.jdbc=debug
//test
spring.profiles.active=test
spring.datasource.url=jdbc:h2:tcp://localhost/~/testcase
spring.datasource.username=sa
spring.datasource.password=
logging.level.org.springframework.jdbc=debug
Java
복사
•
application.properties 도 main 과 test 에서 각각 설정을 할 수 있다.
•
url을 각각 다르게 설정하면 데이터베이스를 분리할 수 있다.
@Autowired
PlatformTransactionManager transactionManager;
TransactionStatus status;
@BeforeEach
void beforeEach() {
status = transactionManager.getTransaction(new DefaultTransactionDefinition());
}
@AfterEach
void afterEach() {
//MemoryItemRepository 의 경우 제한적으로 사용
if (itemRepository instanceof MemoryItemRepository) {
((MemoryItemRepository) itemRepository).clearStore();
}
transactionManager.rollback(status);
}
Java
복사
•
트랜잭션의 롤백을 이용하면 데이터베이스의 오염없이 각 테스트를 격리할 수 있다.
•
PlatformTransactionManager와 TransactionStatus를 사용해 트랜잭션을 시작한다.
•
@BeforeEach와 @AfterEach를 이용해 각 테스트 시작 전 트랜잭션을 시작하고 종료 후 롤백한다
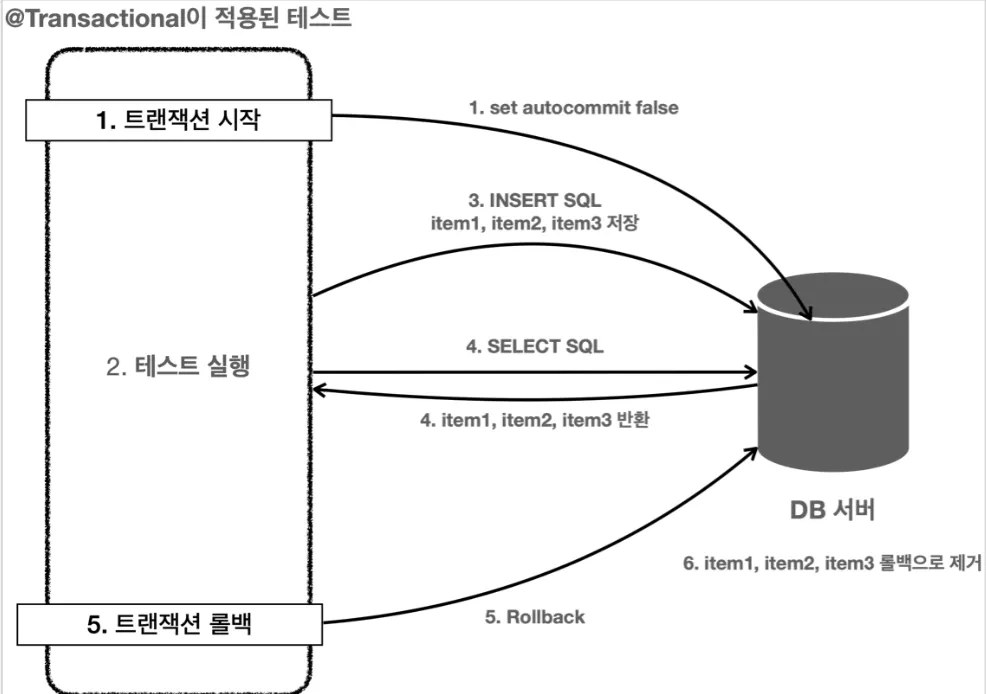
•
원래 @Transactional은 로직이 성공적으로 수행하면 커밋되도록 동작한다.
•
테스트에서는 특별하게 테스트를 트랜잭션 안에서 실행하고 테스트가 끝나면 롤백되도록 동작한다.
•
커밋을 하고 싶다면 @Commit 이나 @Rollback(value = false)를 사용하면 된다.
임베디드 모드 DB
•
H2 데이터베이스와 몇몇 데이터베이스는 JVM 안에서 메모리 모드로 동작하는 임베디드 모드를 제공한다.
//main의 ItemServiceApplication.java
@Bean
@Profile("test")
public DataSource dataSource() {
log.info("메모리 데이터베이스 초기화");
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("org.h2.Driver");
dataSource.setUrl("jdbc:h2:mem:db;DB_CLOSE_DLEAY=-1");
dataSource.setUsername("sa");
dataSource.setPassword("");
return dataSource;
}
//test의 application.properties
spring.profiles.active=test
spring.datasource.url=jdbc:h2:tcp://localhost/~/testcase
spring.datasource.username=sa
spring.datasource.password=
logging.level.org.springframework.jdbc=debug
Java
복사
•
@Profile(”test”)
◦
프로필이 test인 경우에만 빈으로 등록한다.
•
dataSource
◦
jdbc:h2:mem:db : 임베디드 모드로 사용하는 url이다.
◦
DB_CLOSE_DLEAY=-1 : 임베디드 모드의 커넥션 연결이 모두 끊어지면 종료되는걸 방지한다.
//test의 resources의 schema.sql
drop table if exists item CASCADE;
create table item
(
id bigint generated by default as identity,
item_name varchar(10),
price integer,
quantity integer,
primary key (id)
);
Java
복사
•
메모리를 사용하는 임베디드 모드를 사용하려면 사용할 때마다 테이블을 생성해주어야 한다.
•
src/test/resources/schema.sql 의 경로와 이름에 주의하여 추가해주어야 한다.
스프링 부트의 임베디드 모드 DB
•
자 이제 위에서 설정했던걸 다 지워보자.
◦
test/application.properties 의 datasource 설정
◦
main/ItemServiceApplication.java 의 dataSource 빈 설정
•
그럼에도 정상적으로 임베디드 모드가 작동하는걸 확인할 수 있다.
◦
스프링은 데이터베이스 설정 정보가 없으면 임베디드 모드로 접근하는 데이터소스를 만들어서 제공한다.
MyBatis
•
JdbcTemplate보다 더 많은 기능을 제공하는 SQL Mapper이다.
•
SQL을 XML에 편리하게 작성할 수 있고 동적 쿼리를 매우 편리하게 작성할 수 있다.
//build.gradle
implementation 'org.mybatis.spring.boot:mybatis-spring-boot-starter:2.2.2'
//application.properties
mybatis.type-aliases-package=hello.itemservice.domain
mybatis.configuration.map-underscore-to-camel-case=true
logging.level.hello.itemservice.repository.mybatis=trace
mybatis.mapper-locations=classpath:mapper/**/*.xml
Java
복사
•
JdbcTemplate과 다르게 MyBatis는 약간의 설정이 필요하다.
◦
implementation 'org.mybatis.spring.boot:mybatis-spring-boot-starter:2.2.2'
▪
build.gradle에 의존성을 추가해준다.
◦
mybatis.type-aliases-package
▪
xml에서 resultType의 객체 경로를 간편하게 적을 수 있게 해준다.
◦
mybatis.configuration.map-underscore-to-camel-case
▪
item_name → itemName 으로 변경해준다.
◦
logging.level.hello.itemservice.repository.mybatis
▪
로그 레벨 설정
◦
mybatis.mapper-locations=classpath:mapper/**/*.xml
▪
resources 내에서 매퍼 xml 파일의 경로를 지정해줄 수 있다. (현재 resources/mapper)
•
이러한 설정은 test에 있는 application.properties에도 동일하게 적용해주어야 한다.
@Mapper
public interface ItemMapper {
void save(Item item);
void update(@Param("id") Long id, @Param("updateParam")ItemUpdateDto updateParam);
List<Item> findAll(ItemSearchCond itemSearchCond);
Optional<Item> findById(Long id);
}
Java
복사
•
MyBatis의 매핑XML을 호출해주는 매퍼 인터페이스로 @Mapper 어노테이션을 꼭 붙어야 한다.
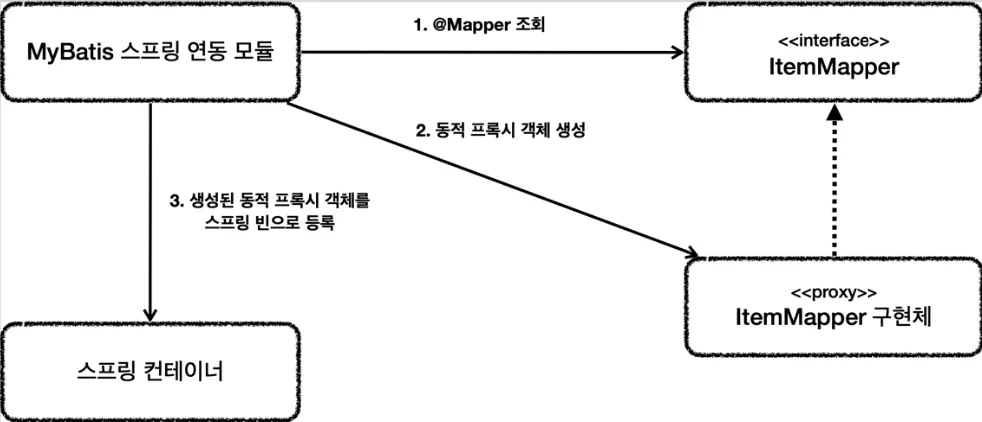
•
애플리케이션 로딩 시 @Mapper 인터페이스를 찾아 동적 프록시 기술로 구현체를 만들어 빈으로 등록한다.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="hello.itemservice.repository.mybatis.ItemMapper">
...
</mapper>
Java
복사
•
매퍼 XML은 위와 같이 작성하고 namespace의 경로는 꼭 매퍼 인터페이스의 경로로 지정해야 한다.
<insert id="save" useGeneratedKeys="true" keyProperty="id">
insert into item (item_name, price, quantity)
values (#{itemName}, #{price}, #{quantity})
</insert>
<update id="update">
update item
set item_name=#{updateParam.itemName},
price=#{updateParam.price},
quantity=#{updateParam.quantity}
where id = #{id}
</update>
<select id="findById" resultType="Item">
select id, item_name, price, quantity
from item
where id = #{id}
</select>
<select id="findAll" resultType="Item">
select id, item_name, price, quantity
from item
<where>
<if test="itemName != null and itemName != ''">
and item_name like concat('%', #{itemName}, '%')
</if>
<if test="maxPrice != null">
and price <= #{maxPrice}
</if>
</where>
</select>
Java
복사
•
매퍼 XML에 SQL은 각 태그를 이용해 작성한다.
◦
id를 통해 인터페이스의 메서드와 매핑하고 resultType을 통해 반환 타입을 지정한다.
◦
파라미터는 #{} 문법을 사용한다. (?를 치환하는 PreparedStatement랑 같다.)
•
useGeneratedKeys는 키 생성 전략이 IDENTITY일 때 사용하고 keyProperty를 통해 키 이름을 지정
•
@Param은 파라미터가 2개 이상일 때부터 붙인다.
•
resultType은 BeanPropertyRowMapper처럼 결과를 객체에 바로 매핑한다.
◦
반환 객체가 하나이면 Item, Optional<Item> 으로 사용하고 하나 이상이면 컬렉션(List)로 사용한다.
•
< , > , & 은 태그에 사용하므로 < , > , & 를 사용한다.
◦
CDATA 구문 문법을 사용해도 된다.
동적 쿼리
•
if
<select id="findActiveBlogWithTitleLike"
resultType="Blog">
SELECT * FROM BLOG
WHERE state = ‘ACTIVE’
<if test="title != null">
AND title like #{title}
</if>
</select>
Java
복사
◦
해당 조건을 추가할지 말지 if 절의 조건에 따라 판단한다.
•
choose, when, otherwise
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
<choose>
<when test="title != null">
AND title like #{title}
</when>
<when test="author != null and author.name != null">
AND author_name like #{author.name}
</when>
<otherwise>
AND featured = 1
</otherwise>
</choose>
</select>
Java
복사
◦
자바의 switch 구문과 유사하다.
•
where, set
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>
Java
복사
◦
<where> 태그는 문장이 없으면 where을 추가하지 않는다. (and가 먼저 시작되면 and를 지운다.)
•
trim
<trim prefix="WHERE" prefixOverrides="AND |OR ">
...
</trim>
Java
복사
◦
where와 같은 기능을 수행한다.
•
foreach
<select id="selectPostIn" resultType="domain.blog.Post">
SELECT *
FROM POST P
<where>
<foreach item="item" index="index" collection="list"
open="ID in (" separator="," close=")" nullable="true">
#{item}
</foreach>
</where>
</select>
Java
복사
◦
컬렉션을 반복 처리할 때 사용한다. where in (1,2,3,4,5,6)과 같은 문장을 쉽게 완성할 수 있다.
◦
파라미터로 List를 전달해야 한다.
•
sql
<sql id="userColumns"> ${alias}.id,${alias}.username,${alias}.password </sql>
<select id="selectUsers" resultType="map">
select
<include refid="userColumns"><property name="alias" value="t1"/></include>,
<include refid="userColumns"><property name="alias" value="t2"/></include>
from some_table t1
cross join some_table t2
</select>
Java
복사
◦
<sql>을 미리 작성해두고 <include>를 통해 SQL조각을 가져다 쓸 수 있다.
◦
프로퍼티 값을 전달할 수 있고 해당 값은 내부에서 사용할 수 있다.
•
resultMap
<resultMap id="userResultMap" type="User">
<id property="id" column="user_id" />
<result property="username" column="username"/>
<result property="password" column="password"/>
</resultMap>
<select id="selectUsers" resultMap="userResultMap">
select user_id, user_name, hashed_password
from some_table
where id = #{id}
</select>
Java
복사
◦
resultMap을 만들어 놓으면 테이블과 객체 프로퍼티의 이름이 일치하지 않을 때 별칭을 사용하지 않아도 된다.
어노테이션
@Select("select id, item_name, price, quantity from item where id=#{id}")
Optional<Item> findById(Long id);
Java
복사
•
@Insert, @Update, @Delete, @Select 로 간단한 CRUD를 XML 없이 사용할 수 있다.
•
동적 SQL은 해결되지 않는다.
ORM
•
객체는 객체대로, 관계형 데이터베이스는 관계형 데이터베이스대로 설계할 수 있게 해주는 기술이다.
•
ORM 프레임워크가 중간에서 대신 매핑해준다.
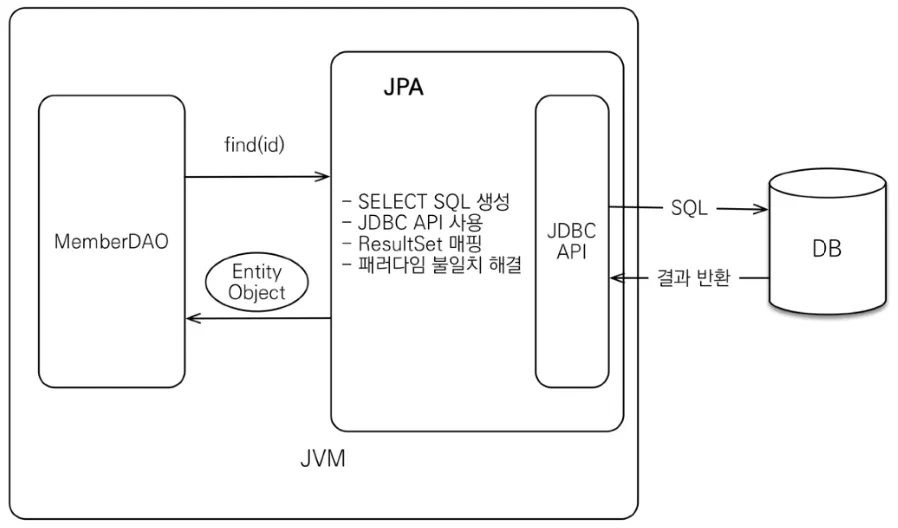
JPA
•
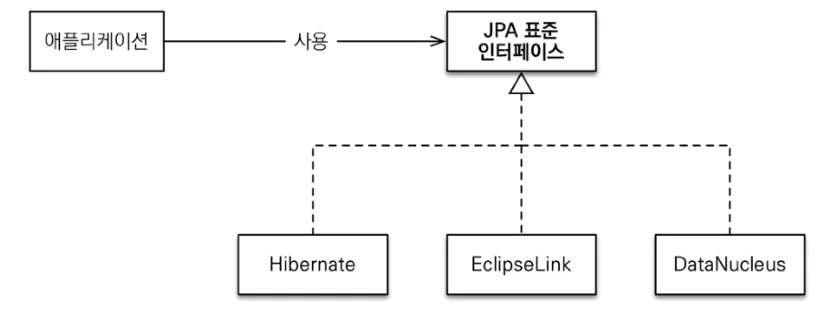
자바 진영의 ORM 기술 표준이다.
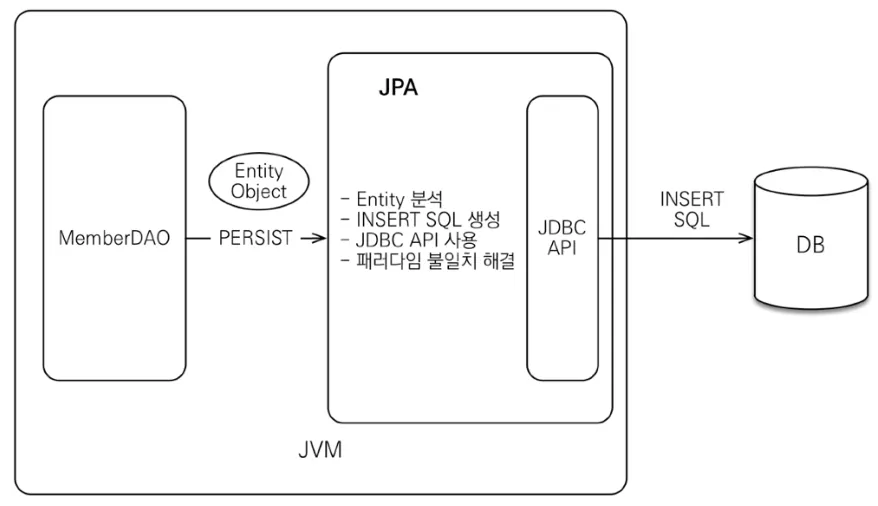
•
JPA는 인터페이스의 모음으로 구현체로 하이버네이트 등이 있다.
•
CRUD
◦
저장 : jpa.persist(member)
◦
조회 : Member member = jpa.find(memberId)
◦
수정 : member.setName(”변경할 이름”)
◦
삭제 : jpa.remove(member)
•
장점
◦
SQL 중심적인 개발에서 객체 중심으로 개발
◦
생산성, 유지보수, 성능
◦
표준, 패러다임 불일치 해결
◦
데이터 접근 추상화와 벤더 독립성
•
특징
◦
1차 캐시와 동일성(동일한 트랜잭션에서 조회한 엔티티는 같음) 보장
◦
트랜잭션을 지원하는 쓰기 지연
◦
지연 로딩
설정
//build.gradle
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
//application.properties
logging.level.org.hibernate.SQL=debug
logging.level.org.hibernate.type.descriptor.sql.BasicBinder=trace
Java
복사
•
'org.springframework.boot:spring-boot-starter-data-jpa' 의존성 추가
◦
spring-boot-starter-jdbc 라이브러리를 포함한다.
◦
hibernate-cord 라이브러리 추가 (JPA 구현체인 하이버네이트 라이브러리)
◦
jakarta.persistence-api 라이브러리 추가 (JPA 인터페이스)
◦
spring-data-jpa 라이브러리 추가 (스프링 데이터 JPA 라이브러리)
•
logging.level.org.hibernate.SQL=debug
◦
하이버네이트가 생성하고 실행하는 SQL을 확인할 수 있다.
•
logging.level.org.hibernate.type.descriptor.sql.BasicBinder=trace
◦
SQL에 바인딩 되는 파라미터를 확인할 수 있다.
Entity 매핑
@Data
@Entity
@Table(name = "item")
public class Item {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "item_name", length = 10)
private String itemName;
private Integer price;
private Integer quantity;
public Item() {
}
public Item(String itemName, Integer price, Integer quantity) {
this.itemName = itemName;
this.price = price;
this.quantity = quantity;
}
}
Java
복사
•
@Entity를 붙여 JPA가 객체로 인식할 수 있게 한다.
•
@Table(name = “DB테이블 이름”) 으로 매핑할 테이블을 지정한다.
•
@Id 로 테이블의 PK로 매핑할 프로퍼티를 지정한다.
•
@GeneratedValue(strategy = GenerationType.IDENTITY) 로 키 생성 전략을 지정한다.
•
@Column(name = “컬럼이름", length = 10) 로 컬럼과 프로퍼티를 매핑한다.
◦
length는 DDL(create table)을 할 때 사용된다. → varchar 10
◦
스프링 부트와 통합하여 사용하면 snake_case to camelCase를 자동으로 해주므로 생략 가능하다.
•
JPA는 public 또는 protected 의 기본 생성자가 필수이다!
Repository
@Slf4j
@Repository
@Transactional
public class JpaItemRepository implements ItemRepository {
private final EntityManager em;
public JpaItemRepository(EntityManager em) {
this.em = em;
}
}
Java
복사
•
JPA를 사용하기 위해선 EntityManage 를 주입 받아야 한다.
◦
내부에 데이터소스를 가지고 있고 데이터베이스에 접근할 수 있다.
◦
EntityManager는 사실 EntityManagerFactory, JpaTransactionManager 를 만든 후 생성해야 하는데 스프링 부트가 해준다.
•
JPA에서 조회를 제외한 모든 데이터 변경은 트랜잭션 안에서 이루어져야하므로 @Transactional을 붙인다.
JPA의 CRUD
•
save
@Override
public Item save(Item item) {
em.persist(item);
return item;
}
Java
복사
◦
키 생성 전략이 IDENTITY인 경우 INSERT SQL 실행 후 생성된 키를 넣어준다.
•
update
@Override
public void update(Long itemId, ItemUpdateDto updateParam) {
Item item = em.find(Item.class, itemId);
item.setItemName(updateParam.getItemName());
item.setPrice(updateParam.getPrice());
item.setQuantity(updateParam.getQuantity());
}
Java
복사
◦
트랜잭션이 커밋되면 영속성 컨텍스트 내의 스냅샷 객체와 비교해서 변경된 객체를 찾는다.
◦
변경된 경우에만 UPDATE SQL을 실행한다.
•
findAll
@Override
public List<Item> findAll(ItemSearchCond cond) {
String jpql = "select i from Item i";
List<Item> result = em.createQuery(jpql, Item.class).getResultList();
return result;
}
Java
복사
◦
SQL이 테이블을 대상으로 한다면 JPQL은 엔티티 객체를 대상으로 SQL을 실행한다.
◦
엔티티 객체의 매핑 정보와 파라미터를 활용해 SQL을 만든다.
JPA의 예외처리
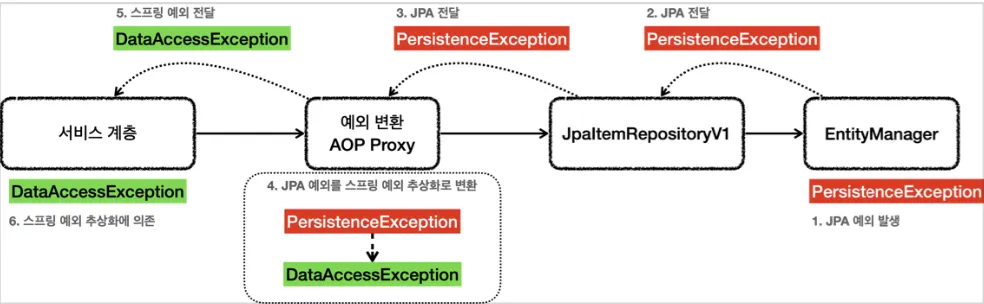
•
EntityManager는 순수한 JPA 기술로 스프링과 관련이 없어 JPA 관련 예외만을 발생시킨다.
•
@Repository를 통해 JPA 예외를 스프링 예외 추상화로 변환할 수 있다.
◦
@Repository 클래스는 컴포넌트 스캔 대상이 되고 예외 변환 AOP 대상이 된다.
◦
스프링과 JPA를 함께 사용하는 경우 스프링은 PersistenceExceptionTranslator를 등록한다.
•
스프링 부트가 자동으로 등록하는 PersistenceExceptionTranslatorPostProcessor에서 @Repository를 AOP 프록시로 만드는 어드바이저가 등록된다.
•
EntityManagerFactoryUtils.convertJpaAccessExceptionIfPossible()에서 JPA 예외를 변환한다.
스프링 데이터
•
여러 종류의 데이터베이스들의 공통적인 부분을 통합해 한 단계 더 추상화 시켜주는 기술이다.
◦
CRUD + 쿼리
◦
동일한 인터페이스
◦
페이징 처리
◦
메서드 이름으로 쿼리 생성
◦
스프링 MVC에서 id값만 넘겨도 도메인 클래스로 바인딩
스프링 데이터 JPA
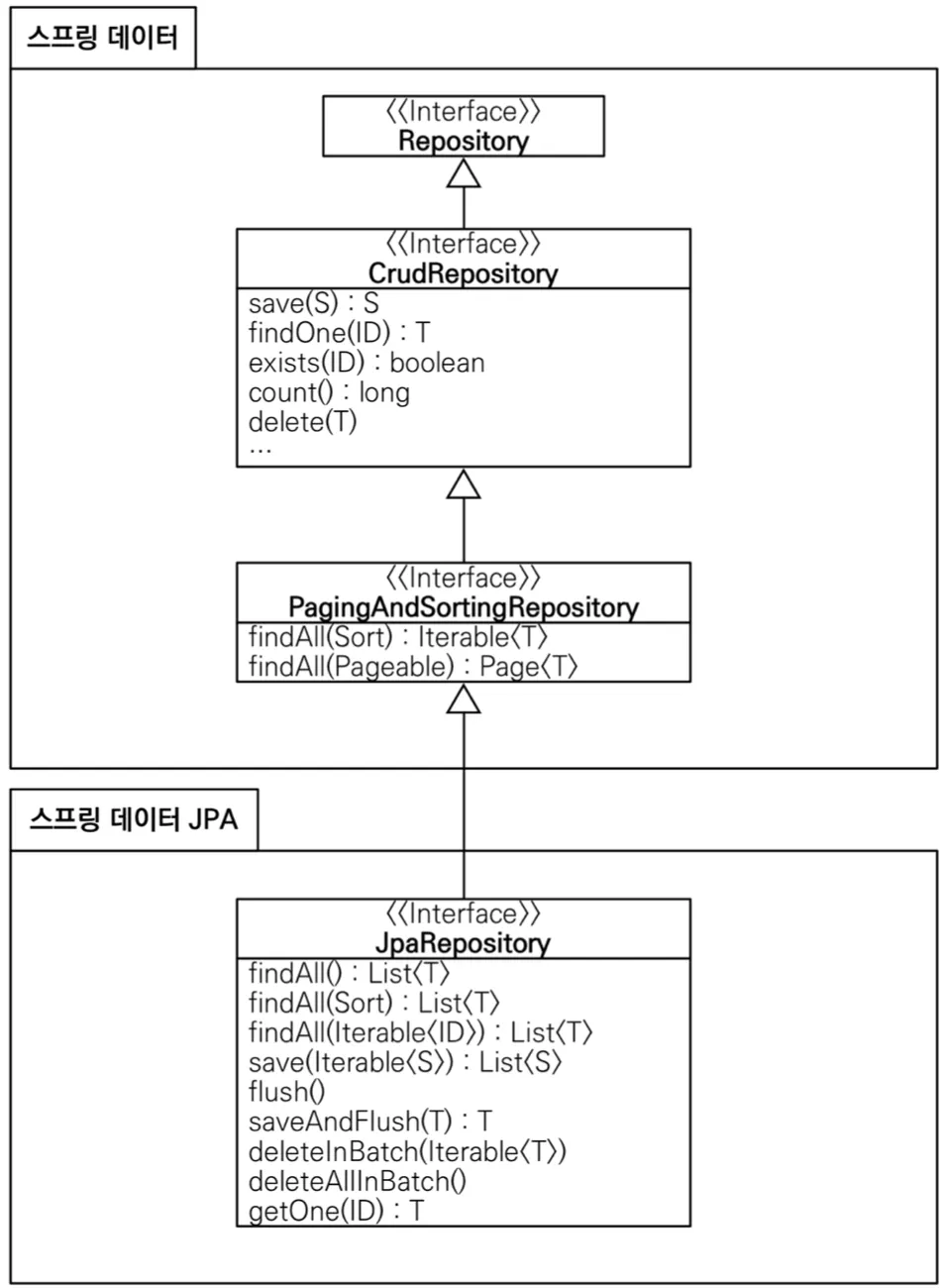
•
스프링 데이터를 사용하며 JPA를 좀 더 편리하게 사용할 수 있도록 도와주는 라이브러리이다.
//build.gradle
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
ext["hibernate.version"] = "5.6.5.Final" //버전 변경
Java
복사
•
build.gradle에 의존성을 추가해 사용할 수 있다.
•
스프링이 자동으로 잡아주는 버전에서 변경하고 싶다면 ext[”hibernate.version”] 을 사용한다.
public interface SpringDataJpaItemRepository extends JpaRepository<Item, Long> {
}
Java
복사
•
JpaRepository 인터페이스를 상속 받은 인터페이스를 만들어 제네릭으로 <엔티티, PK>를 주면 된다.
•
아무런 내용을 적지 않아도 상속 받았기 때문에 기본 CRUD 기능을 모두 사용할 수 있다.
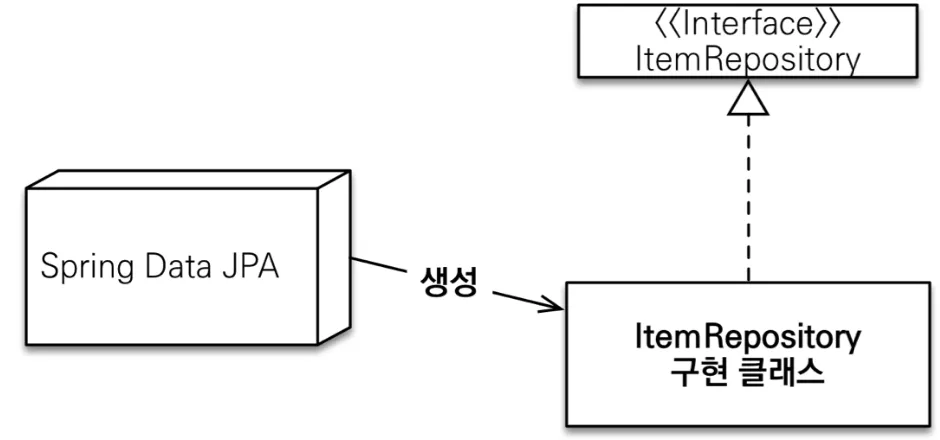
•
JpaRepository를 상속 받으면 스프링 데이터 JPA가 동적 프록시 기술로 구현 클래스를 만들고 인스턴스를 만들어 스프링 빈으로 등록한다.
•
개발자는 구현 클래스 없이 인터페이스만 만들면 CRUD 기능을 사용할 수 있다.
쿼리 메서드
•
인터페이스에 메서드만 적어두면 메서드 이름을 분석해 쿼리를 자동으로 만들고 실행해주는 기능이다.
//순수 JPA Repository
public List<Member> findByUsernameAndAgeGreaterThan(String username, int age) {
return em.createQuery("select m from Member m where m.username = :username and m.age > :age")
.setParameter("username", username)
.setParameter("age", age)
.getResultList();
}
//스프링 데이터 JPA
public interface MemberRepository extends JpaRepository<Member, Long> {
List<Member> findByUsernameAndAgeGreaterThan(String username, int age);
}
Java
복사
•
순수 JPA Repository는 직접 JPQL을 작성하고 파라미터를 직접 바인딩 해야 한다.
•
스프링 데이터 JPA는 메서드 이름을 분석해 JPQL을 만들고 실행한다. (JPA가 SQL로 변역해서 실행)
◦
조회 : find..By , read..By , query..By , get..By
◦
삭제 : delete..By , remove..By (반환타입 long)
◦
COUNT : count..By (반환타입 long)
◦
EXISTS : exists..By (반환타입 boolean)
◦
DISTINCT : findDistinct , findMemberDistinctBy
◦
LIMIT : findFirst3 , findFirst , findTop , findTop3
//이름이 너무 길어 복잡한 경우
List<Item> findByItemNameLikeAndPriceLessThanEqual(String itemName, Integer price);
//JPQL을 직접 실행
@Query("select i from Item i where i.itemName like :itemName and i.price <= :price")
List<Item> findItems(@Param("itemName") String itemName, @Param("price") Integer price);
Java
복사
•
쿼리 메서드의 이름이 복잡해지는 경우 직접 JPQL을 사용할 수 있다.
•
@Query 로 JPQL을 작성한 후 파라미터를 매핑해준다. (파라미터 2개 이상이면 @Param 사용)
•
@Modifying 를 추가로 붙여 UPDATE SQL도 실행 할 수 있다.
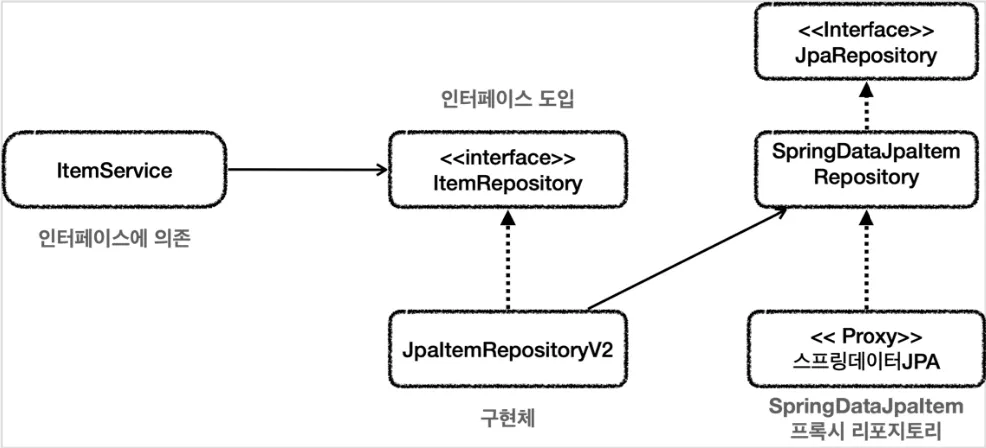
•
기존에 ItemService는 ItemRepository를 의존하고 있기 때문에 SpringDataJpaItemRepository를 사용할 수 없다.
→ ItemRepository의 구현체를 만들어 SpringDataJpaItemRepository를 주입 받는다.

•
ItemRepository의 구현체는 SpringDataJpaItemRepository라는 인터페이스를 의존하게 된다.
하지만 실제로 구현체는 해당 인터페이스의 프록시 구현체이다.
→ 위는 클래스 일 때의 의존관계고 런타임 일 땐 프록시 구현체를 사용하게 된다.
QueryDSL
•
쿼리를 JAVA로 type-safe하게 개발할 수 있게 지원하는 프레임워크이다.
◦
기존의 쿼리를 사용하면 type-check가 불가능하고 실행하기 전까진 작동여부를 확인할 수 없었다.
◦
QueryDSL 사용 시 컴파일에서 에러 체크가 가능하고 code-assistant를 사용할 수 있다.
•
JPQL, Criteria API, MetaModel Criteria API 에서의 동적 쿼리의 어려움을 해결해준다.
◦
쿼리 + 도메인 + 특화 + 언어로 쿼리에 특화된 프로그래밍 언어 (단순, 간결, 유창)
•
@Entity 와 같은 APT(Annotation Processing Tool) 를 사용해 쿼리를 생성해준다.
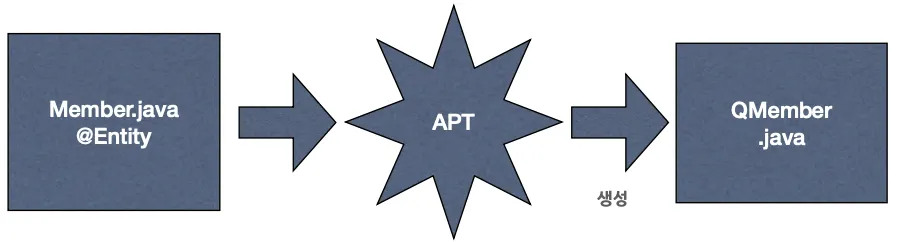
◦
QueryDSL은 JPQL를 생성하고 JPA에 의해 SQL로 변환된다.
//build.gradle
implementation 'com.querydsl:querydsl-jpa'
annotationProcessor "com.querydsl:querydsl-apt:${dependencyManagement.importedProperties['querydsl.version']}:jpa"
annotationProcessor "jakarta.annotation:jakarta.annotation-api"
annotationProcessor "jakarta.persistence:jakarta.persistence-api"
//build.gradle (자동 생성된 Q클래스 gradle clean으로 제거)
clean {
delete file('src/main/generated')
}
Java
복사
•
build.gradle에 다음과 같은 설정을 해주어야 한다.
•
컴파일 시 생성되는 Q타입은 깃 이그노어 하는 것이 좋다.
@Repository
@Transactional
public class JpaItemRepositoryV3 implements ItemRepository {
private final EntityManager em;
private final JPAQueryFactory query;
public JpaItemRepositoryV3(EntityManager em) {
this.em = em;
this.query = new JPAQueryFactory(em);
}
}
Java
복사
•
QueryDSL을 사용하기 위해선 JPAQueryFactory가 필요하고 JPQL도 생성해야 하기 때문에 EntityManager도 필요하다.
public List<Item> findAllOld(ItemSearchCond cond) {
String itemName = cond.getItemName();
Integer maxPrice = cond.getMaxPrice();
QItem item = QItem.item;
BooleanBuilder builder = new BooleanBuilder();
if(StringUtils.hasText(itemName)) {
builder.and(item.itemName.like("%" + itemName + "%"));
}
if(maxPrice != null) {
builder.and(item.price.loe(maxPrice));
}
List<Item> result = query
.select(item)
.from(item)
.where(builder)
.fetch();
return result;
}
@Override
public List<Item> findAll(ItemSearchCond cond) {
String itemName = cond.getItemName();
Integer maxPrice = cond.getMaxPrice();
return query
.select(item)
.from(item)
.where(likeItemName(itemName), maxPrice(maxPrice))
.fetch();
}
private BooleanExpression maxPrice(Integer maxPrice) {
if(maxPrice != null) {
return item.price.loe(maxPrice);
}
return null;
}
private BooleanExpression likeItemName(String itemName) {
if(StringUtils.hasText(itemName)) {
return item.itemName.like("%" + itemName + "%");
}
return null;
}
Java
복사
•
QueryDSL를 사용하면 쿼리와 비슷하게 자바 코드로 작성할 수 있다.
◦
Query (select, from, where, join, …)
◦
Path (QMember, QMember.name, …)
◦
Expression (name.eq, name,gt, …)
•
BooleanBuilder를 사용해 WHERE 조건을 채울 수 있다.
◦
BooleanExpression을 사용하면 where()에서 콤마로 AND를 사용할 수 있다.
•
fetch()를 사용하면 목록 조회, fetchOne()을 사용하면 단건 조회가 가능하다.
트레이드 오프
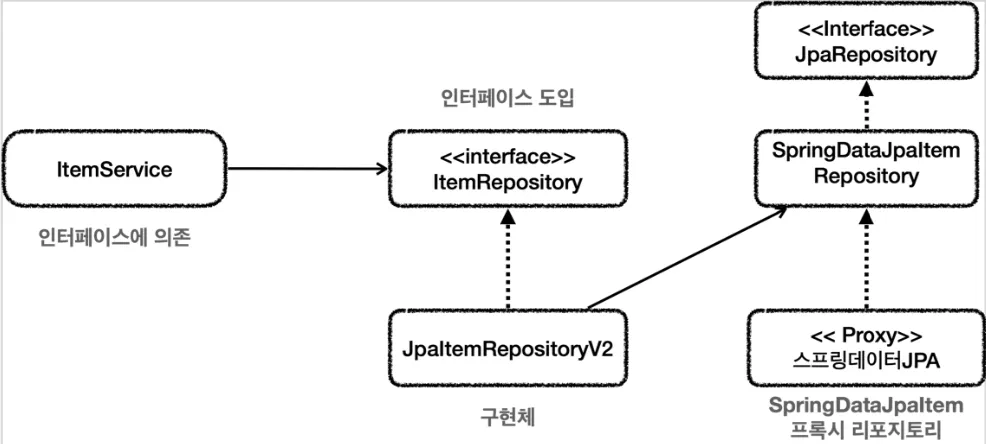
•
의존 관계를 잘 보면 JpaItemRepositoryV2가 어댑터 역할을 해주기 때문에 ItemService 는 코드 변경 없이 ItemRepository 인터페이스를 의존할 수 있다.
◦
DI, OCP 원칙을 지키기 위해 어댑터가 들어가면서 전체 구조가 너무 복잡해지고 클래스도 많아진다.
◦
개발자는 어댑터도 만들고 실제 코드까지 만들어야 하고 유지보수 해야 하는 불편함이 생긴다.
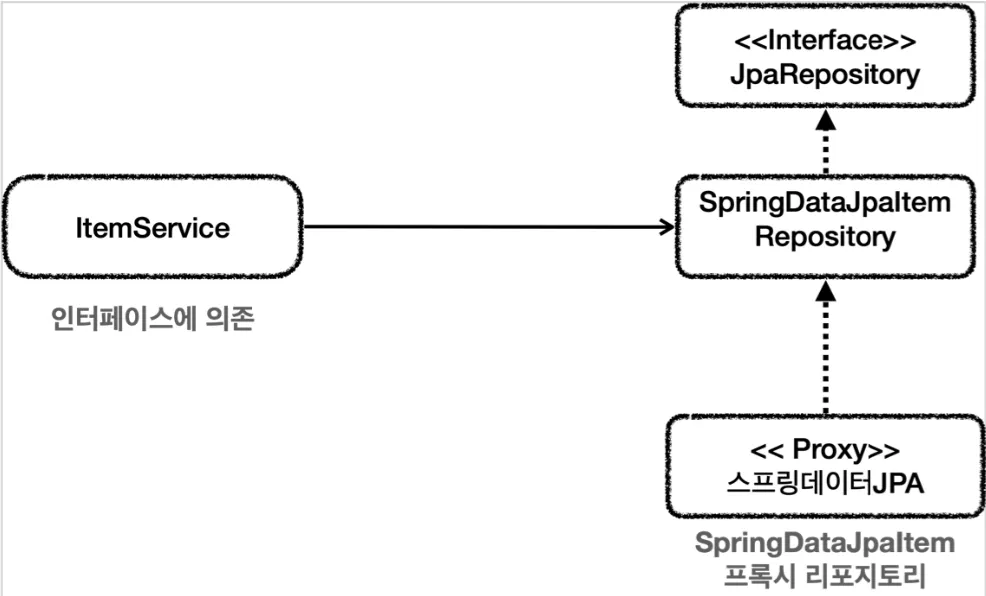
•
DI, OCP 원칙을 포기하고 ItemService 코드를 일부 고쳐서 SpringDataJpaItemRepository를 사용하는 방법이다.
◦
중간에 어댑터가 제거되며 구조가 단순해진다.
구조의 안정성 VS 단순한 구조와 개발의 편리성
•
위와 같은 경우 발생하는 트레이드 오프이다.
•
개발을 할 땐 항상 자원이 무한하지 않고 어설픈 추상화는 독이 된다.
•
결국 정답은 없다. 프로젝트의 현재 상황에 맞는 더 적절한 선택지를 선택하는 개발자가 좋은 개발자이다.
실용적인 구조
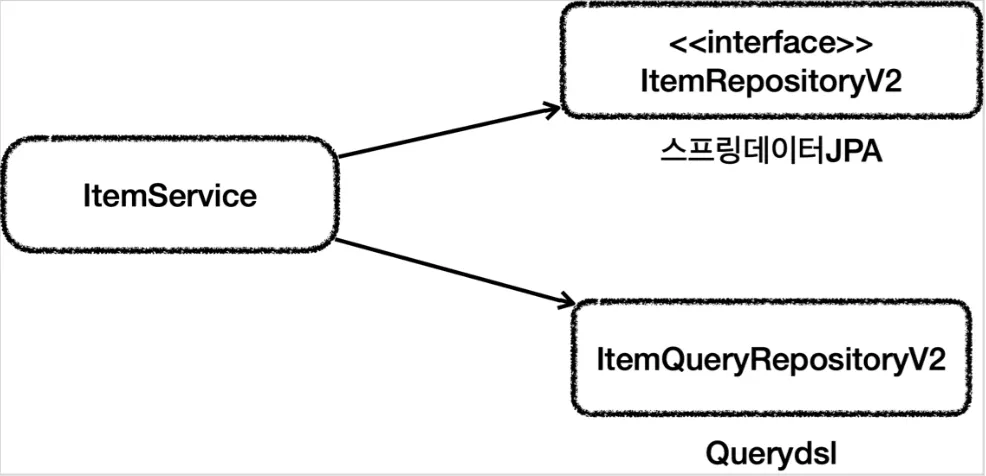
•
스프링 데이터 JPA를 담당하는 레포지토리와 QueryDSL을 담당하는 레포지토리를 함께 의존한다.
◦
CRUD와 단순 조회는 스프링 데이터 JPA가 담당
◦
복잡한 조회 쿼리는 QueryDSL이 담당
public interface ItemRepositoryV2 extends JpaRepository<Item, Long> {
}
Java
복사
@Repository
public class ItemQueryRepositoryV2 {
private final JPAQueryFactory query;
public ItemQueryRepositoryV2(EntityManager em) {
this.query = new JPAQueryFactory(em);
}
public List<Item> findAll(ItemSearchCond cond) {
return query.select(item)
.from(item)
.where(likeItemName(cond.getItemName()), maxPrice(cond.getMaxPrice()))
.fetch();
}
private BooleanExpression maxPrice(Integer maxPrice) {
if(maxPrice != null) {
return item.price.loe(maxPrice);
}
return null;
}
private BooleanExpression likeItemName(String itemName) {
if(StringUtils.hasText(itemName)) {
return item.itemName.like("%" + itemName + "%");
}
return null;
}
}
Java
복사
@Service
@RequiredArgsConstructor
@Transactional
public class ItemServiceV2 implements ItemService {
private final ItemRepositoryV2 itemRepositoryV2;
private final ItemQueryRepositoryV2 itemQueryRepositoryV2;
@Override
public Item save(Item item) {
return itemRepositoryV2.save(item);
}
@Override
public void update(Long itemId, ItemUpdateDto updateParam) {
Item findItem = itemRepositoryV2.findById(itemId).orElseThrow();
findItem.setItemName(updateParam.getItemName());
findItem.setPrice(updateParam.getPrice());
findItem.setQuantity(updateParam.getQuantity());
}
@Override
public Optional<Item> findById(Long id) {
return itemRepositoryV2.findById(id);
}
@Override
public List<Item> findItems(ItemSearchCond cond) {
return itemQueryRepositoryV2.findAll(cond);
}
}
Java
복사
•
둘 다 DI 받은 후 쿼리마다 필요한 레포지토리를 사용한다.
@Configuration
@RequiredArgsConstructor
public class V2Config {
private final EntityManager em;
private final ItemRepositoryV2 itemRepositoryV2;
@Bean
public ItemService itemService() {
return new ItemServiceV2(itemRepositoryV2, itemQueryRepositoryV2());
}
@Bean
public ItemQueryRepositoryV2 itemQueryRepositoryV2() {
return new ItemQueryRepositoryV2(em);
}
//테스트용
@Bean
public ItemRepository itemRepository() {
return new JpaItemRepositoryV3(em);
}
}
Java
복사
•
Config에서 수동으로 빈 등록할 때 주의해야 한다.
다양한 데이터베이스 접근 기술 조합
•
비즈니스 상황과 현재 프로젝트 구성원의 역량에 따라 결정하는 것이 적합하다.
◦
JPA, 스프링 데이터 JPA, QueryDSL을 기본으로 사용하고 해결이 안되는 문제는 MyBatis나 JdbcTemplate를 사용하는 것이 좋다.
•
트랜잭션 매니저를 고를 땐 JpaTransactionManager를 선택한다.
◦
SQL Mapper는 DataSourceTransactionManager를 사용한다.
◦
ORM은 JpaTransactionManager를 사용한다.
◦
JpaTransactionManager는 DataSourceTransactionManager 기능을 대부분 제공한다.
•
JPA와 JdbcTemplate를 함께 사용하는 경우 플러시 타이밍에 주의하라
◦
JPA는 영속성 컨텍스트에 의해 관리되며 커밋 시점에 SQL이 한꺼번에 실행된다.
◦
JdbcTemplate는 바로바로 SQL을 실행시킨다.
◦
JPA의 플러시 기능을 사용하면 커밋 전에도 SQL을 즉시 실행시킬 수 있다.
스프링 트랜잭션
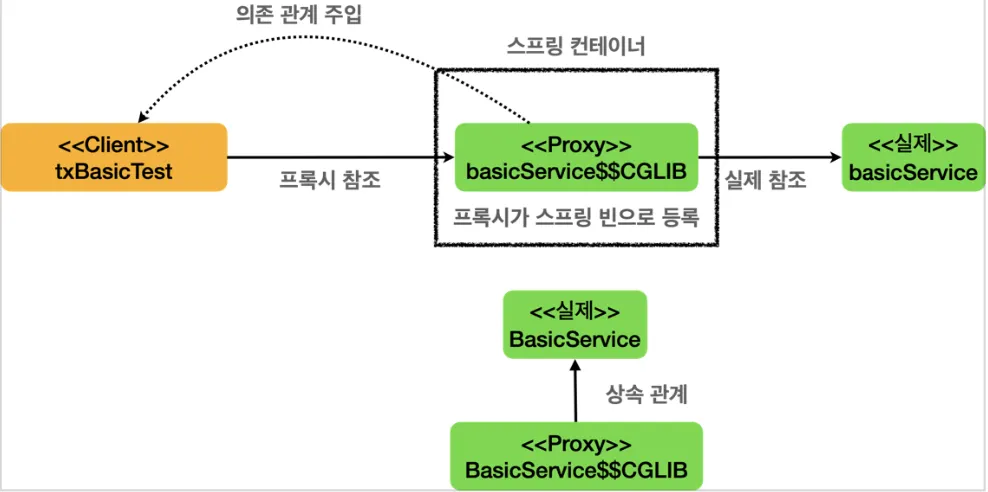
•
@Transactional를 사용하면 트랜잭션 AOP 프록시를 통해 서비스와 트랜잭션을 분리할 수 있다.
◦
실제 객체 대신 프록시 객체가 스프링 빈으로 등록되고 주입된다. (~~$$CGLIB)
◦
AopUtils.isAopProxy() 를 통해 프록시인지 확인할 수 있다.
◦
프록시는 기존 서비스 객체를 상속해서 만들어지기 때문에 다형성을 활용한다.
•
TransactionSynchronizationManager.isActualTransactionActive()
◦
현재 스레드에 트랜잭션이 적용되어 있는지 확인할 수 있는 기능이다.
•
TransactionSynchronizationManager.isCurrentTransactionReadOnly()
◦
현재 트랜잭션에 적용된 readOnly 옵션의 값을 반환한다.
•
@Transactional의 우선순위는 구체적이고 자세한 것이 높은 우선순위를 가진다.
1.
클래스의 메서드
2.
클래스
3.
인터페이스의 메서드
4.
인터페이스
(인터페이스에 사용하면 AOP가 적용하지 않는 경우가 있으므로 가급적 구체적으로 사용한다.)
•
트랜잭션 AOP는 public 메서드에서만 적용된다.
트랜잭션 AOP 주의사항
•
요청을 하면 프록시 객체가 먼저 받아 트랜잭션을 처리하고 실제 객체를 호출한다.
따라서 트랜잭션을 적용하려면 항상 프록시를 통해서 대상 객체를 호출해야 한다.
@Slf4j
@SpringBootTest
public class InternalCallV1Test {
@Autowired CallService callService;
@Test
void internalCall() {
callService.internal();
}
@Test
void externalCall() {
callService.external();
}
@Slf4j
@RequiredArgsConstructor
static class CallService {
public void external() {
log.info("call external");
printTxInfo();
internal();
}
@Transactional
public void internal() {
log.info("call internal");
printTxInfo();
}
private void printTxInfo() {
boolean txActive = TransactionSynchronizationManager.isActualTransactionActive();
log.info("tx active={}", txActive);
}
}
Java
복사
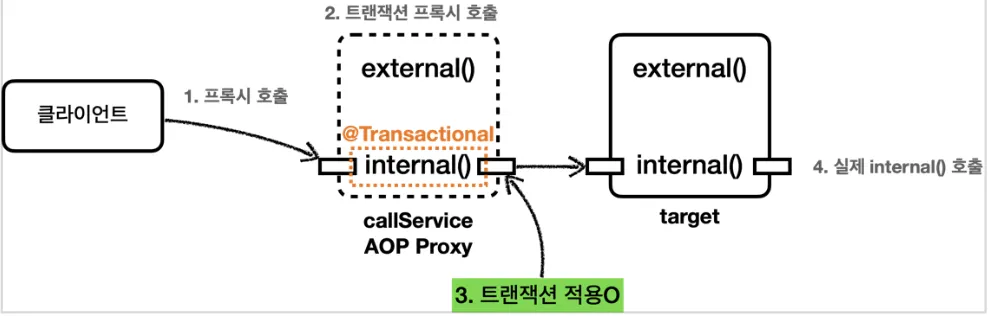
•
정상적으로 트랜잭션이 실행된다.
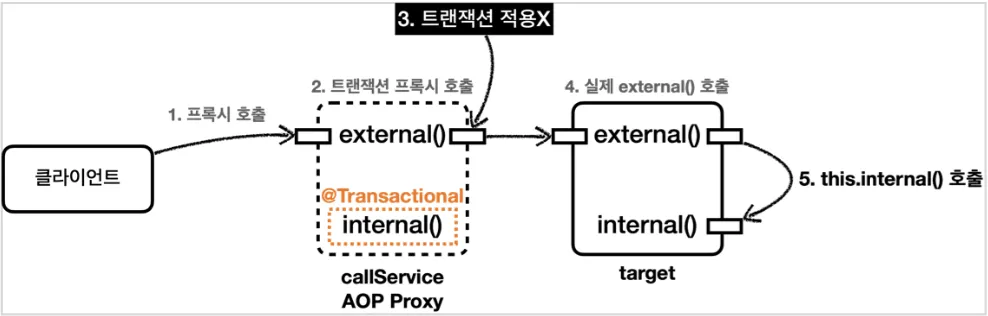
•
external()이 internal()이 호출했음에도 트랜잭션이 적용되지 않는다.
◦
이 때 internal()은 생략된 this.internal()이라 실제 external()에서 호출했으므로 트랜잭션이 없다.
프록시 방식 AOP의 한계
•
메서드 내부 호출에 트랜잭션 프록시가 적용되지 않는 문제는 프록시 방식의 AOP 한계이다.
이를 해결하기 위해선 내부 호출하는 메서드를 별도의 클래스로 분리해야 한다.
@Slf4j
@RequiredArgsConstructor
static class CallService {
private final InternalService internalService;
public void external() {
log.info("call external");
printTxInfo();
internalService.internal();
}
@Transactional
public void internal() {
log.info("call internal");
printTxInfo();
}
private void printTxInfo() {
boolean txActive = TransactionSynchronizationManager.isActualTransactionActive();
log.info("tx active={}", txActive);
}
}
static class InternalService {
@Transactional
public void internal() {
log.info("call internal");
printTxInfo();
}
private void printTxInfo() {
boolean txActive = TransactionSynchronizationManager.isActualTransactionActive();
log.info("tx active={}", txActive);
}
}
Java
복사
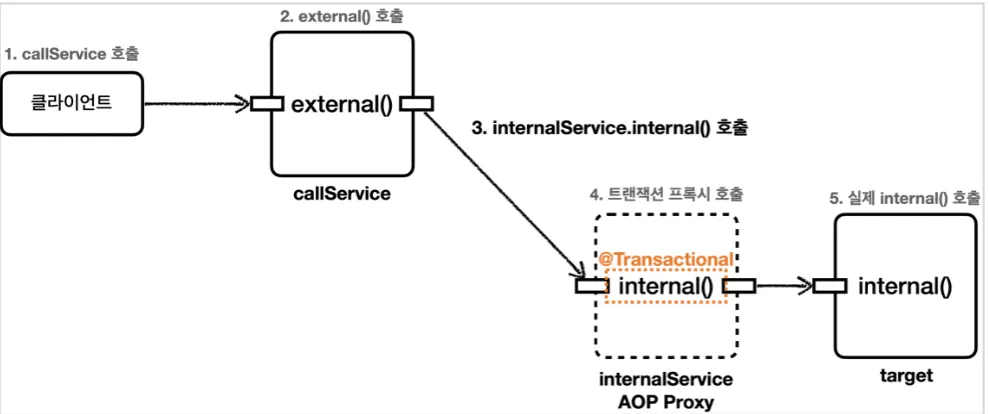
•
InternalService 클래스로 분리하여 this.internal() 대신 internalService.internal()로 변경하였다.
→ 트랜잭션이 정상적으로 적용된다.
@Autowired Hello hello;
@Test
void go() {
}
@Slf4j
static class Hello {
@PostConstruct
@Transactional
public void initV1() {
boolean isActive = TransactionSynchronizationManager.isActualTransactionActive();
log.info("Hello init @PostConstruct tx active={}", isActive);
}
@EventListener(ApplicationReadyEvent.class)
@Transactional
public void initV2() {
boolean isActive = TransactionSynchronizationManager.isActualTransactionActive();
log.info("Hello init ApplicationReadyEvent tx active={}", isActive);
}
}
Java
복사
•
@PostConstruct와 @Transactional을 함께 사용하면 트랜잭션이 적용되지 않는다.
→ 초기화 코드가 먼저 호출되고 그 다음에 트랜잭션 AOP가 적용되기 때문이다.
•
@EventListner(value = ApplicationReadyEvent.class)
→ 트랜잭션 AOP를 포함한 스프링 컨테이너 생성 등 모든 초기 작업이 끝난 후 호출된다.
트랜잭션 옵션
•
@Transactional(value = “”)
public class TxService {
@Transactional("memberTxManager")
public void member() {...}
@Transactional("orderTxManager")
public void order() {...}
}
Java
복사
◦
트랜잭션 매니저를 구분하기 위해 사용하고 생략하면 기본으로 등록된 트랜잭션 매니저를 사용한다.
◦
속성이 하나인 경우 value를 생략하고 값을 바로 넣을 수 있다.
•
@Transactional(rollbackFor = ~~.class)
@Transactional(rollbackFor = MyException.class)
public void rollbackFor() throws MyException {
log.info("call checkedException");
throw new MyException();
}
Java
복사
◦
트랜잭션 롤백 기본 정책
▪
언체크 예외 (RuntimeException, Error) 가 발생하면 롤백
▪
체크 예외 (Exception) 이 발생하면 커밋
◦
rollbackFor 을 지정할 경우 해당 예외가 발생하면 체크 예외여도 롤백한다.
◦
noRollbackFor 은 rollbackFor의 반대이다.
•
@Transactional(isolation = )
◦
DEFAULT : 데이터베이스에서 설정한 격리 수준을 따른다.
◦
READ_UNCOMMITED : 커밋되지 않은 읽기
◦
READ_COMMITED : 커밋된 읽기
◦
REPEATABLE_READ : 반복 가능한 읽기
◦
SERIALIZABLE : 직렬화 가능
•
@Transactional(timeout = )
◦
트랜잭션 수행 시간에 대한 타임아웃을 초 단위로 지정한다.
•
@Transactional(label = “”)
◦
트랜잭션 어노테이션의 라벨 값을 읽어 사용하고 싶을 때 지정한다.
•
@Transactional(readOnly = false)
◦
프레임워크
▪
JdbcTemplate는 읽기 전용 트랜잭션 안에서 변경 기능을 실행하면 예외를 던진다.
▪
JPA는 읽기 전용 트랜잭션의 경우 커밋 시점에 플러시를 호출하지 않는다.
◦
JDBC 드라이버
▪
읽기 전용 트랜잭션에서 변경 쿼리가 발생하면 예외를 던진다.
▪
읽기(슬레이브), 쓰기(마스터) 데이터베이스를 구분해서 요청한다.
◦
데이터베이스
▪
읽기 전용 트랜잭션의 경우 읽기만 하면 되므로 내부에서 성능 최적화가 발생한다.
트랜잭션 전파
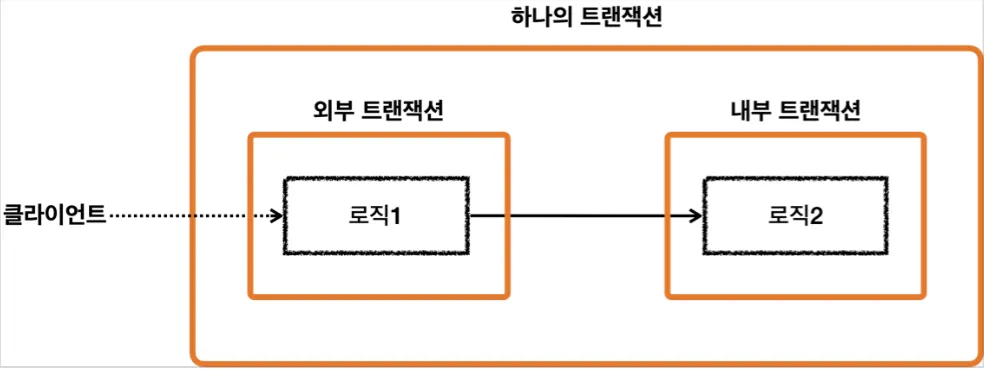
•
트랜잭션이 이미 수행 중인데 추가로 트랜잭션을 수행하면 스프링은 하나의 트랜잭션을 만들어준다.
•
처음 시작된 트랜잭션은 외부 트랜잭션 이후 시작된 트랜잭션은 내부 트랜잭션이다.
•
물리 트랜잭션은 실제 커넥션을 통해 트랜잭션을 시작하고 커밋, 롤백하는 단위이다.
•
논리 트랜잭션은 트랜잭션 매니저를 통해 트랜잭션을 사용하는 단위이다.
@Test
void inner_commit() {
log.info("외부 트랜잭션 시작");
TransactionStatus outer = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("outer.isNewTransaction={}", outer.isNewTransaction()); //true
log.info("내부 트랜잭션 시작");
TransactionStatus inner = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("inner.isNewTransaction={}", inner.isNewTransaction()); //false
log.info("내부 트랜잭션 커밋");
txManager.commit(inner);
log.info("외부 트랜잭션 커밋");
txManager.commit(outer);
}
Java
복사
@Test
void outer_rollback() {
log.info("외부 트랜잭션 시작");
TransactionStatus outer = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("내부 트랜잭션 시작");
TransactionStatus inner = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("내부 트랜잭션 커밋");
txManager.commit(inner);
log.info("외부 트랜잭션 롤백");
txManager.rollback(outer);
}
Java
복사
@Test
void inner_rollback() {
log.info("외부 트랜잭션 시작");
TransactionStatus outer = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("내부 트랜잭션 시작");
TransactionStatus inner = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("내부 트랜잭션 롤백");
txManager.rollback(inner);
log.info("외부 트랜잭션 커밋");
txManager.commit(outer);
}
Java
복사
•
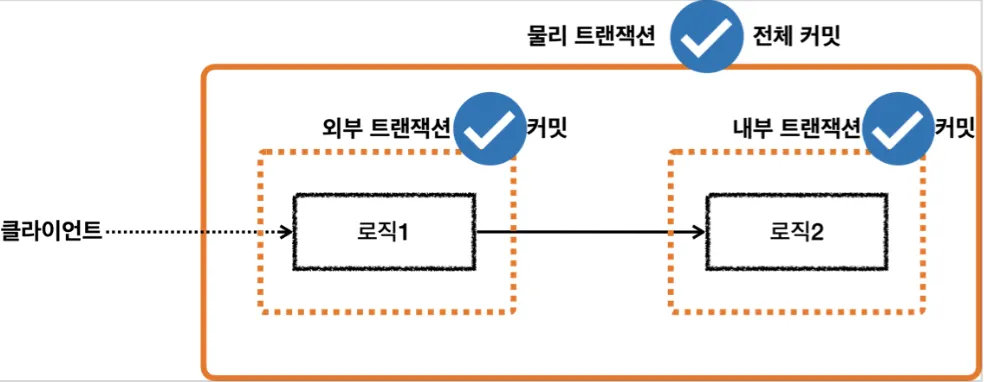
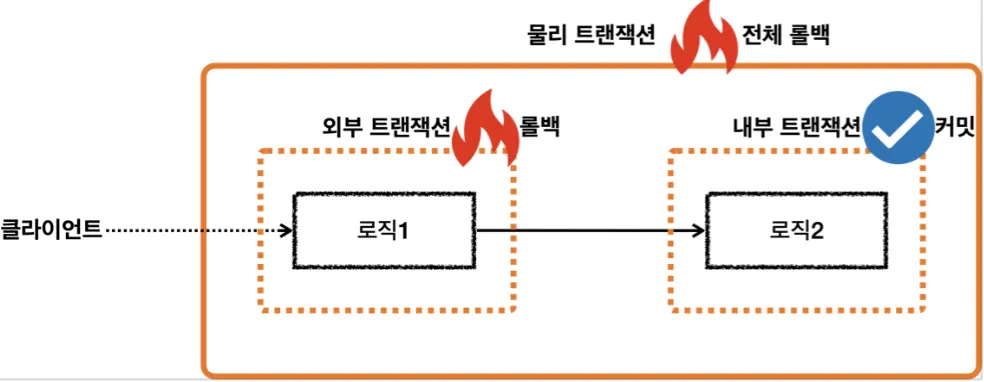
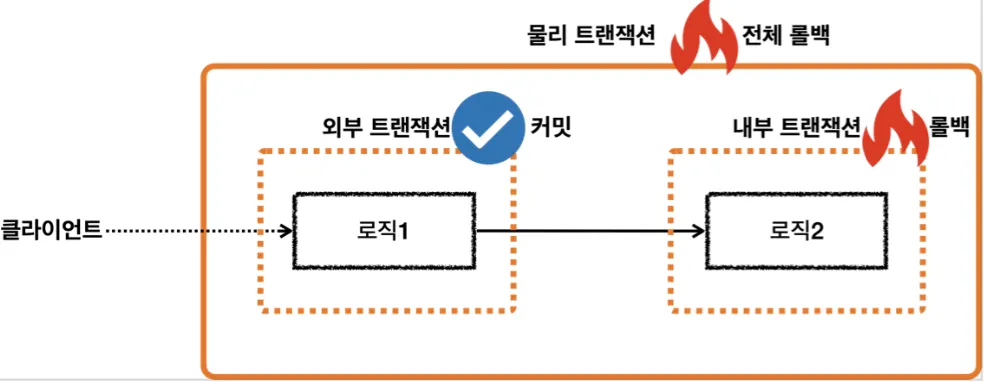
트랜잭션의 대원칙
◦
모든 논리 트랜잭션이 커밋되어야 물리 트랜잭션이 커밋된다.
◦
하나의 논리 트랜잭션이라도 롤백되면 물리 트랜잭션은 롤백된다.
•
TransactionStatus.isNewTransaction()
◦
트랜잭션이 신규 트랜잭션인지 확인한다.
◦
외부 트랜잭션에 참여한 내부 트랜잭션은 신규 트랜잭션이 아니므로 false이다.
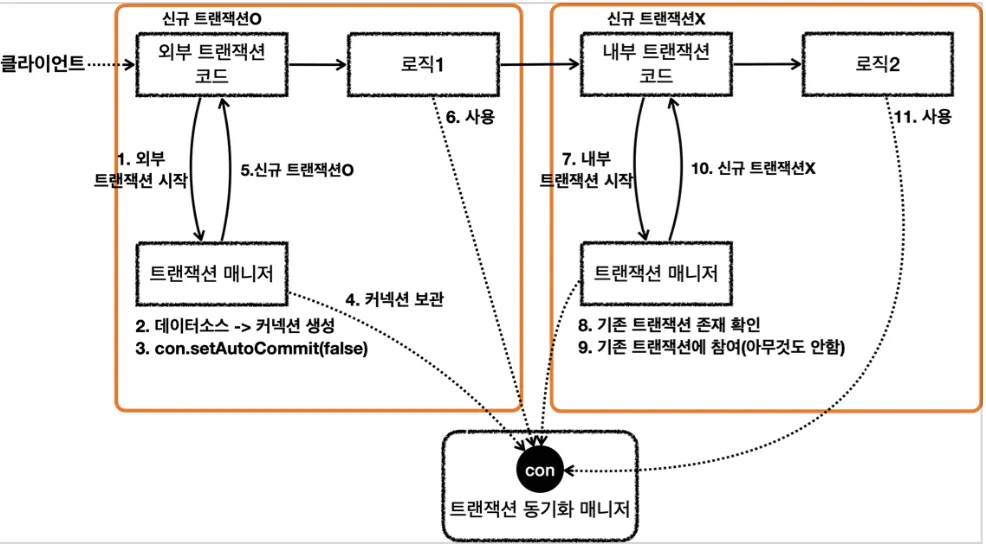
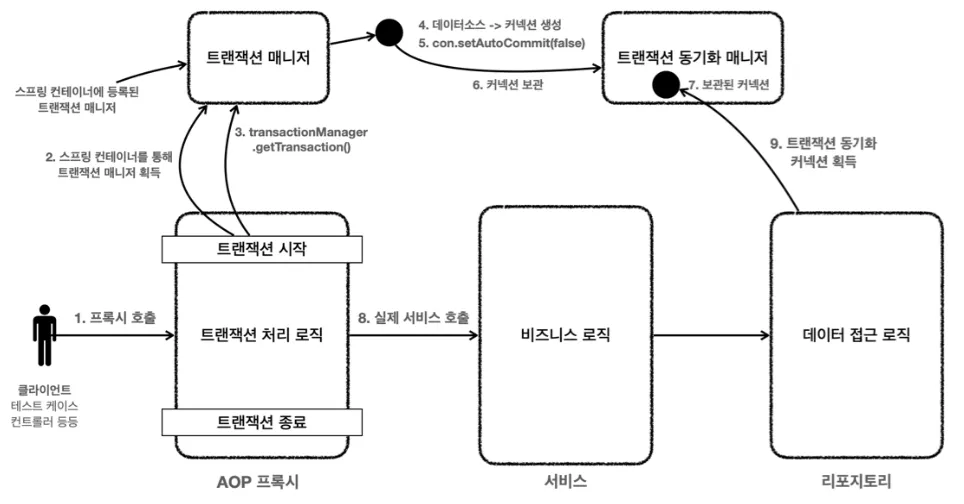
1.
txManager.getTransaction() 호출
2.
txManager가 데이터소스를 통해 커넥션 생성 후 setAutoCommit(false) 설정 - 외부(물리) 트랜잭션 시작 (isNewTransaction() == true)
3.
txManager가 트랜잭션 동기화 매니저에 커넥션 보관
4.
로직1 사용
5.
txManager.getTransaction() 호출
6.
txManager가 트랜잭션 동기화 매니저를 통해 기존 트랜잭션이 있는지 확인하고 존재하면 참여 - 내부 트랜잭션 시작 (isNewTransaction() == false)
7.
로직2 사용
•
둘 다 커밋하는 경우
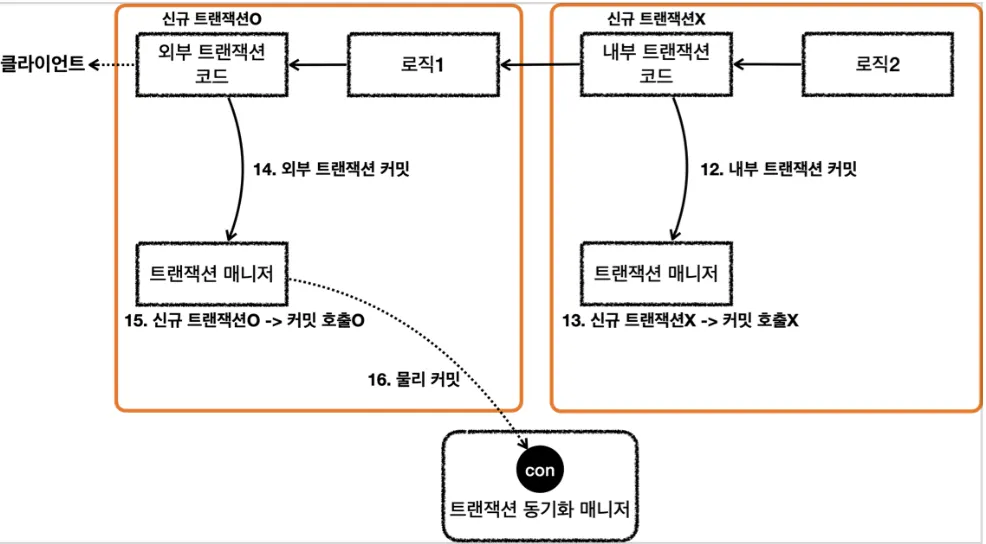
8.
로직2가 끝나고 txManager를 통해 내부 트랜잭션 커밋 (실제 커넥션을 커밋하진 않음)
9.
로직1이 끝나고 txManager를 통해 외부 트랜잭션 커밋 (실제 커넥션에 커밋 호출)
•
외부 트랜잭션이 롤백하는 경우
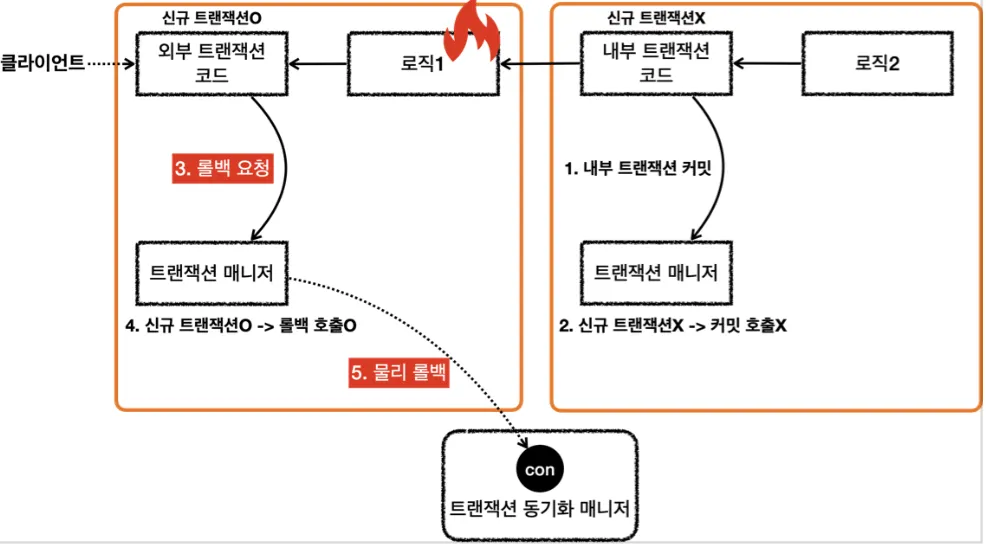
8.
로직2가 끝나고 txManager를 통해 내부 트랜잭션 커밋 (실제 커넥션을 커밋하진 않음)
9.
로직1이 끝나고 txManager를 통해 외부 트랜잭션 롤백 (실제 커넥션에 롤백 호출)
•
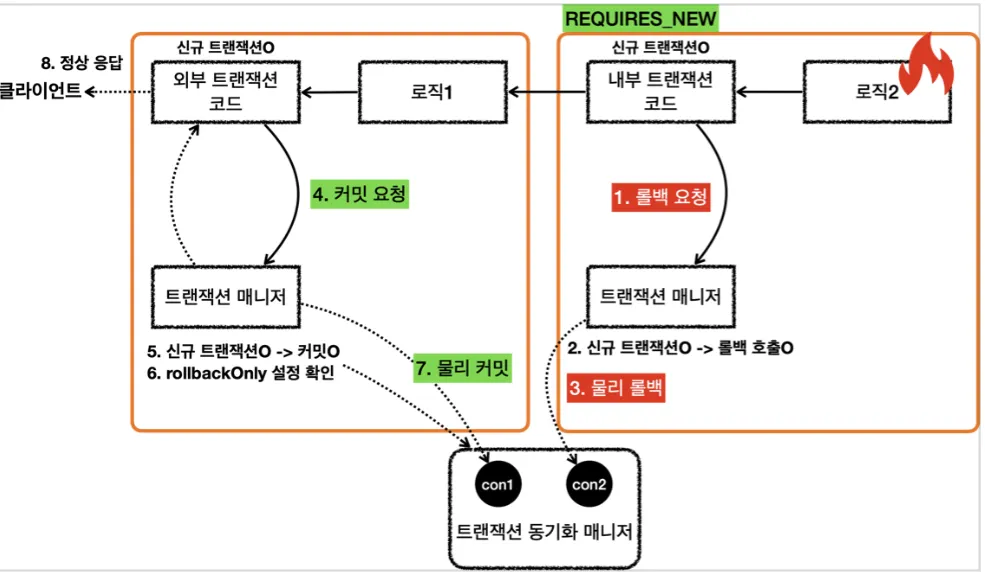
내부 트랜잭션이 롤백하는 경우
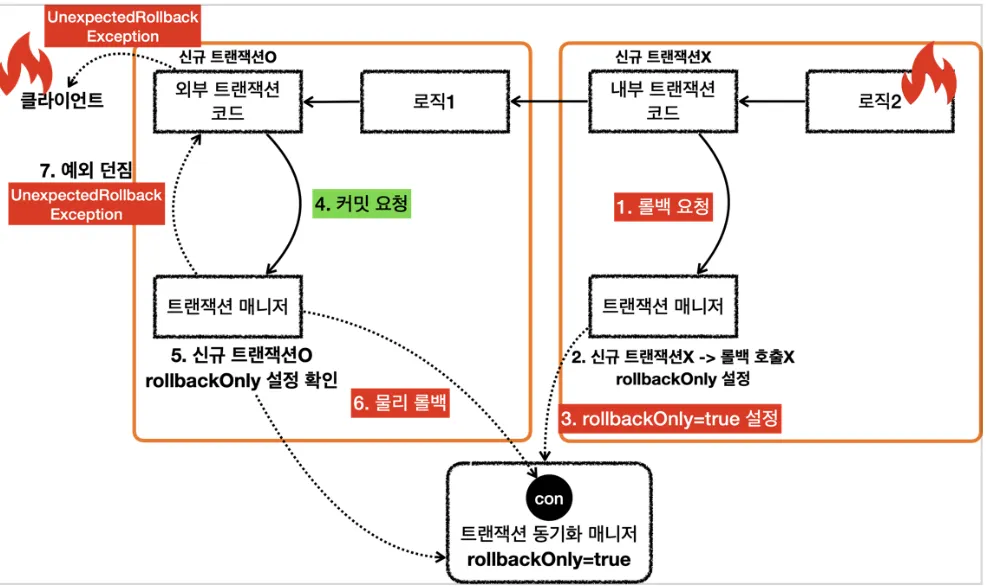
8.
로직2가 끝나고 txManager를 통해 내부 트랜잭션 롤백 (실제 커넥션을 롤백하지 않음)
9.
트랜잭션 동기화 매니저에 rollbackOnly = true로 표시
10.
로직1이 끝나고 txManager를 통해 외부 트랜잭션 커밋 (실제 커넥션에 커밋 호출)
11.
트랜잭션 동기화 매니저에 rollbackOnly = true 표시 확인 후 커밋 대신 롤백 호출
12.
UnexpectedRollbackException 런타임 예외를 던진다.
REQUIRES_NEW
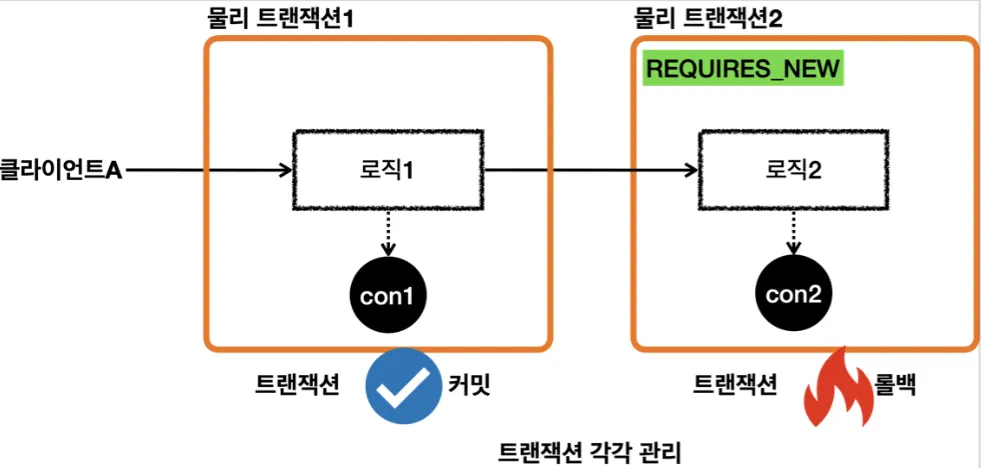
log.info("내부 트랜잭션 시작");
DefaultTransactionAttribute definition = new DefaultTransactionAttribute();
definition.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);
TransactionStatus inner = txManager.getTransaction(definition);
log.info("inner.isNewTransaction={}", inner.isNewTransaction()); //true
Java
복사
•
물리 트랜잭션을 분리하려면 내부 트랜잭션을 시작할 때 REQUIRES_NEW 옵션을 사용하면 된다.
•
커밋과 롤백은 서로가 영향을 주지 않는다.
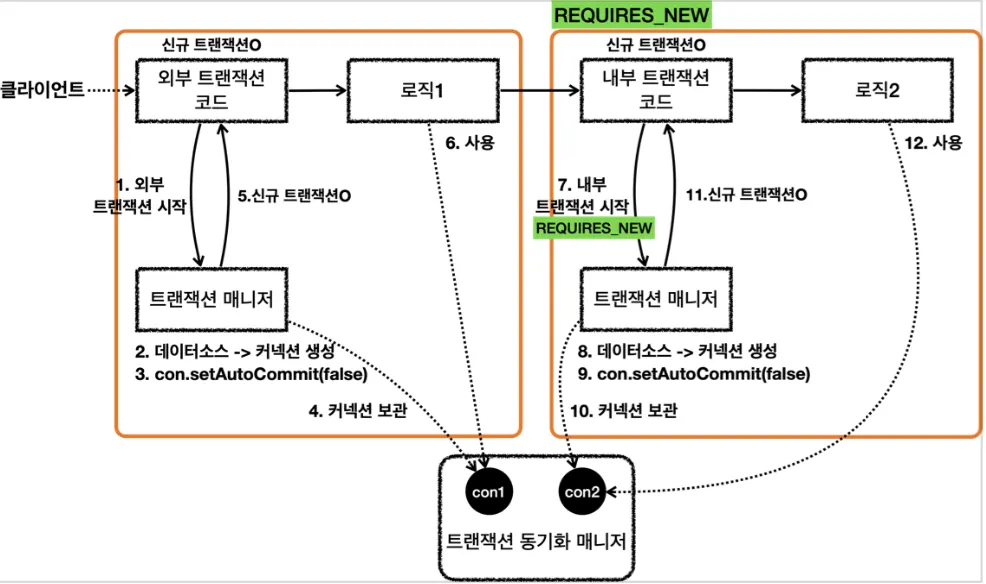
•
트랜잭션 동기화 매니저에서 서로 다른 커넥션을 가져와 독립된 물리 트랜잭션을 시작한다.
•
내부 트랜잭션이 실행되는 동안 외부 트랜잭션이 대기상태가 되기 때문에 데이터베이스 커넥션이 동시에 2개 사용되는 점을 주의해야 한다.
트랜잭션 전파 옵션
•
REQUIRED (기본 설정)
◦
기존 트랜잭션 없음 : 새로운 트랜잭션을 생성
◦
기존 트랜잭션 있음 : 기존 트랜잭션에 참여
•
REQUIRES_NEW
◦
기존 트랜잭션 없음 : 새로운 트랜잭션을 생성
◦
기존 트랜잭션 있음 : 새로운 트랜잭션을 생성
•
SUPPORT
◦
기존 트랜잭션 없음 : 트랜잭션 없이 진행
◦
기존 트랜잭션 있음 : 기존 트랜잭션에 참여
•
NOT_SUPPORT
◦
기존 트랜잭션 없음 : 트랜잭션 없이 진행
◦
기존 트랜잭션 있음 : 트랜잭션 없이 진행 (기존 트랜잭션은 보류)
•
MANDATORY
◦
기존 트랜잭션 없음 : IllegalTransactionStateException 예외 발생
◦
기존 트랜잭션 있음 : 기존 트랜잭션에 참여
•
NEVER
◦
기존 트랜잭션 없음 : 트랜잭션 없이 진행
◦
기존 트랜잭션 있음 : IllegalTransactionStateException 예외 발생
•
NESTED
◦
기존 트랜잭션 없음 : 새로운 트랜잭션을 생성
◦
기존 트랜잭션 있음 : 중첩 트랜잭션을 만든다
▪
외부 트랜잭션의 영향은 받지만 중첩 트랜잭션은 외부에 영향을 주지 않는다.
▪
중첩 트랜잭션이 롤백 되어도 외부 트랜잭션은 커밋할 수 있다.
▪
외부 트랜잭션이 롤백 되면 중첩 트랜잭션도 함께 롤백된다.
▪
JPA에서 사용할 수 없다.
+ isolation, timeout, readOnly 등은 트랜잭션이 처음 시작될 때만 적용된다. (참여하는 경우 적용 X)