 문제
문제
기존에는 파일을 MultipartFile로 받아 S3에 PUT으로 저장한 후 조회하는 과정에서 각 파일에 대해 GET 요청을 통해 실제로 S3에 있는지 확인한 후 CDN URL을 문자열 조합하여 응답하는 방식이었습니다.
이 때 저장하는 과정에서 파일의 이름을 강제로 고정했기 때문에 S3의 파일이 변경되어도 CDN URL은 변경되지 않았고 FE에서의 캐싱이 이를 감지하지 못하여 변경된 파일로 업데이트되지 않았습니다.
해결 방법
우선 파일의 이름을 강제로 고정하는 방식에서 파일의 이름을 UUID를 사용한 이름으로 저장하는 방식으로 변경하기로 하였습니다.
이를 통해 파일이 변경될 때마다 CDN URL도 함께 변경되어 FE쪽에서 감지하여 새로 캐싱할 수 있게 하였습니다.
또한 UUID를 통한 고유의 파일 이름을 BE에서 관리하기 쉽게 하며 S3에 대한 GET 요청을 없애기 위해 파일의 이름을 DB 컬럼으로 저장하도록 변경하였습니다.
해결 과정
// 수정 전
public void uploadLogo(Long companyId, String name, MultipartFile logo) {
if(logo == null || logo.isEmpty()) {
return;
}
if(logo.getSize() > 1000000) {
throw new CustomException(ErrorCode.EXCEED_SIZE_FILE);
}
int pos = logo.getOriginalFilename().lastIndexOf(".");
String extension = logo.getOriginalFilename().substring(pos + 1);
if (!imageExtension.contains(extension.toLowerCase())) {
throw new CustomException(ErrorCode.INVALID_TYPE);
}
try {
ObjectMetadata objectMetadata = new ObjectMetadata();
objectMetadata.setContentType(logo.getContentType());
objectMetadata.setContentLength(logo.getSize());
amazonS3Client.putObject(bucket + "/companies/" + companyId, name, logo.getInputStream(), objectMetadata);
} catch (MaxUploadSizeExceededException e) {
throw new CustomException(ErrorCode.EXCEED_SIZE_S3);
} catch (Exception e) {
throw new CustomException(ErrorCode.FAIL_UPLOAD_FILE);
}
}
// 수정 후
public String uploadLogo(Long companyId, MultipartFile file) {
if(file == null || file.isEmpty()) {
return null;
}
if(file.getSize() > 1000000) {
throw new CustomException(ErrorCode.EXCEED_SIZE_FILE);
}
String randomName = StringUtils.replace(UUID.randomUUID().toString(), "-", "");
int pos = Objects.requireNonNull(file.getOriginalFilename()).lastIndexOf(".");
String extension = file.getOriginalFilename().substring(pos + 1);
if (!imageExtension.contains(extension.toLowerCase())) {
throw new CustomException(ErrorCode.INVALID_TYPE);
}
try {
ObjectMetadata objectMetadata = new ObjectMetadata();
objectMetadata.setContentType(file.getContentType());
objectMetadata.setContentLength(file.getSize());
amazonS3Client.putObject(bucket + "/companies/" + companyId, randomName + "." + extension, file.getInputStream(), objectMetadata);
return bucket + "/companies/" + companyId + "/" + randomName + "." + extension;
} catch (MaxUploadSizeExceededException e) {
throw new CustomException(ErrorCode.EXCEED_SIZE_S3);
} catch (Exception e) {
throw new CustomException(ErrorCode.FAIL_UPLOAD_FILE);
}
}
Java
복사
위 코드는 S3 SDK 라이브러리를 사용하기 위한 S3Util 클래스에서 기업 로고를 업로드 하기 위한 메서드입니다.
UUID로 만들어진 randomName을 파일의 이름으로 S3에 PUT 하게 변경하였습니다.
//수정 전
public ResponseDTO saveCompany(CompanyFactorySaveDTO companyFactorySaveDTO, MultipartFile logo) {
Company company = companyFactorySaveDTO.toEntity(StatusCode.IN_PROGRESS);
companyRepository.save(company);
s3Util.uploadLogo(company.getId(), "logo.png", logo);
return ResponseDTO.builder()
.status(HttpStatus.CREATED.value())
.statusName(HttpStatus.CREATED.name())
.build();
}
// 수정 후
public ResponseDTO saveCompany(CompanyFactorySaveDTO companyFactorySaveDTO, MultipartFile logo) {
Company company = companyFactorySaveDTO.toEntity(StatusCode.IN_PROGRESS);
if(logo != null && !logo.isEmpty()) {
String fileUrl = s3Util.uploadLogo(company.getId(), logo);
company.setLogoUrl(fileUrl);
}
companyRepository.save(company);
return ResponseDTO.builder()
.status(HttpStatus.CREATED.value())
.statusName(HttpStatus.CREATED.name())
.build();
}
Java
복사
위 코드는 어드민 서비스에서 기업을 등록하는 메서드입니다.
기존에 파일 이름을 지정하여 단순 업로드만 하는 방식에서 파일을 업로드 한 후 랜덤으로 만들어진 이름을 logo_url 컬럼에 저장하는 방식으로 변경하였습니다.
// 수정 전
public ResponseDTO updateCompany(CompanyUpdateDTOforAdmin companyUpdateDTOforAdmin, MultipartFile logo, Long companyId) {
Company company = companyRepository.findById(companyId);
if(company == null) {
throw new CustomException(ErrorCode.BLANK_COMPANY);
}
company.updateCompany(companyUpdateDTOforAdmin);
//Create Position
company.createFactory(company, companyUpdateDTOforAdmin);
//Update Position
companyUpdateDTOforAdmin.getFactoryArr().stream()
.filter(p -> p.getId() != null)
.forEach(i -> {
Factory factory = factoryRepository.findById(i.getId());
factory.updateFactory(i);
});
//Delete Position
company.deleteCompany(companyUpdateDTOforAdmin);
s3Util.uploadLogo(company.getId(), "logo.png", logo);
return ResponseDTO.builder()
.status(HttpStatus.OK.value())
.statusName(HttpStatus.OK.name())
.build();
}
// 수정 후
public ResponseDTO updateCompany(CompanyUpdateDTOforAdmin companyUpdateDTOforAdmin, MultipartFile logo, Long companyId) {
Company company = companyRepository.findById(companyId);
if(company == null) {
throw new CustomException(ErrorCode.BLANK_COMPANY);
}
if(logo != null && !logo.isEmpty()) {
if (company.getLogoUrl() != null) {
int pos = company.getLogoUrl().lastIndexOf("/");
String fileName = company.getLogoUrl().substring(pos + 1);
s3Util.deleteObject("companies", fileName);
}
String fileUrl = s3Util.uploadLogo(company.getId(), logo);
company.setLogoUrl(fileUrl);
}
company.updateCompany(companyUpdateDTOforAdmin);
//Create Position
company.createFactory(company, companyUpdateDTOforAdmin);
//Update Position
companyUpdateDTOforAdmin.getFactoryArr().stream()
.filter(p -> p.getId() != null)
.forEach(i -> {
Factory factory = factoryRepository.findById(i.getId());
factory.updateFactory(i);
});
//Delete Position
company.deleteCompany(companyUpdateDTOforAdmin);
return ResponseDTO.builder()
.status(HttpStatus.OK.value())
.statusName(HttpStatus.OK.name())
.build();
}
Java
복사
어드민 서비스에서 기업을 수정하는 로직에서도 기존 logo.png 파일을 덮어씌우는 방식에서
DB에 저장된 파일 URL을 이용해 기존 파일을 삭제한 후 새로운 파일을 다시 저장하는 방식으로 변경하였습니다.
company.setLogoUrl(s3Util.getUrl("companies", company.getId(), "logo.png"));
Java
복사
위 코드처럼 조회 시 기업 로고 URL이 들어가는 부분은 S3에 logo.png라는 이름의 파일을 GET 요청으로 있는지 확인한 후 CDN URL을 문자열 조합해 직접 넣어주는 방식이었습니다.
위 코드를 모두 제거한 후 Repository를 통해 DB에서 꺼낼 때 DB에 저장되어 있는 로고 URL을 DTO로 받아서 출력하는 방식으로 변경하였습니다.
같은 방식으로 배너 이미지 업로드 로직도 수정하였습니다.
//S3 Object List를 받아와서 id 리스트만 뽑아오는 Python 코드
accessKey = ''
secretKey = ''
region = ''
bucket_name = ''
prefix = ''
import boto3
s3 = boto3.client('s3', aws_access_key_id=accessKey, aws_secret_access_key=secretKey, region_name=region)
obj_list = s3.list_objects(Bucket=bucket_name, Prefix=prefix)
contents_list = obj_list['Contents']
id_list = []
for content in contents_list:
key = content['Key']
parse1 = key[key.find('/') + 1:]
parse2 = parse1[0:parse1.find('/')]
id_list.append(int(parse2))
id_list.sort()
str(id_list)
print(id_list)
Java
복사
//모든 logo_url에 기존 CDN URL을 넣어주기 위한 SQL 코드
UPDATE company
SET company.logo_url = CONCAT('https://cdn.gocho-back.com/companies/', company.id, '/logo.png')
WHERE company.logo_url IS NULL;
Java
복사
//Python으로 뽑아온 ID 리스트에 포함되지 않는 Row는 logo_url을 NULL로 바꾸는 SQL 코드
UPDATE company
SET company.logo_url = NULL
WHERE company.id NOT IN (ID 리스트);
Java
복사
마지막으로 파이썬과 SQL을 이용하여 현재 S3에 올라가있는 파일들과 DB에 CDN URL의 싱크를 맞춰주었습니다.
테스트
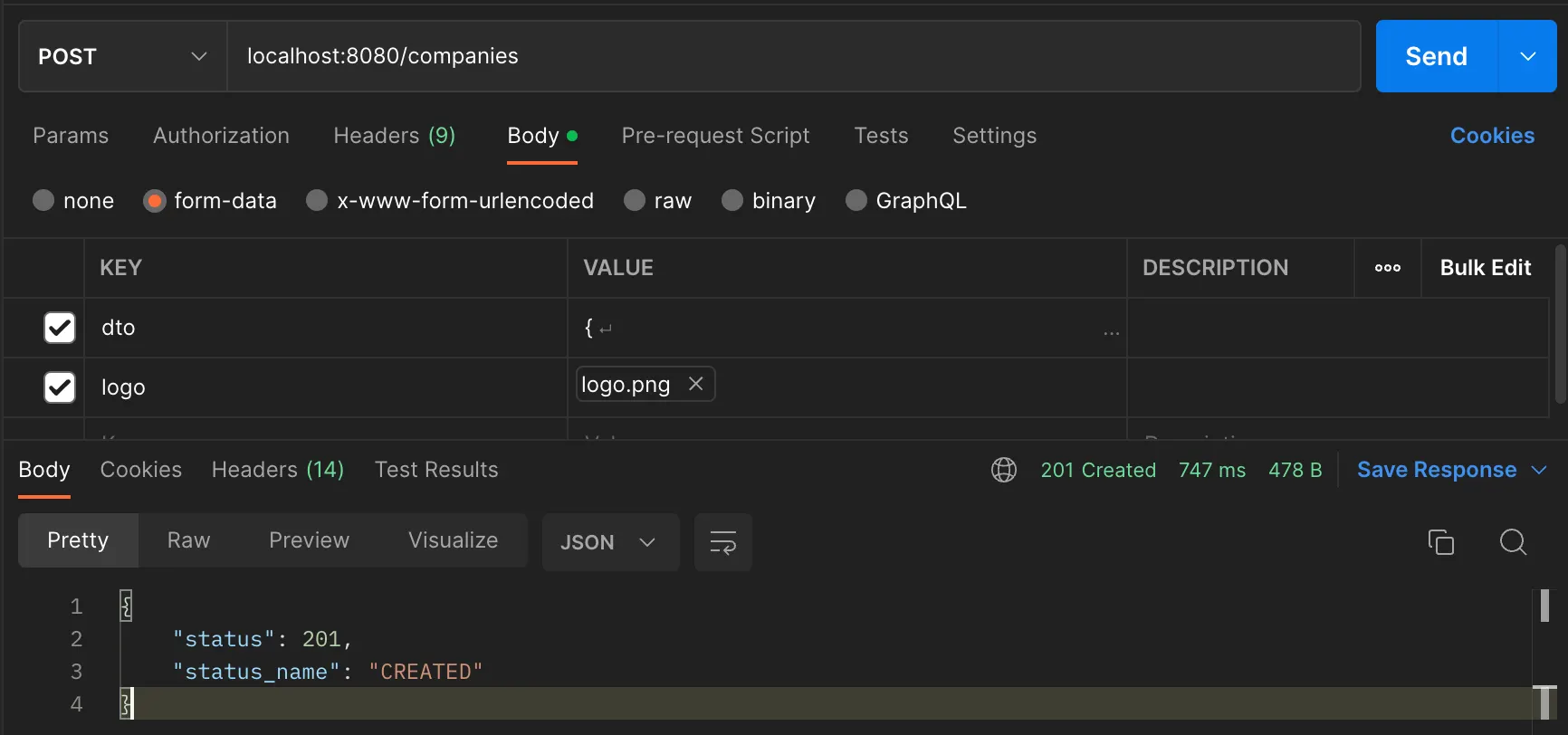
먼저 포스트맨으로 기업 등록 API 를 통해 로고 업로드를 시도해보았습니다.

랜덤으로 이름이 생성되어 DB에 잘 저장되어 있는 모습을 확인할 수 있습니다.
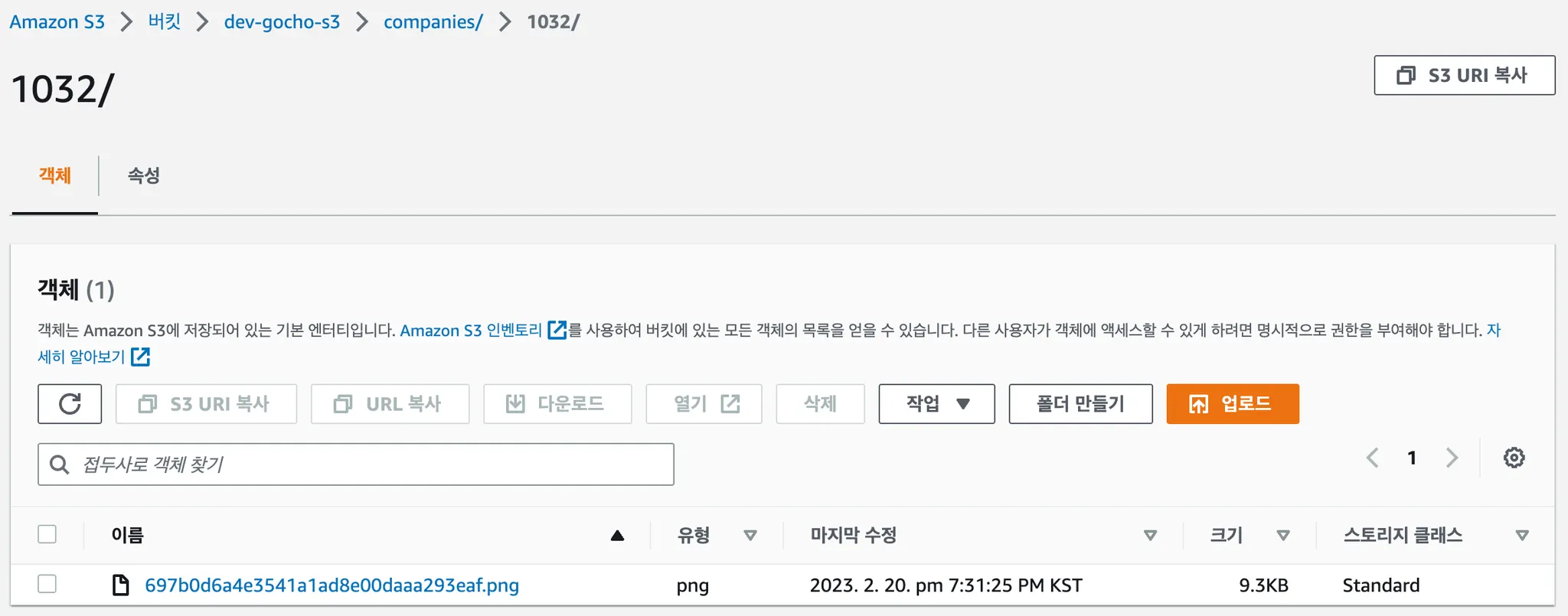
S3 또한 DB에 저장된 이름과 같은 이름으로 정확한 위치에 잘 저장된 것을 확인할 수 있습니다.

DB에 저장된 CDN URL을 통해 정상적으로 접근할 수 있는 것도 확인할 수 있었습니다.
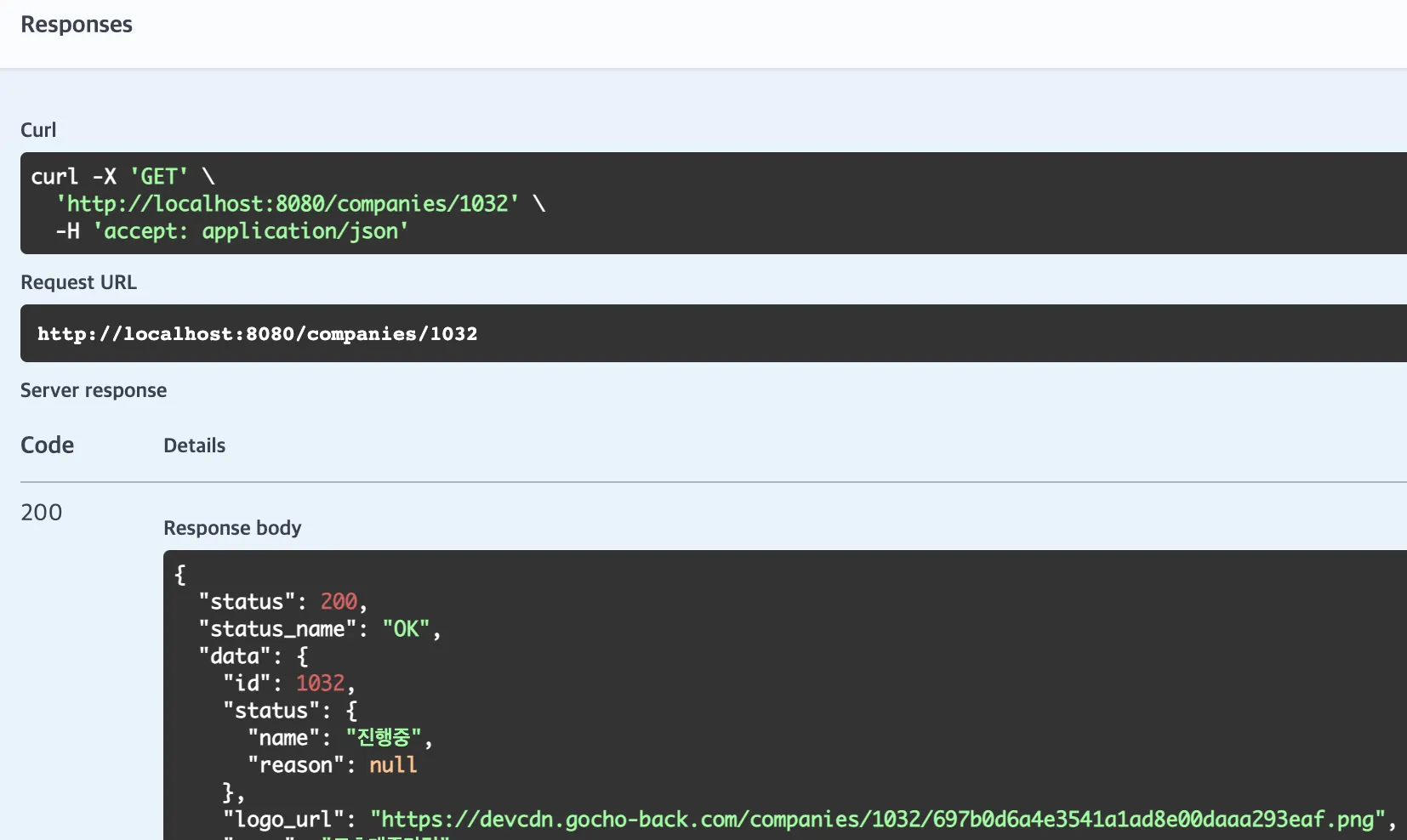
조회 API 에서도 DB에 있는 CDN URL이 잘 조회되는 것을 확인하였습니다.
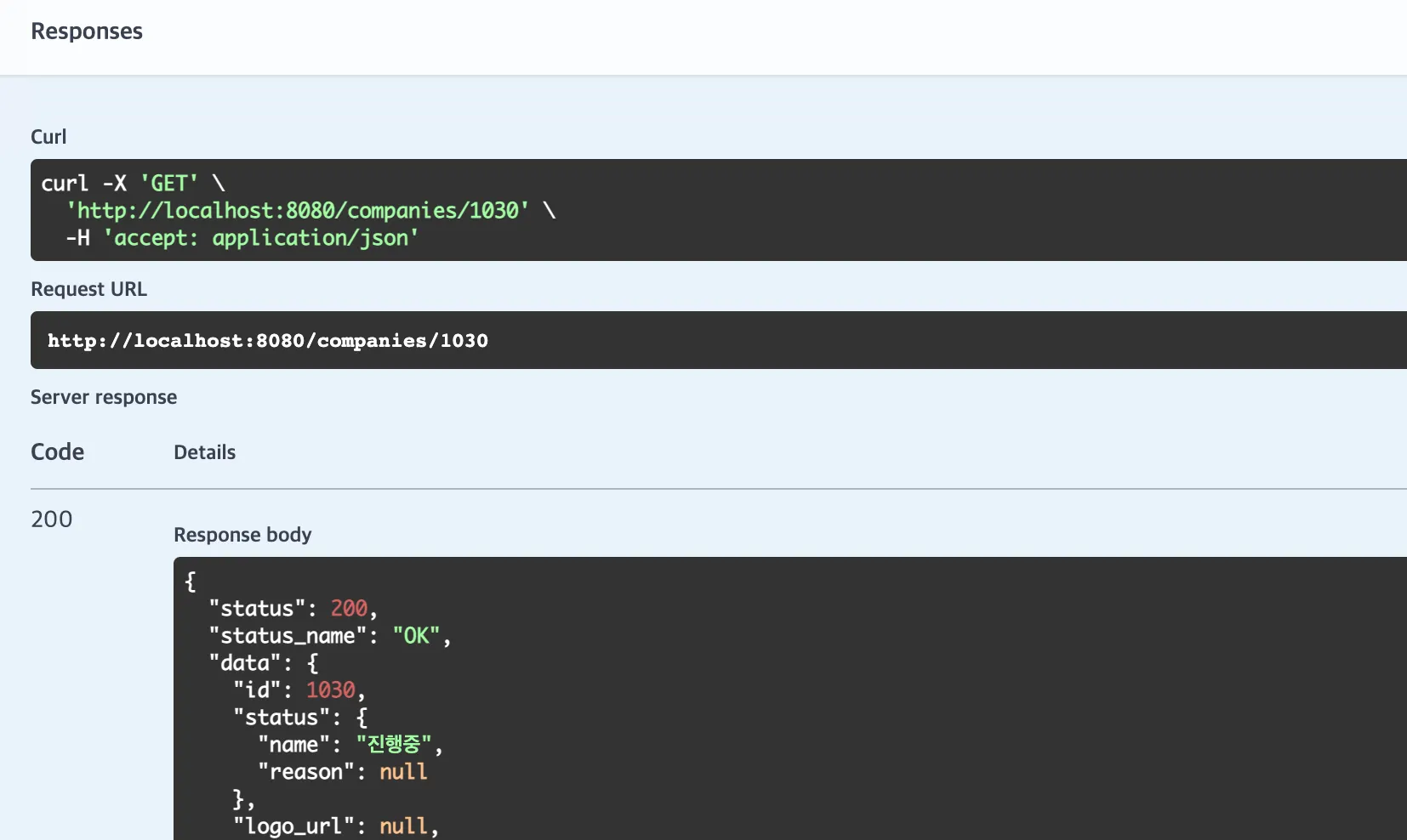
로고가 등록되지 않은 경우엔 정상적으로 null이 출력되었습니다.

기업 수정에서 로고를 수정하였을 때 아까와는 다른 CDN URL이 저장된 것을 확인할 수 있습니다.
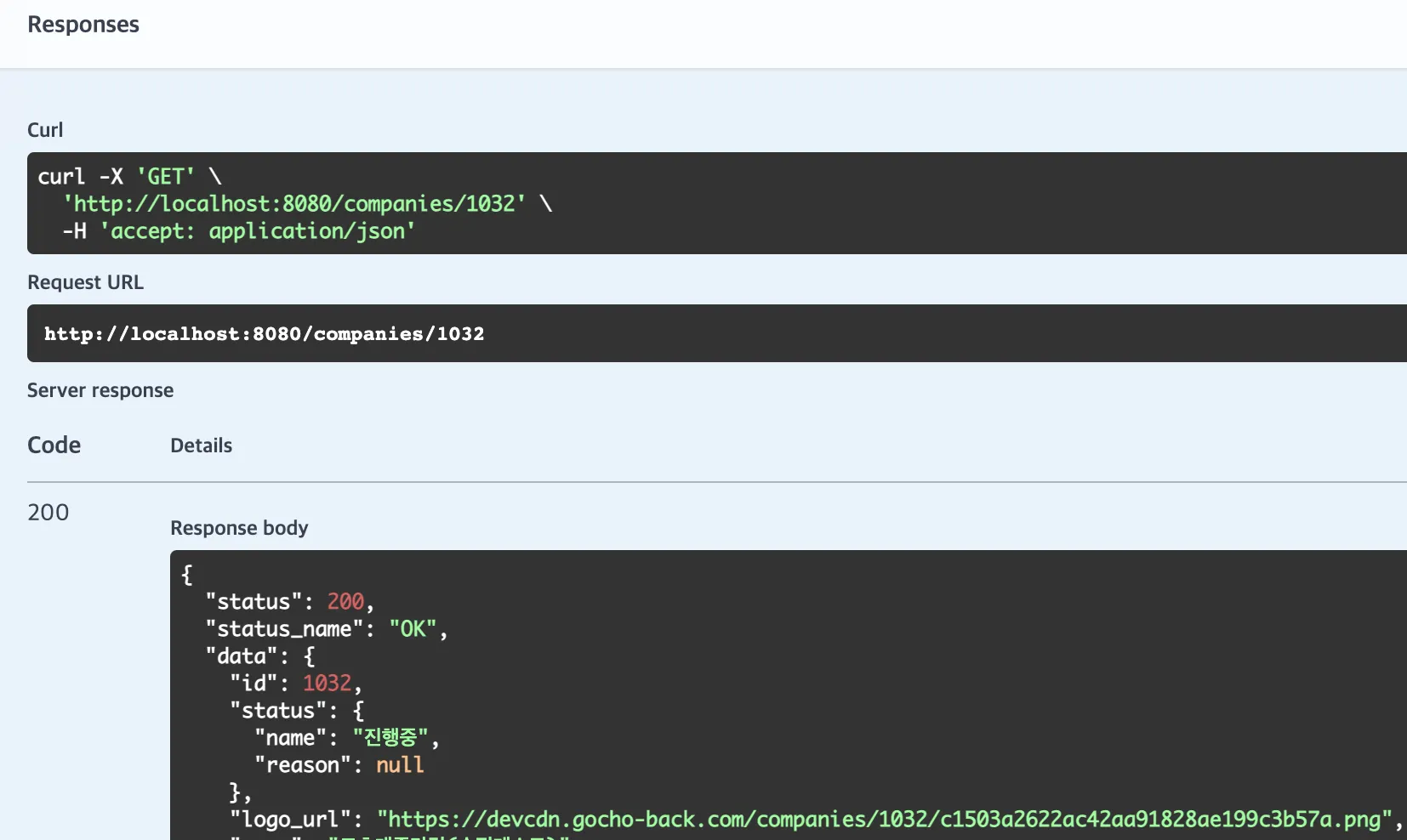
조회 API에서도 변경된 CDN URL이 조회되는 모습을 확인하였습니다.
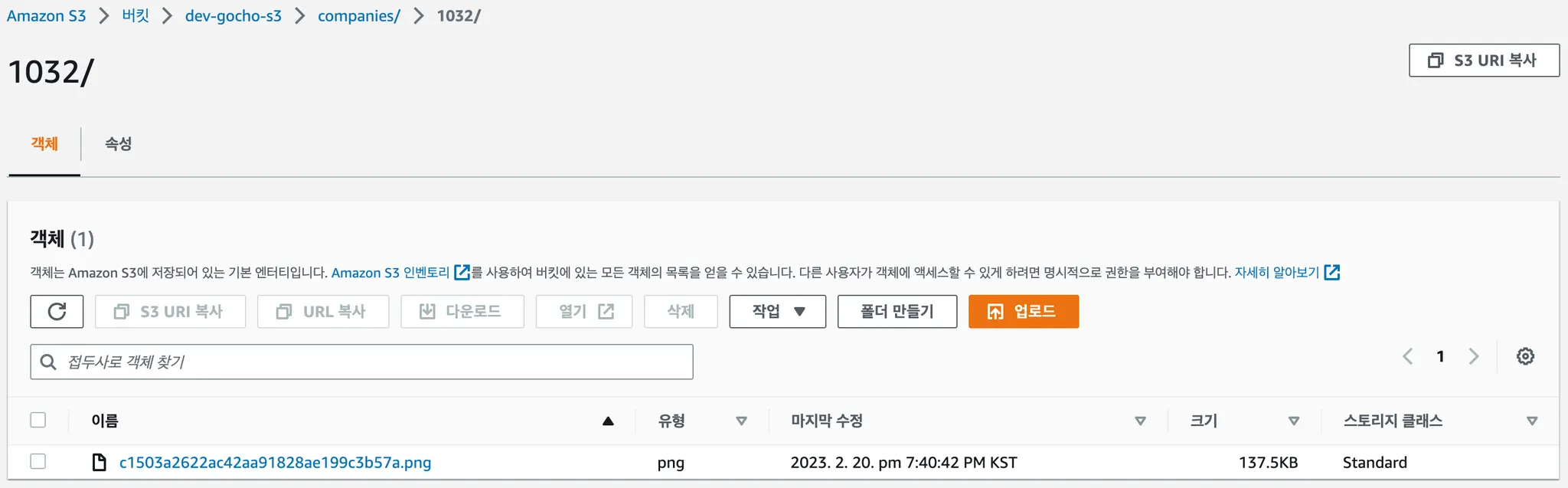
S3에도 정상적으로 기존의 이미지가 삭제되고 새로운 이미지가 업로드된 것을 확인할 수 있습니다.
DB에 새로 저장된 CDN URL도 접근이 잘 되는 것을 확인하였습니다.
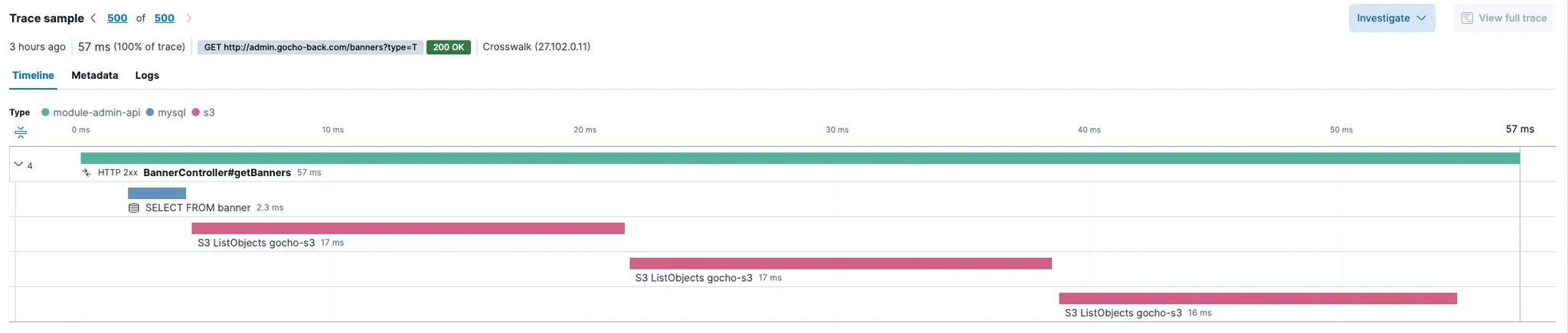
변경 전 APM

변경 후 APM
설치 해놓은 APM으로 Dependency를 확인한 결과 CDN URL 교체하기 전에 존재하던 S3 Dependency가 사라진 것을 확인할 수 있었습니다.
비용면에서는 기존에도 S3 Endpoint를 사용하고 있었기 때문에 NAT Gateway의 사용을 줄인거에 비해서 큰 변화가 없었습니다.
관련 문서
없음