키
키(key)는 데이터베이스에서 튜플을 구분하기 위한 속성 또는 속성의 집합을 의미한다.
키는 유일성과 최소성이라는 두 가지 특성을 가질 수 있다.
•
유일성
하나의 키 값으로 튜플을 식별할 수 있는 특성
•
최소성
튜플을 식별하는데 필요한 속성만으로 이루어져 있는 특성
DBMS(Database Management System)에는 다음과 같이 다섯가지 키가 있다.
•
슈퍼 키
튜플을 식별할 수 있어서 유일성은 만족하지만 후보 키와 달리 최소성을 만족하지 않아도 된다.
•
후보 키
튜플을 식별할 수 있는 유일성과 필요한 속성만으로 구성되는 최소성을 만족해야 한다.
•
기본 키
후보 키 중에서 메인이 되는 키로 NULL 값을 가지면 안 된다.
•
대체 키
후보 키 중 기본 키를 제외한 키다.
•
외래 키
다른 테이블의 기본 키를 참조하는 키다.
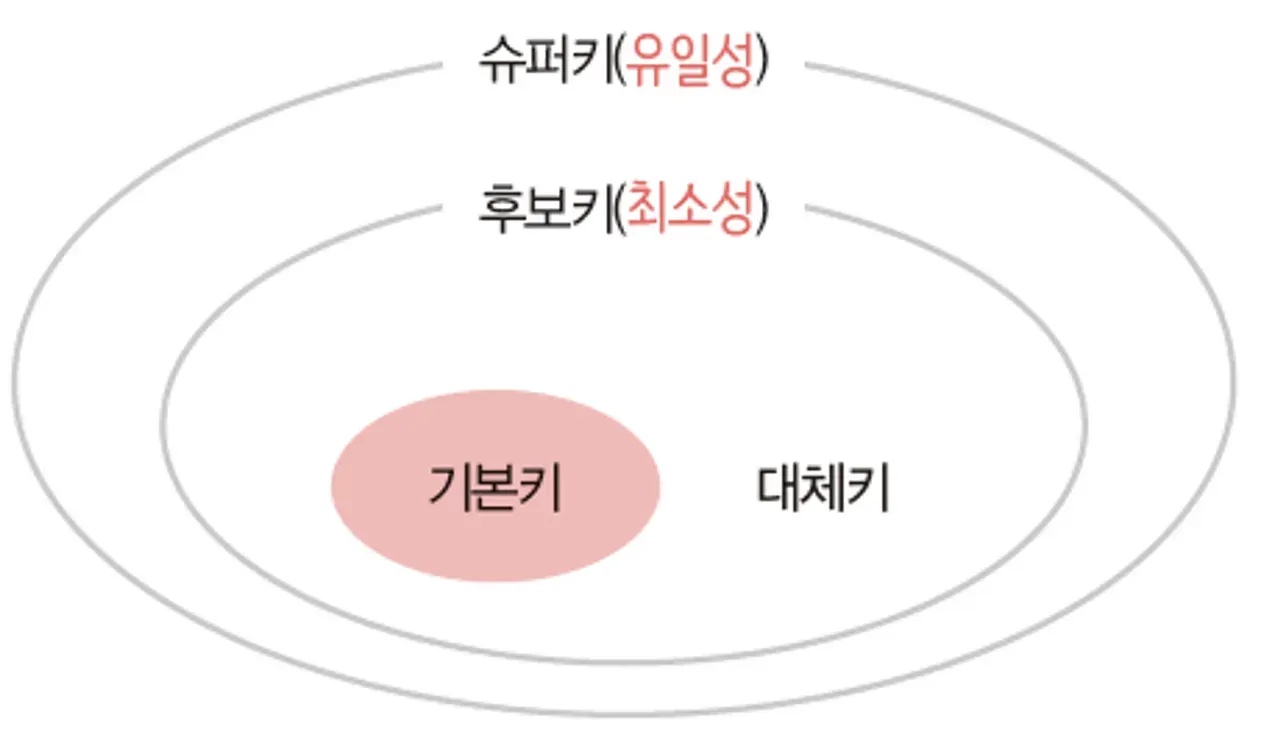
슈퍼 키는 튜플을 식별할 수 있는 키를 의미해서 후보 키, 기본 키, 대체 키를 포괄한다.
슈퍼 키 중 최소성을 만족하면 후보 키, 후보 키 중 메인이 되는 키를 기본 키, 그 외 키를 대체 키라고 한다.
무결성
무결성은 데이터베이스에 저장된 데이터와 실제 데이터가 일치하는 정확성과, 데이터가 일정하게 유지되는 일관성을 의미한다.
DBMS는 데이터베이스를 조작하고 제어해 데이터의 무결성을 유지하는 기능을 한다.
데이터 무결성의 종류는 다음과 같다.
•
개체 무결성
모든 테이블이 기본 키를 가져야 한다.
기본 키의 값은 NULL이 될 수 없으며 중복되지 않고 고유한 값을 가져야 한다.
•
도메인 무결성
테이블의 속성 값은 도메인(domain)에 속해야 한다.
도메인은 속성이 가질 수 있는 값의 집합을 의미한다.
•
참조 무결성
외래 키의 값은 참조하는 테이블의 기본 키 값과 동일하거나 NULL이어야 한다.
인덱스
인덱스(index)는 데이터베이스에서 튜플의 검색 성능을 높이기 위해 속성 값과 튜플이 저장된 주소를 저장하는 것을 말한다.
키-값 형태로 속성 값-튜플 주소를 인덱스 테이블에 저장한다.
인덱스 테이블은 다음처럼 속성 값을 기준으로 정렬 상태를 유지한다.
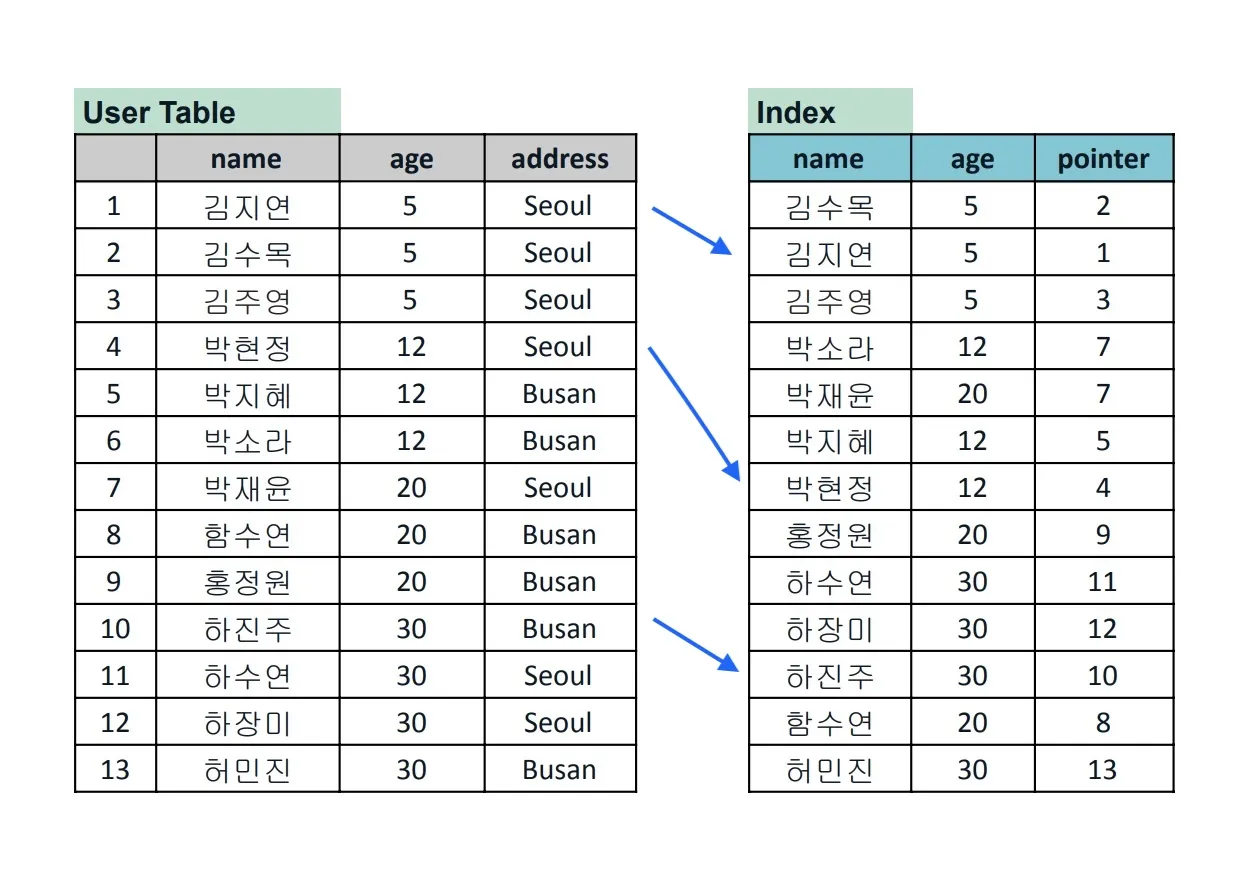
인덱스 테이블을 이용했을 때 다음과 같은 장단점이 있다.
•
장점
◦
인덱스 테이블에 데이터가 정렬되어 있어서 검색 속도가 빠르다.
•
단점
◦
인덱스 테이블을 저장하기 위한 추가 공간이 필요하다.
◦
정렬된 상태를 유지하기 위해 데이터를 추가, 수정, 삭제하는 경우에는 속도가 느리다.
인덱스를 사용하면 데이터 검색 속도에서 이점이 있다.
하지만 데이터를 추가하면 데이터를 재정렬해야 하므로 오히려 처리 비용이 증가할 수 있다.
또한 튜플의 삭제 연산이 발생하는 경우 인덱스 테이블에서 데이터는 ‘사용하지 않음’ 처리가 되지만 실제로 삭제되지 않고 테이블에 남아 있다.
즉, 삭제 연산이 빈번하게 일어나면 인덱스 테이블 크기는 일정하지만 실제로 사용하는 데이터는 적어서 성능이 저하될 수 있다.
따라서 데이터 양이 방대하며 데이터 변경보다는 검색을 자주하는 경우에 인덱스를 사용하는 것이 좋다.
인덱스를 구현하는 대표적인 방법으로는 해시 테이블과 B+-트리가 있다.
•
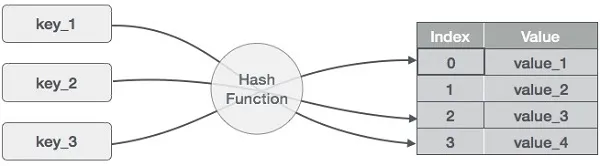
해시 테이블 인덱스
해시 테이블(hash table)은 속성 값으로 해시 값을 계산해 인덱싱하는 방법이다.
해시 함수의 특성상 속성 값을 그대로 검색해야 해서 검색하려는 값을 온전히 입력할 때만 사용할 수 있다.
그래서 검색 속도가 빠른데도 자주 사용하지 않는 방식이다.
•
B+- 트리 인덱스
인덱스 테이블을 구현할 때 트리 구조의 B+ 트리 인덱스 또는 B- 트리 인덱스 방식을 많이 사용한다.
여기서 B는 Balaced를 의미한다.
B+ 트리는 단말 노드에만 데이터를 저장하고 단말 노드 간에는 연결 리스트로 연결되는 방식이다.
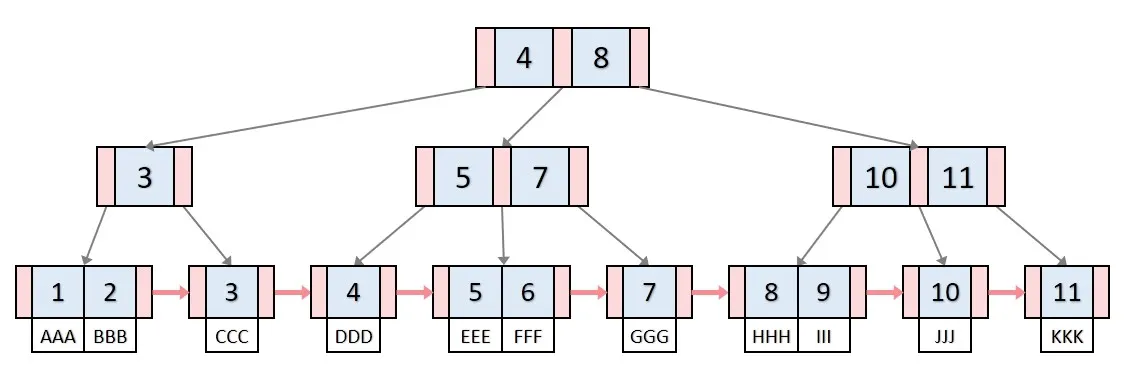
B- 트리는 모든 노드에 데이터가 저장되는 방식이다.
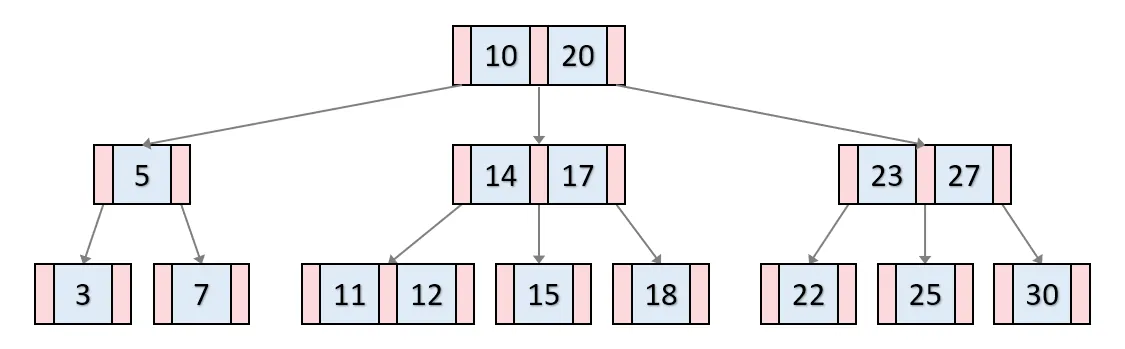
B+ 트리 인덱스나 B- 트리 인덱스를 사용하면 데이터의 삽입, 갱신, 삭제 등에 드는 작업 비용을 줄일 수 있다.
또한 해시 테이블 인덱스와 달리 속성을 범위로 검색할 수 있어서 특정 문자로 시작하는 속성값의 인덱스를 찾는 것이 가능하다.
ORM
ORM(Object-Relational Mapping)은 객체와 관계형 데이터베이스를 매핑하는 도구를 의미한다.
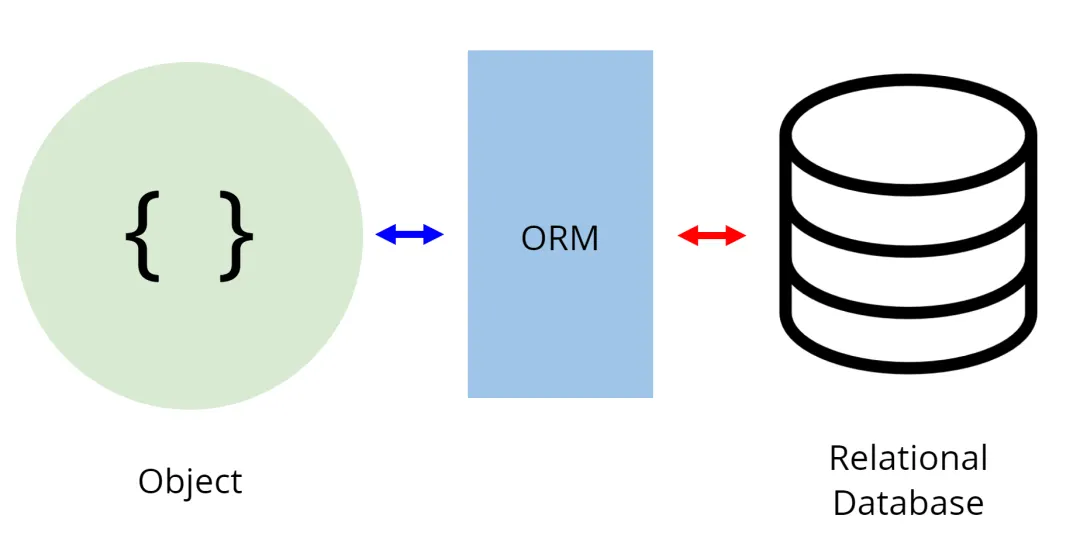
데이터베이스를 프로그래밍 언어의 객체 관점으로 바라볼 수 있어서 객체 지향 프로그래밍 언어를 이용해 프로그램을 개발할 때 편리하다.
SQL 문을 사용하지 않고 객체 지향적 코드를 작성할 수 있어서 코드의 가독성을 높이고 개발자 편의성을 증대할 수 있다.
하지만 복잡한 프로젝트를 수행할 때는 ORM만으로 서비스를 구현하기 어려울 수 있다.
대표적인 ORM 프레임워크로는 자바의 하이버네이트, 파이썬의 장고ORM, 루비의 액티브 레코드 등이 있다.