•
코루틴을 사용하여 기본 스레드나 콜백을 차단하지 않고 네트워크 요청을 수행하는 방법을 알아보자.
Blocking 요청
예제 코드
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
fun getOrgReposCall(
@Path("org") org: String
): Call<List<Repo>>
@GET("repos/{owner}/{repo}/contributors?per_page=100")
fun getRepoContributorsCall(
@Path("owner") owner: String,
@Path("repo") repo: String
): Call<List<User>>
}
Kotlin
복사
•
이 API는 주어진 조직에 속한 저장소 목록과 각 저장소의 기여자 목록을 요청하는 기능을 제공한다.
•
이 API는 아래의 loadContributorsBlocking() 함수에서 사용되며 주어진 조직의 기여자 목록을 가져온다.
fun loadContributorsBlocking(
service: GitHubService,
req: RequestData
): List<User> {
val repos = service
.getOrgReposCall(req.org) // #1
.execute() // #2
.also { logRepos(req, it) } // #3
.body() ?: emptyList() // #4
return repos.flatMap { repo ->
service
.getRepoContributorsCall(req.org, repo.name) // #1
.execute() // #2
.also { logUsers(repo, it) } // #3
.bodyList() // #4
}.aggregate()
}
Kotlin
복사
•
주어진 조직에 속한 저장소 목록을 가져와 repos 리스트에 저장한다.
•
그런 다음 각 저장소에 대해 기여자 목록을 요청하고 모든 목록을 하나로 병합하여 최종 기여자 목록을 만든다.
fun <T> Response<List<T>>.bodyList(): List<T> {
return body() ?: emptyList()
}
Kotlin
복사
•
.body() ?: emptyList() 에 대한 중복 코드를 제거하기 위해 bodyList() 라는 확장 함수를 선언한다.
when (getSelectedVariant()) {
BLOCKING -> { // UI 스레드 차단
val users = loadContributorsBlocking(service, req)
updateResults(users, startTime)
}
}
Kotlin
복사
•
loadContributorsBlocking() 을 호출하는 loadContributors() 함수이다.
코드 설명
1.
getOrgReposCall() 과 getRepoContributorsCall() 은 모두 *Call 클래스의 인스턴스를 반환한다.
a.
이 시점에는 요청이 전송되지 않는다.
2.
Call.execute() 를 호출하여 요청을 실행한다.
a.
execute() 는 동기식 호출로 해당 스레드를 차단한다.
3.
응답을 받으면 결과는 logRepos() 및 logUsers() 함수를 호출하여 기록된다.
a.
HTTP 응답에 오류가 있으면 해당 오류도 여기서 기록된다.
4.
응답의 본문을 가져오고 필요한 데이터를 포함한 응답의 본문이 없으면 빈 리스트를 사용한다.
a.
오류가 발생할 경우 빈 리스트를 결과로 사용하며 해당 오류를 기록한다.
실행 결과
1770 [AWT-EventQueue-0] INFO Contributors - kotlin: loaded 40 repos
2025 [AWT-EventQueue-0] INFO Contributors - kotlin-examples: loaded 23 contributors
2229 [AWT-EventQueue-0] INFO Contributors - kotlin-koans: loaded 45 contributors
...
Kotlin
복사
•
각 줄의 첫 번째 항목은 프로그램이 시작된 이후 경과한 밀리초이다.
•
대괄호 안의 내용은 스레드 이름을 나타내며 로딩 요청이 호출된 스레드를 확인할 수 있다.
•
각 줄의 마지막 항목은 실제 메세지로 몇 개의 저장소 또는 기여자가 로드되었는지 보여준다.
•
이 로그 출력은 모든 결과가 메인 스레드에서 기록되었음을 나타낸다.
•
BLOCKING 옵션으로 코드를 실행하면 창이 로드가 끝날 때까지 멈추고 입력에 반응하지 않음을 볼 수 있다.
•
loadContributorsBlocking() 을 호출한 스레드는 UI 스레드이므로 요청은 동일한 스레드에서 실행되고 UI가 멈춘다.

콜백
•
Blocking 요청은 작동하지만 스레드를 차단하고 UI를 멈추게 만든다.
•
이를 피하기 위한 전통적인 접근 방식은 콜백을 사용하는 것이다.
•
연산이 완료된 직후에 호출되어야 하는 코드를 호출하는 대신 이를 별도의 콜백(종종 람다로 작성)으로 분리하여 호출자에게 전달하고 이후에 호출하도록 할 수 있다.
•
UI가 응답성을 유지하도록 하려면 전체 연산을 별도의 스레드로 이동시키거나 Blocking 호출 대신 콜백 API를 사용하도록 전환할 수 있다.
백그라운드 스레드 사용하기
thread {
loadContributorsBlocking(service, req)
}
Kotlin
복사
•
thread() 함수는 새로운 스레드를 시작하므로 전체 연산을 다른 스레드로 이동시킬 수 있다.
•
이제 모든 로딩 작업이 별도의 스레드로 이동하였으므로 메인 스레드는 자유로워져 다른 작업을 처리할 수 있다.

fun loadContributorsBackground(
service: GitHubService, req: RequestData,
updateResults: (List<User>) -> Unit
)
Kotlin
복사
•
loadContributorsBackground() 함수의 시그니처를 변경하여 모든 로딩이 완료된 후 호출할 updateResults() 콜백을 마지막 인자로 받는다.
•
이제 loadContributorsBackground() 가 호출될 때 updateResults() 호출은 즉시 뒤따라오지 않고 콜백 안에서 호출된다.
loadContributorsBackground(service, req) { users ->
SwingUtilities.invokeLater {
updateResults(users, startTime)
}
}
Kotlin
복사
•
SwingUtilities.invokeLater 를 호출함으로써 UI를 업데이트하는 updateResults() 호출이 메인 UI 스레드(AWT 이벤트 디스패치 스레드)에서 이루어지도록 보장한다.
•
그러나 BACKGROUND 옵션을 통해 기여자를 로드하려고 시도하면 목록이 업데이트되지만 아무런 변화가 없다.
콜백 API 사용
•
백그라운드 스레드는 여전히 최적의 자원 활용이 아니다.
•
모든 로딩 요청이 순차적으로 진행되며 로딩 결과를 기다리는 동안 스레드는 차단되지만 그 시간 동안 다른 작업을 처리할 수 있었다.
•
구체적으로 스레드는 이전 리포지토리의 결과를 기다리지 않고 다른 요청의 로딩을 시작할 수 있다.
•
각 리포지토리에 대한 데이터 처리는 로딩과 응답 처리의 두 부분으로 나누어져야 한다.
•
두 번째 응답 처리 부분은 콜백으로 분리되어야 한다.
•
그런 후에 각 리포지토리의 로딩은 이전 리포지토리의 결과가 도착하기 전에 시작될 수 있다. (해당 콜백이 호출되기 전)
fun loadContributorsCallbacks(
service: GitHubService, req: RequestData,
updateResults: (List<User>) -> Unit
) {
service.getOrgReposCall(req.org).onResponse { responseRepos -> // #1
logRepos(req, responseRepos)
val repos = responseRepos.bodyList()
val allUsers = mutableListOf<User>()
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers -> // #2
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
}
}
}
// TODO: 왜 이 코드가 작동하지 않을까요? 어떻게 수정해야 할까요?
updateResults(allUsers.aggregate())
}
Kotlin
복사
•
콜백 API를 사용하여 이를 달성할 수 있다.
•
Call.enqueue() 함수는 HTTP 요청을 시작하며 콜백을 인자로 받는다.
•
이 콜백에서 각 요청 후에 수행해야 할 작업을 지정해야 한다.
•
편의를 위해 이 코드는 동일한 파일에 선언된 onResponse() 확장 함수를 사용한다.
•
이 함수는 람다를 인자로 받으며 객체 표현 대신 사용된다.
•
응답을 처리하는 로직은 콜백으로 추출되었으며 각 람다는 #1과 #2에서 시작한다.
•
그러나 CALLBACKS 옵션을 통해 기여자를 로드하려고 시도하면 목록이 업데이트되지만 아무런 변화가 없다.
일시 중단 함수
// suspend 함수로 직접 결과 반환
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
suspend fun getOrgRepos(
@Path("org") org: String
): List<Repo>
}
// suspend 함수로 Response 결과 반환
interface GitHubService {
// getOrgReposCall & getRepoContributorsCall 선언부
@GET("orgs/{org}/repos?per_page=100")
suspend fun getOrgRepos(
@Path("org") org: String
): Response<List<Repo>>
@GET("repos/{owner}/{repo}/contributors?per_page=100")
suspend fun getRepoContributors(
@Path("owner") owner: String,
@Path("repo") repo: String
): Response<List<User>>
}
Kotlin
복사
•
susepnd 함수를 사용하여 동일한 로직을 구현할 수 있다.
•
suspend 함수를 사용하여 요청을 수행할 때 기본적으로 스레드는 차단되지 않는다.
•
Call<List<Repo>> 를 반환하는 대신 API 호출을 suspend 함수로 정의하여 결과를 직접 반환한다.
•
만약 결과가 실패하면 예외를 발생시키므로 직접 결과를 반환하는 대신 Response로 감싸진 결과를 반환할 수 있다.
•
이 경우 결과 본문이 제공되며 수동으로 오류를 확인할 수 있다.
코루틴
•
suspend 함수가 포함된 코드는 blocking 요청과 유사한 것처럼 보인다.
•
주요 차이점은 스레드를 차단하는 대신 코루틴이 일시 중지된다는 점이다.
block -> suspend
thread -> coroutine
Kotlin
복사
•
코루틴은 코드를 스레드에서 실행하는 것처럼 코루틴에서도 코드를 실행할 수 있기 때문에 종종 경량 스레드라고 불린다.
•
이전에 blocking되었던 작업들은 이제 코루틴을 중단시키는 방식으로 동작한다.
launch {
val users = loadContributorsSuspend(req)
updateResults(users, startTime)
}
Kotlin
복사
•
launch는 람다를 인수로 받는 라이브러리 함수이고 loadContributorsSuspend() 함수는 launch 안에서 호출된다.
•
여기서 launch는 데이터를 로드하고 결과를 표시하는 새로운 계산을 시작한다.
•
이 계산은 일시 중지할 수 있으며 네트워크 요청을 수행할 때 일시 중지되고 기반 스레드를 release한다.
•
네트워크 요청이 결과를 반환하면 계산이 다시 재개된다.
•
이런 방식으로 일시 중지할 수 있는 계산을 코루틴이라고 부른다.
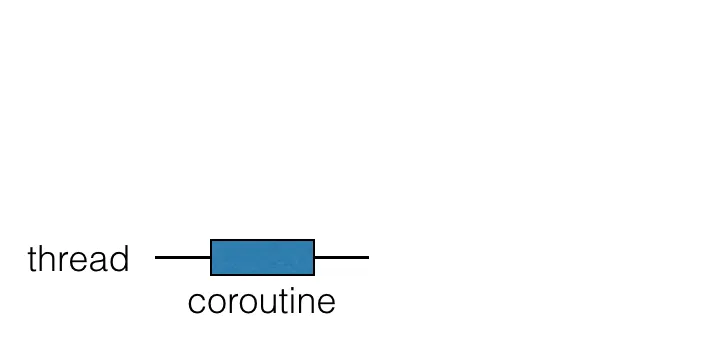
•
코루틴은 스레드 위에서 실행되며 일시 중지될 수 있다.
•
코루틴이 일시 중지되면 해당 계산이 중지되고 스레드에서 제거된 뒤 메모리에 저장된다.
•
그 동안 스레드는 다른 작업에 사용될 수 있다.
•
일시 중지된 코루틴 계산을 계속할 준비가 되면 해당 계산은 스레드로 돌아오지만 반드시 동일한 스레드는 아니다.
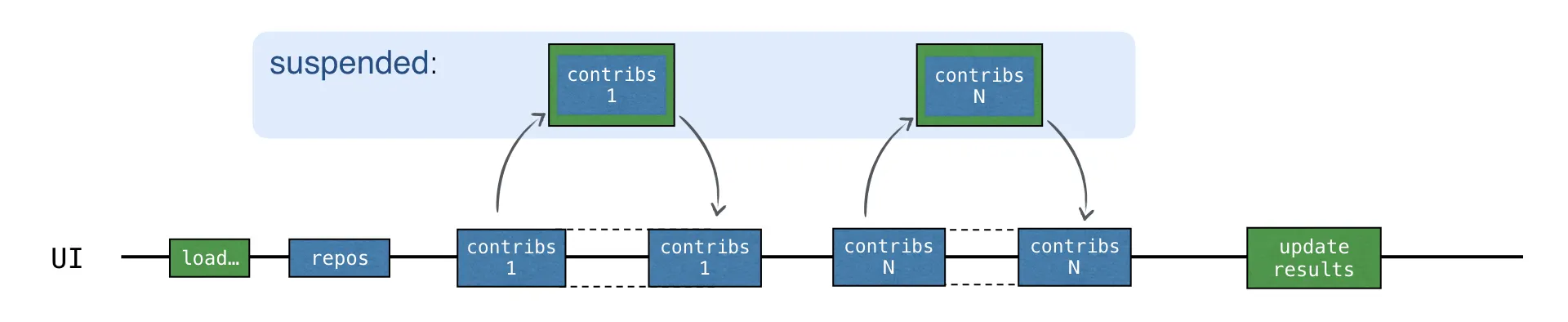
•
loadContributorsSuspend() 에서 각 기여자 요청은 이제 서스펜션 메커니즘을 사용하여 결과를 기다린다.
•
먼저 새로운 요청이 전송된 후 다음 응답을 기다리는 동안 launch 함수가 시작한 전체 기여자 로드 코루틴이 일시 중지된다.
•
응답이 수신된 후에 코루틴이 다시 재개되고 요청 일시 중지 응답을 기다리는 동안 스레드는 다른 작업에 사용될 수 있다.
•
모든 요청이 UI 스레드에서 이루어지고 있음에도 불구하고 UI는 반응성을 유지한다.
2538 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 30 repos
2729 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - ts2kt: loaded 11 contributors
3029 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin-koans: loaded 45 contributors
...
11252 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin-coroutines-workshop: loaded 1 contributors
Kotlin
복사
•
SUSPEND 옵션을 사용해 프로그램을 실행하면 모든 요청이 UI 스레드에서 처리되었다는 것을 로그에서 확인할 수 있다.
•
이제 스레드 이름에 코루틴 이름이 함께 표시된다.
•
suspend 함수는 스레드를 공정하게 다루고 기다리는 것 때문에 스레드를 차단하지 않는다.
•
하지만 아직까지는 이 방식이 동시성을 제공하는 것은 아니다.
동시성
•
코루틴은 스레드보다 자원을 훨씬 덜 소모한다.
•
비동기적으로 새로운 작업을 시작할 때마다 새로운 코루틴을 만들 수 있다.
•
새로운 코루틴을 시작하려면 launch, async, runBlocking과 같은 주요 코루틴 빌더를 사용할 수 있다.
•
다른 라이브러리에서는 추가적인 코루틴 빌더를 정의할 수도 있다.
async
•
async는 새로운 코루틴을 시작하고 launch의 Job을 확장한 제네릭 타입인 Deferred<Type> 객체를 반환한다.
•
이 때 Type은 람다식 내부의 마지막 표현식에 따라 결정된다.
•
Deferred는 다른 언어에서 Future나 Promise로 알려진 개념을 나타낸다.
•
이는 어떤 작업의 계산 결과를 가지고 있지만 최종 결과를 나중에 얻을 수 있다는 점에서 그 결과를 약속하는 역할을 한다.
•
코루틴 결과를 얻으려면 Deferred 인스턴스에서 await()을 호출할 수 있고 이 await()을 호출하는 코루틴은 결과를 기다리는 동안 중단된다.
•
Deffered 객체 목록이 있는 경우 awaitAll()을 호출하여 모든 결과를 기다릴 수 있다.
async와 launch의 주요 차이점
•
launch는 특정한 결과를 반환할 필요가 없는 작업을 시작할 때 사용된다는 점이다.
•
launch는 해당 코루틴을 나타내는 Job을 반환하며 Job.join()을 호출해 완료될 때까지 기다릴 수 있다.
runBlocking
import kotlinx.coroutines.*
fun main() = runBlocking {
val deferred: Deferred<Int> = async {
loadData()
}
println("waiting...")
println(deferred.await())
}
suspend fun loadData(): Int {
println("loading...")
delay(1000L)
println("loaded!")
return 42
}
Kotlin
복사
•
runBlocking은 일반 함수와 일시 중단 함수 또는 블로킹과 논블로킹 세계 사이의 다리 역할을 한다.
•
최상위 코루틴을 시작하는 어댑터로 사용되며 주로 main() 함수와 테스트에서 사용된다.
동시 실행 코루틴
import kotlinx.coroutines.*
fun main() = runBlocking {
val deferreds: List<Deferred<Int>> = (1..3).map {
async {
delay(1000L * it)
println("Loading $it")
it
}
}
val sum = deferreds.awaitAll().sum()
println("$sum")
}
Kotlin
복사
•
각 기여자 요청이 새로운 코루틴에서 시작되면 모든 요청은 비동기적으로 시작된다.
•
이전 요청의 결과를 받기 전에 새로운 요청을 보낼 수 있다.
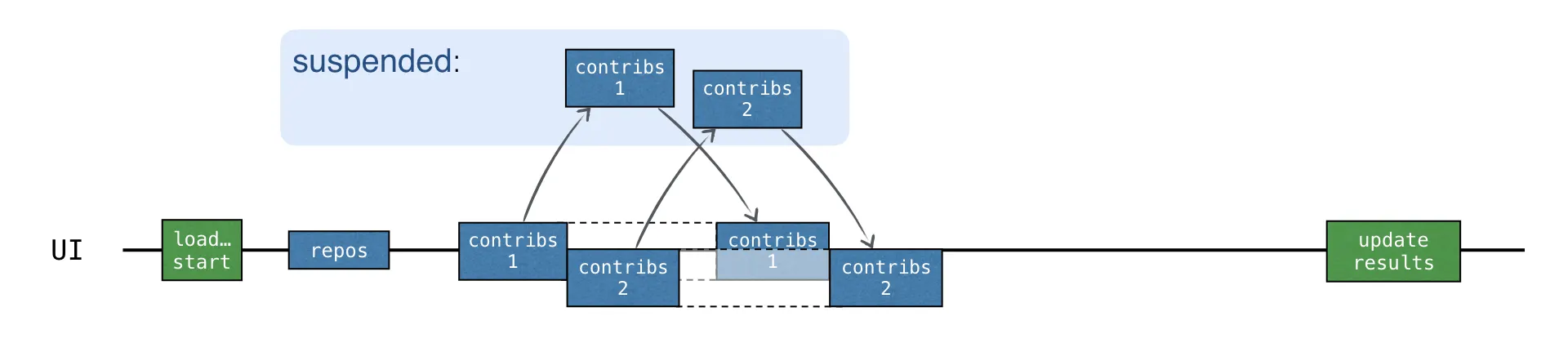
•
전체 로딩 시간은 CALLBACK 버전과 거의 동일하지만 콜백이 필요 없다.
•
또한 async는 코드에서 어떤 부분이 동시에 실행되는지를 명시적으로 나타낸다.
구조적 동시성
•
코루틴 스코프는 다양한 코루틴 간의 구조 및 부모-자식 관계를 담당한다.
•
일반적으로 새로운 코루틴은 스코프 내에서 시작해야 한다.
•
코루틴 컨텍스트는 코루틴 실행에 필요한 추가 정보를 저장하는데 예를 들어 코루틴의 사용자 지정 이름이나 코루틴이 스케줄될 스레드를 지정하는 디스패처와 같은 정보가 포함된다.
함수를 사용해서 CoroutineScope 생성
launch { /* this: CoroutineScope */ }
Kotlin
복사
•
launch, async, runBlocking 같은 함수가 새로운 코루틴을 시작할 때 자동으로 해당하는 스코프를 생성한다.
•
이 함수들은 모두 리시버가 있는 람다를 인수로 받으며 이때 리시버는 CoroutineScope 타입이다.
•
launch와 async는 CoroutineScope의 확장 함수로 선언되어 있으므로 호출할 때 암시적 또는 명시적 리시버를 항상 전달해야 한다.
•
runBlocking으로 시작된 코루틴은 유일한 예외로 runBlocking은 최상위 함수로 정의되어 있지만 이 함수는 현재 스레드를 차단하므로 주로 main() 함수나 테스트에서 브리지 함수로 사용된다.
•
runBlocking 내부에서 launch를 호출할 때는 암시적 리시버 타입인 CoroutineScope의 확장 함수로 호출된다. (명시적으로 this.launch라고 쓸 수도 있다.)
import kotlinx.coroutines.*
fun main() = runBlocking { /* this: CoroutineScope */
launch { /* ... */ }
// 동일한 표현:
this.launch { /* ... */ }
}
Kotlin
복사
•
이 예시에서 launch에 의해 시작된 중첩된 코루틴은 runBlocking에 의해 시작된 외부 코루틴의 자식이라고 볼 수 있다.
•
이 부모-자식 관계는 스코프를 통해 작동하며 자식 코루틴은 부모 코루틴에 해당하는 스코프에서 시작된다.
함수를 사용하지 않고 CoroutineScope 생성
•
새로운 스코프를 생성하면서 새로운 코루틴을 시작하지 않고도 CoroutineScope 함수를 사용할 수 있다.
•
외부 스코프에 접근할 수 없는 suspend 함수 내에서 구조적으로 새로운 코루틴을 시작하려면 새로운 코루틴 스코프를 생성할 수 있으며 이 스코프는 자동으로 호출된 외부 스코프의 자식이 된다.
•
GlobalScope.async 또는 GlobalScope.launch를 사용하여 글로벌 스코프에서 새로운 코루틴을 시작할 수도 있다.
•
이 경우 최상위 독립적인 코루틴이 생성된다.
구조적 동시성 메커니즘의 이점
•
스코프는 자식 코루틴의 수명을 관리하며 자식 코루틴의 수명은 스코프의 수명에 의해 결정된다.
•
만약 문제가 발생하거나 사용자가 작업을 취소하려 할 때 스코프는 자식 코루틴을 자동으로 취소할 수 있다.
•
스코프는 자동으로 모든 자식 코루틴이 완료될 때까지 기다린다. 따라서 스코프가 코루틴에 대응하는 경우 부모 코루틴은 그 안에서 시작된 모든 코루틴이 완료될 때까지 완료되지 않는다.
GlobalScope의 단점
•
GlobalScope.async를 사용할 때는 여러 코루틴을 작은 스코프로 묶는 구조가 없다.
•
글로벌 스코프에서 시작된 코루틴은 모두 독립적이며 그들의 수명은 어플리케이션 전체의 수명에 의해 제한된다.
•
글로벌 스코프에서 시작된 코루틴에 대한 참조를 저장하고 완료를 기다리거나 명시적으로 취소할 수 있지만 구조적 동시성처럼 자동으로 취소되지는 않는다.
CoroutineScope와 GlobalScope의 예제
•
CoroutineScope
suspend fun loadContributorsConcurrent(
service: GitHubService,
req: RequestData
): List<User> = coroutineScope {
// ...
async {
log("starting loading for ${repo.name}")
delay(3000)
// 로드
}
// ...
}
Kotlin
복사
◦
loadContributorsConcurrent() 함수에 3초의 딜레이를 추가한다.
◦
이 딜레이는 요청을 보내기 전에 코루틴을 시작한 후 취소할 수 있는 충분한 시간을 준다.
2896 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 40 repos
2901 [DefaultDispatcher-worker-2 @coroutine#4] INFO Contributors - starting loading for kotlin-koans
...
2909 [DefaultDispatcher-worker-5 @coroutine#36] INFO Contributors - starting loading for mpp-example
/* 'cancel' 클릭 */
/* 요청이 전송되지 않음 */
Kotlin
복사
◦
프로그램을 실행하고 CONCURRENT 옵션을 선택하여 기여자를 로드할 때 모든 요청이 시작된 후 취소 버튼을 클릭하면 모든 요청이 취소된다.
•
GlobalScope
suspend fun loadContributorsNotCancellable(
service: GitHubService,
req: RequestData
): List<User> {
// ...
GlobalScope.async {
log("starting loading for ${repo.name}")
// 로드
}
// ...
return deferreds.awaitAll().flatten().aggregate()
}
Kotlin
복사
◦
loadContributorsNotCancellable() 함수에서는 coroutineScope 생성을 제거하고 GlobalScope.async를 사용한다.
2570 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 30 repos
2579 [DefaultDispatcher-worker-1 @coroutine#4] INFO Contributors - starting loading for kotlin-koans
...
2586 [DefaultDispatcher-worker-6 @coroutine#36] INFO Contributors - starting loading for mpp-example
/* 'cancel' 클릭 */
/* 그러나 모든 요청이 여전히 전송됨: */
6402 [DefaultDispatcher-worker-5 @coroutine#4] INFO Contributors - kotlin-koans: loaded 45 contributors
...
9555 [DefaultDispatcher-worker-8 @coroutine#36] INFO Contributors - mpp-example: loaded 8 contributors
Kotlin
복사
◦
프로그램을 실행하고 NOT_CANCELLABLE 옵션을 선택하여 기여자를 로드할 때 취소 버튼을 클릭해도 모든 요청이 여전히 전송된다.
코루틴 취소
interface Contributors {
fun loadContributors() {
// ...
when (getSelectedVariant()) {
CONCURRENT -> {
launch {
val users = loadContributorsConcurrent(service, req)
updateResults(users, startTime)
}.setUpCancellation() // #1
}
}
}
private fun Job.setUpCancellation() {
val loadingJob = this // #2
// 'cancel' 버튼이 클릭되면 로딩 작업 취소:
val listener = ActionListener {
loadingJob.cancel() // #3
updateLoadingStatus(CANCELED)
}
// 'cancel' 버튼에 리스너 추가:
addCancelListener(listener)
// 로딩 작업 완료 후 상태를 업데이트하고 리스너 제거
}
}
Kotlin
복사
•
Cancel 버튼이 클릭되면 로딩 코루틴이 명시적으로 취소되며 자식 코루틴도 자동으로 취소된다.
•
launch 함수는 Job 인스턴스를 반환하고 이 인스턴스는 데이터를 불러오고 업데이트하는 로딩 코루틴의 참조를 가진다.
•
Job 인스턴스를 리시버로 전달하여 setUpCancellation() 확장 함수를 호출할 수 있다.
val job = launch { }
job.setUpCancellation()
Kotlin
복사
•
또한 가독성을 위해 위처럼 명시적으로 함수 내부에서 setUpCancellation() 함수의 수신자를 새로운 Job 변수로 참조할 수 있다.
외부 스코프 컨텍스트 사용
•
주어진 스코프 내에서 새로운 코루틴을 시작할 때 동일한 컨텍스트에서 실행되도록 보장하기가 더 쉽다.
•
또한 필요에 따라 컨텍스트를 쉽게 교체할 수 있다.
launch(Dispatchers.Default) { // 외부 스코프
val users = loadContributorsConcurrent(service, req)
// ...
}
Kotlin
복사
•
CoroutineScope 또는 코루틴 빌더에 의해 생성된 새로운 스코프는 항상 외부 스코프의 컨텍스트를 상속 받는다.
•
이 경우 외부 스코프는 loadContributorsConcurrent() 함수가 호출된 스코프이다.
suspend fun loadContributorsConcurrent(
service: GitHubService, req: RequestData
): List<User> = coroutineScope {
// 이 스코프는 외부 스코프의 컨텍스트를 상속받습니다.
// ...
async { // 상속된 컨텍스트로 시작된 중첩 코루틴
// ...
}
// ...
}
Kotlin
복사
•
모든 중첩된 코루틴은 자동으로 상속된 컨텍스트로 시작된다.
•
디스패처는 이 컨텍스트의 일부이다.
•
그렇기 때문에 async로 시작된 모든 코루틴은 기본 디스패처의 컨텍스트로 시작된다.
•
구조적 동시성을 사용하면 최상위 코루틴을 생성할 때 주요 컨텍스트 요소(디스패처 등)를 한 번 지정할 수 있으며 중첩된 코루틴은 필요할 때만 이를 수정하여 컨텍스트를 상속받는다.

일반적으로 최상위 코루틴에 대해 CoroutineDispatchers.Main 을 기본적으로 사용하고 다른 스레드에서 코드를 실행해야 할 때 명시적으로 다른 디스패처를 지정하는 것이 일반적인 관행이다.
진행 상황 표시
suspend fun loadContributorsProgress(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) {
// 데이터 로드
// 중간 상태에서 `updateResults()` 호출
}
Kotlin
복사
•
UI를 업데이트하는 로직을 콜백으로 전달해야 한다.
•
이 콜백은 각 중간 상태에서 호출된다.
•
호출 시점에 콜백을 전달하여 메인 스레드에서 PROGRESS 옵션에 따라 결과를 업데이트하도록 한다.
launch(Dispatchers.Default) {
loadContributorsProgress(service, req) { users, completed ->
withContext(Dispatchers.Main) {
updateResults(users, startTime, completed)
}
}
}
Kotlin
복사
•
loadContributorsProgress() 함수에서는 updateResults() 파라미터가 suspend로 선언되어 있다.
•
이 때문에 해당 람다 인자 안에서 suspend 함수인 withContext를 호출해야 한다.
•
updateResults() 콜백은 로딩이 완료되었고 결과가 최종적인지 여부를 지정하는 Boolean 파라미터를 추가 인자로 받는다.
연속성 vs 동시성
•
updateResults() 콜백은 각 요청이 완료된 후 호출된다.
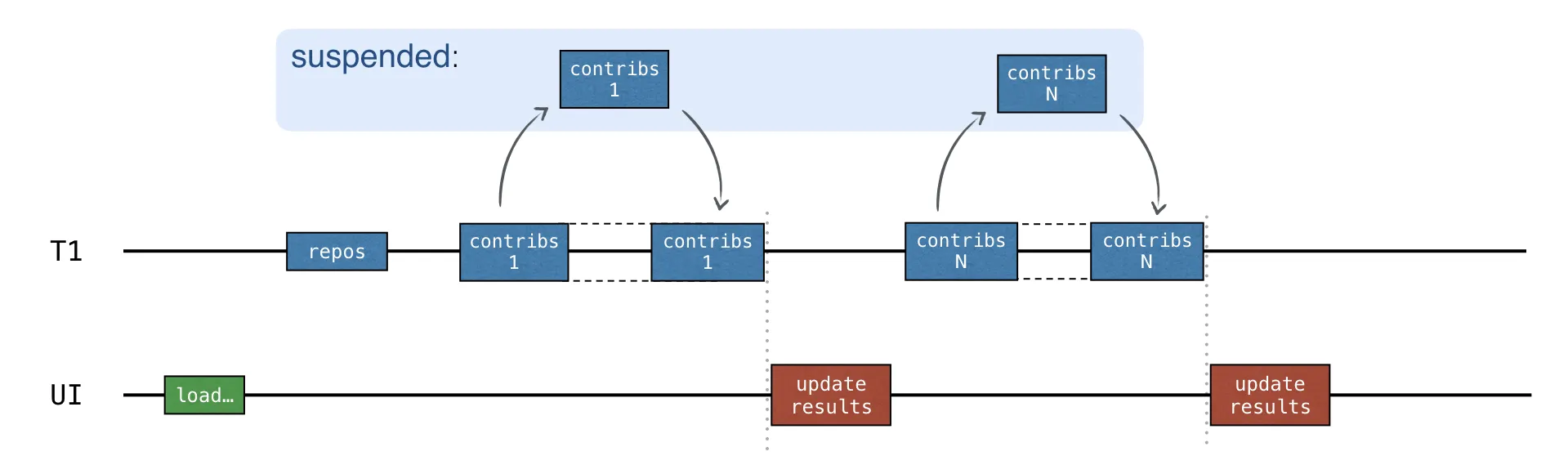
•
이 코드에는 동시성이 포함되지 않는다.
•
순차적이므로 동기화가 필요하지 않다.
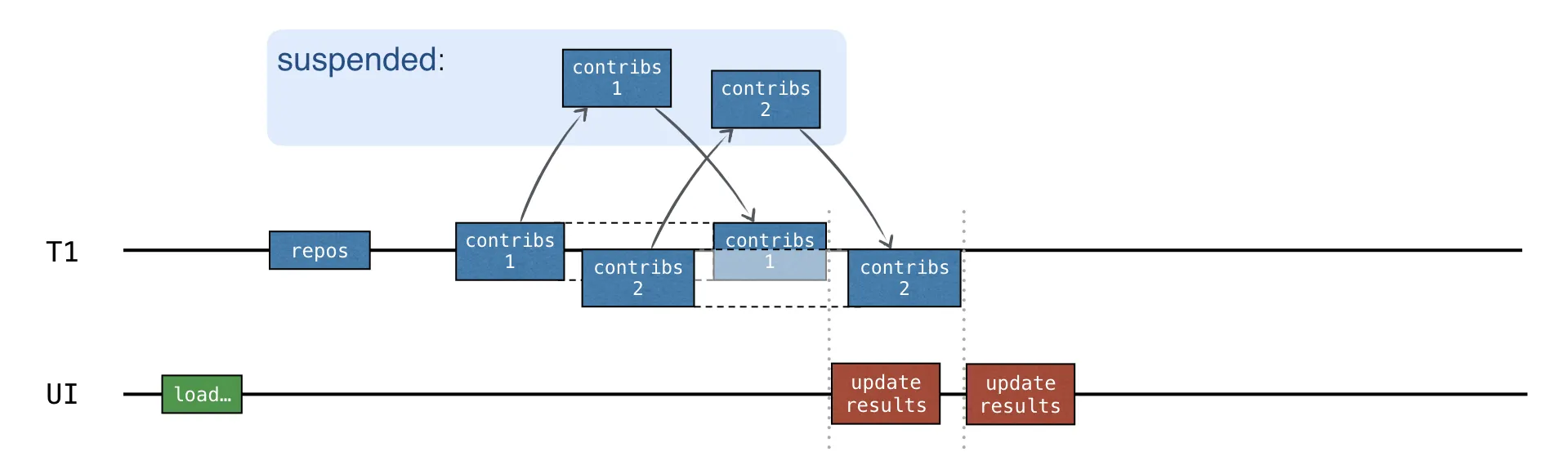
•
가장 좋은 선택은 동시에 요청을 보내고 각 저장소에 대한 응답을 받은 후 중간 결과를 업데이트하는 것이다.
•
동시성을 추가하려면 channels를 사용하라.
채널
•
공유된 가변 상태를 사용하는 코드 작성은 매우 어렵고 오류 발생 가능성이 크다. (콜백처럼)
•
더 간단한 방법은 공통 가변 상태를 사용하지 않고 통신을 통해 정보를 공유하는 것이다.
•
코루틴은 채널을 통해 서로 통신할 수 있다.

•
채널은 코루틴 사이에서 데이터를 전달하는 기본 통신 수단이다.
•
하나의 코루틴이 채널에 정보를 보내고 다른 코루틴이 그 정보를 받을 수 있다.
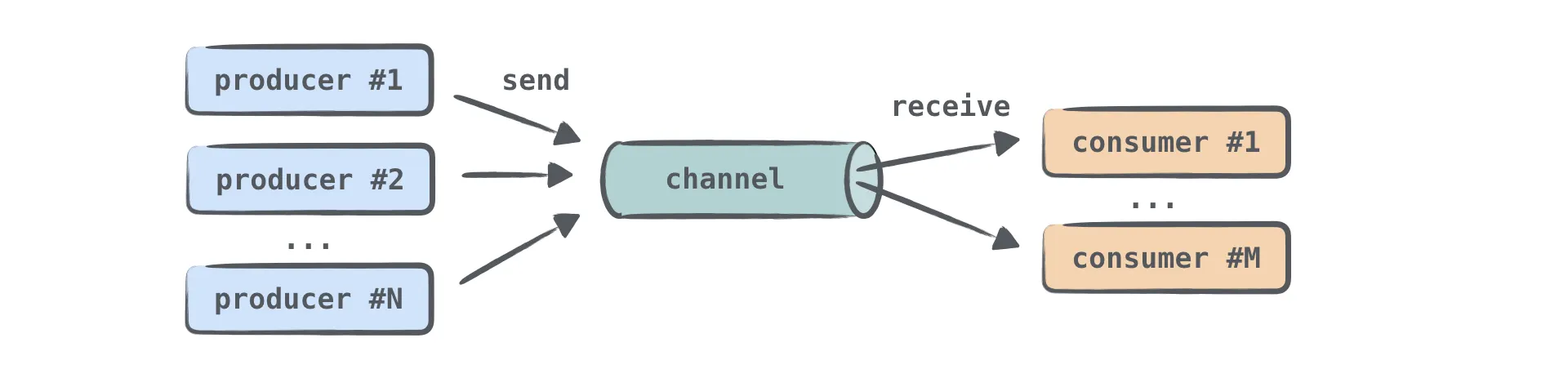
•
정보를 보내는(생산하는) 코루틴을 보통 생산자(producer)라고 부르며 정보를 받는(소비하는) 코루틴을 소비자(consumer)라고 부른다.
•
하나 이상의 코루틴이 동일한 채널에 정보를 보낼 수 있으며 하나 이상의 코루틴이 동일한 채널에서 데이터를 받을 수 있다.
여러 코루틴과 채널 사용
•
여러 코루틴이 동일한 채널에서 정보를 받을 때 각 요소는 한 번만 소비되고 처리된 후에는 채널에서 제거된다.
•
채널은 요소들이 한쪽 끝에 추가되고 다른 한쪽 끝에서 소비되는 큐(queue)와 비슷하다.
•
그러나 중요한 차이점은 채널의 send() 및 receive() 연산은 일시 중단될 수 있다는 것이다.
•
이는 채널이 비어 있거나 가득 차 있을 때 발생한다.
•
채널이 가득 차면 채널의 크기에 상한이 있는 경우 send() 연산이 일시 중지될 수 있다.
Channel 인터페이스
interface SendChannel<in E> {
suspend fun send(element: E)
fun close(): Boolean
}
interface ReceiveChannel<out E> {
suspend fun receive(): E
}
interface Channel<E> : SendChannel<E>, ReceiveChannel<E>
Kotlin
복사
•
Channel은 SendChannel, ReceiveChannel 그리고 Channel 세 가지 인터페이스로 표현된다.
•
Channel은 앞의 두 인터페이스를 확장한 형태이다.
•
보통 SendChannel 인스턴스를 생산자에게 전달하여 생산자만 채널에 정보를 보낼 수 있게 하고 ReceiveChannel 인스턴스를 소비자에게 전달하여 소비자만 채널에서 정보를 받을 수 있게 한다.
•
send와 receive 메서드는 모두 suspend 함수로 선언되어 있다.
•
생산자는 더 이상 보낼 요소가 없을 때 채널을 닫을 수 있다.
Channel 종류
내부적으로 얼마나 많은 요소를 저장할 수 있는지와 send() 호출이 일시 중단될 수 있는지 여부에 따라 다르다.
모든 채널 유형에서 receive() 호출은 비슷하게 작동하는데 채널이 비어 있지 않으면 요소를 받고 그렇지 않으면 일시 중단된다.
•
무제한 채널

◦
큐와 가장 유사한 구조이다.
◦
생산자는 이 채널에 무제한으로 요소를 보낼 수 있으며 메모리가 부족해질 때까지 채널은 계속해서 확장된다.
◦
send() 호출은 절대 일시 중단되지 않으며 메모리가 부족해지면 OutOfMemoryException이 발생할 수 있다.
◦
소비자가 비어 있는 채널에서 요소를 받으려 하면 일시 중단된다.
•
버퍼링된 채널

◦
채널의 크기는 지정된 수치로 제한된다.
◦
생산자는 이 채널에 지정된 크기까지 요소를 보낼 수 있으며 그 이후에는 send() 호출이 일시 중단된다.
◦
내부적으로 모든 요소가 저장된다.
•
랑데부 채널

◦
버퍼가 없는 채널이며 버퍼 크기가 0인 버퍼링된 채널과 동일하다.
◦
하나의 함수(send() 또는 receive())는 다른 함수가 호출될 때까지 항상 일시 중단된다.
◦
send() 함수가 호출되고 receive() 함수가 준비되지 않은 경우 send()는 일시 중단된다.
◦
반대로 receive() 함수가 호출되고 채널이 비어 있으면 receive() 호출도 일시 중단된다.
•
합성 채널

◦
새로 보낸 요소가 이전 요소를 덮어씌운다.
◦
따라서 수신자는 항상 가장 최근에 보낸 요소만 받는다.
◦
send() 호출은 절대 일시 중단되지 않는다.
Channel 코드 예제
val rendezvousChannel = Channel<String>()
val bufferedChannel = Channel<String>(10)
val conflatedChannel = Channel<String>(CONFLATED)
val unlimitedChannel = Channel<String>(UNLIMITED)
Kotlin
복사
•
기본적으로 랑데부 채널이 생성된다.
suspend fun loadContributorsChannels(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) = coroutineScope {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
val channel = Channel<List<User>>()
for (repo in repos) {
launch {
val users = service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
channel.send(users)
}
}
var allUsers = emptyList<User>()
repeat(repos.size) {
val users = channel.receive()
allUsers = (allUsers + users).aggregate()
updateResults(allUsers, it == repos.lastIndex)
}
}
Kotlin
복사
•
모든 기여자 목록의 중간 상태를 저장할 allUsers 변수를 만들고 채널에서 수신한 각 새로운 목록을 추가한다.
•
결과를 집계한 후 updateResults() 콜백을 사용하여 상태를 업데이트한다.
•
데이터를 받지 못했을 때 receive() 호출이 일시 중단되고 이 경우 기여자 로딩 코루틴 전체가 일시 중단된다.
코루틴 테스트
•
실행 시간을 비교하는 코루틴 테스트의 두 가지 문제점이 있다.
1.
테스트가 너무 오래걸린다.
2.
실행되는 정확한 시간을 신뢰할 수 없다.
•
테스트 지연이 예상대로 동작하는지 확인하기 위해 가상 시간을 사용하는 특별한 테스트 디스패처를 사용하라.
•
이 디스패처는 시작 시점부터 경과한 가상 시간을 추적하며 코루틴을 즉시 실행한다.
•
이 디스패처에서 코루틴을 실행하면 지연이 즉시 반환되고 가상 시간이 진행된다.
@Test
fun testDelayInSuspend() = runTest {
val realStartTime = System.currentTimeMillis()
val virtualStartTime = currentTime
foo()
println("${System.currentTimeMillis() - realStartTime} ms") // ~ 6 ms
println("${currentTime - virtualStartTime} ms") // 1000 ms
}
suspend fun foo() {
delay(1000) // 자동으로 지연 없이 진행
println("foo") // foo() 호출 시 즉시 실행
}
Kotlin
복사
•
테스트에서 이 메커니즘을 사용하려면 runBlocking 호출을 runTest로 교체하라.
•
runTest는 TestScope에 대한 확장 람다를 인수로 받는다.
•
이 특별한 스코프 내에서 suspend 함수 안에서 delay를 호출하면 지연이 실제 시간을 지연시키는 대신 가상 시간을 증가시킨다.
•
현재 가상 시간을 TestScope의 currentTime 속성을 사용하여 확인할 수 있다.
@Test
fun testDelayInLaunch() = runTest {
val realStartTime = System.currentTimeMillis()
val virtualStartTime = currentTime
bar()
println("${System.currentTimeMillis() - realStartTime} ms") // ~ 11 ms
println("${currentTime - virtualStartTime} ms") // 1000 ms
}
suspend fun bar() = coroutineScope {
launch {
delay(1000) // 자동으로 지연 없이 진행
println("bar") // bar() 호출 시 즉시 실행
}
}
Kotlin
복사
•
자식 코루틴에서 가상 지연 효과를 제대로 보려면 모든 자식 코루틴을 TestDispatcher로 시작하라.
•
이 디스패처는 다른 TestScope에서 자동으로 상속된다.